
相互推薦システムを活用したユーザーと企業の双方の嗜好を考慮した推薦 | Wantedly Engineer Blog
こんにちは、ウォンテッドリーでデータサイエンティストをしている林 (@python_walker) です。ウォンテッドリーでは、テクノロジーの力で人と仕事の適材適所を実現するために推薦システムの...
https://www.wantedly.com/companies/wantedly/post_articles/903172
こんにちは。ウォンテッドリーのデータサイエンティストの市村 (@chimuichimu1) です。ウォンテッドリーでは、テクノロジーの力で人と仕事の最適なマッチングを実現するために、推薦システムの開発に取り組んでいます。この記事では、Wantedly Visit で活用されている「相互推薦システム」という技術に注目し、その概要や近年の研究動向を紹介したいと思います。
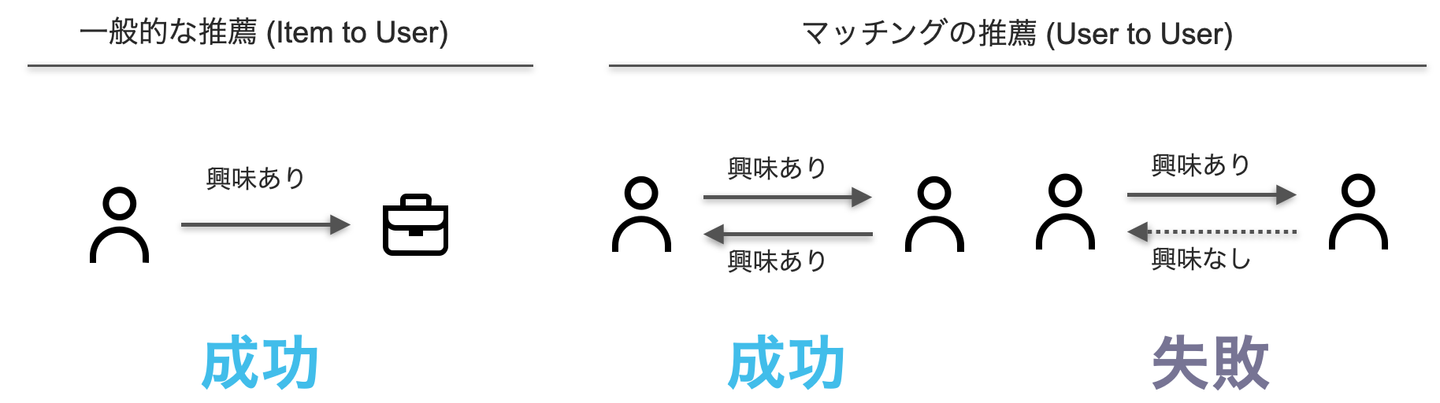
相互推薦システムとは一言で言うと「サービス内のユーザーを互いに推薦し合う」システムのことです。一般的な推薦システムでは、ユーザーからアイテムへの嗜好に基づいて、ユーザーに対してアイテムを推薦します。一方で相互推薦システムでは、推薦されるユーザーと推薦を受け取るユーザーの両方の嗜好に基づき、ユーザーに対してユーザーを推薦します。
相互推薦システムのユースケースとしては、ジョブマッチングやオンラインのデーティングサービスといったものが挙げられます。ウォンテッドリーが提供する人と仕事のマッチング体験は前者のユースケースに該当し、実際に Wantedly Visit では相互推薦システムが活用されています。Wantedly Visit への導入や成果についての詳細は、以下の記事で紹介されています。興味がある方は、ぜひこちらもご覧ください。
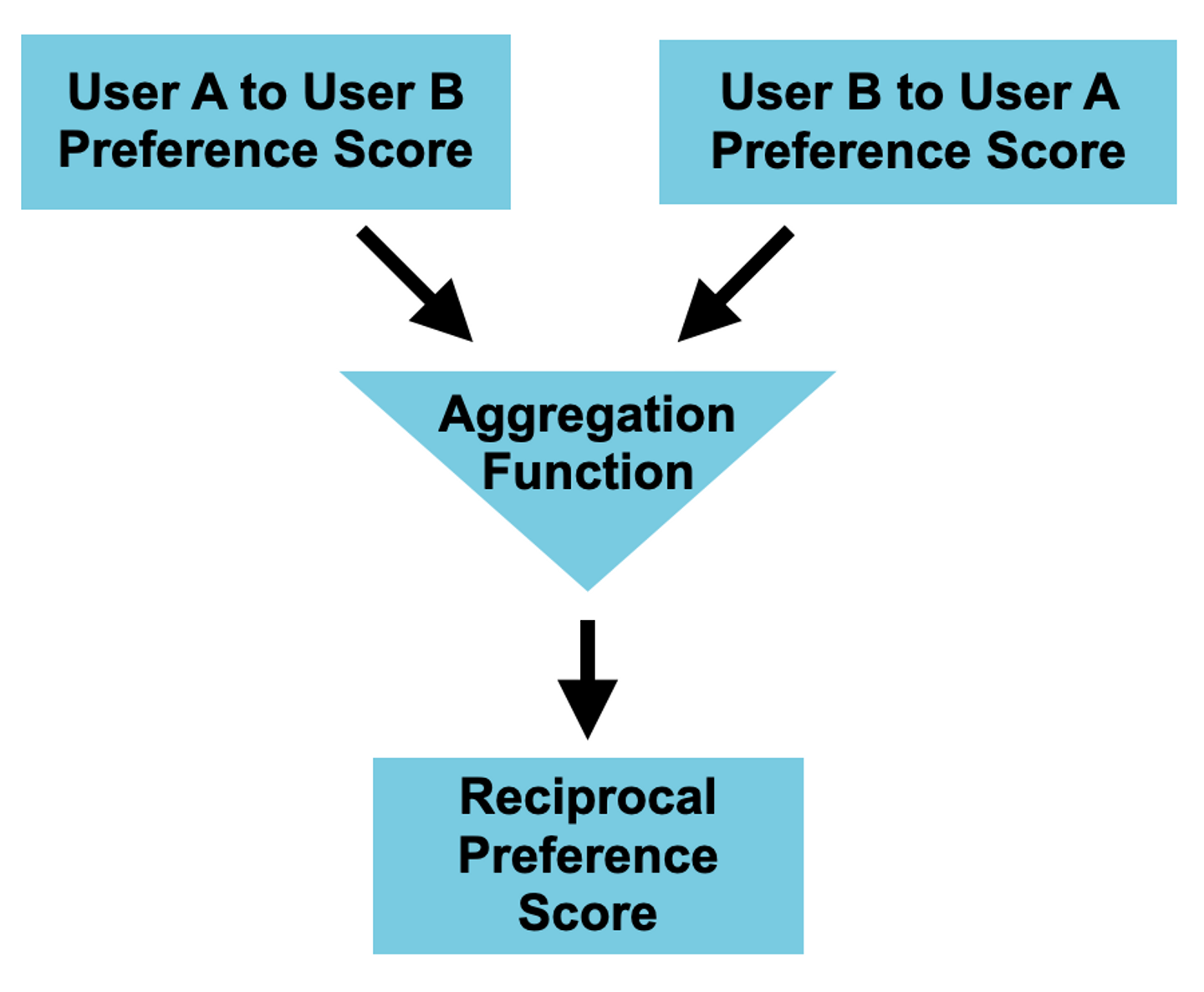
相互推薦システムを実現するアーキテクチャは、一般的に以下の3つのコンポーネントから成ります。
各方向の嗜好を予測するコンポーネントは、アイテムをユーザーに推薦する一般的な推薦システムで使われる推薦手法(Matrix Factorization など)が使用されます。嗜好スコアを集約する部分では、前のステップで生成された2つのスコアを何らかの方法で集約します。集約されたスコアは、双方向の嗜好を取り入れた「マッチ度」を表現するスコアであり、このスコアに基づいてユーザー A あるいは B に対する推薦を作成します。
アイテムをユーザーに推薦する一般的な推薦システムと比較して、相互推薦システムにはいくつかの特徴があります。ここでは相互推薦システムに関する論文 (Pizzato et al. (2010), Palomares et al. (2021)) からいくつかの特徴を抜粋し解説します。
アイテムをユーザーに推薦する一般的な推薦システムにおいては、そのユーザーがそのアイテムを気に入りさえすれば推薦は成功と言えます。一方で相互推薦システムでは、推薦を受けたユーザー A が推薦対象のユーザー B を気に入ったとしても、逆にユーザー B はユーザー A に興味がないかもしれません。このようなケースでは、ユーザー A がユーザー B に対して好意を送ったとしても、最終的にマッチングするのは難しいでしょう。このように相互推薦システムの推薦が成功するためには、双方向の嗜好が成り立つ必要があります。
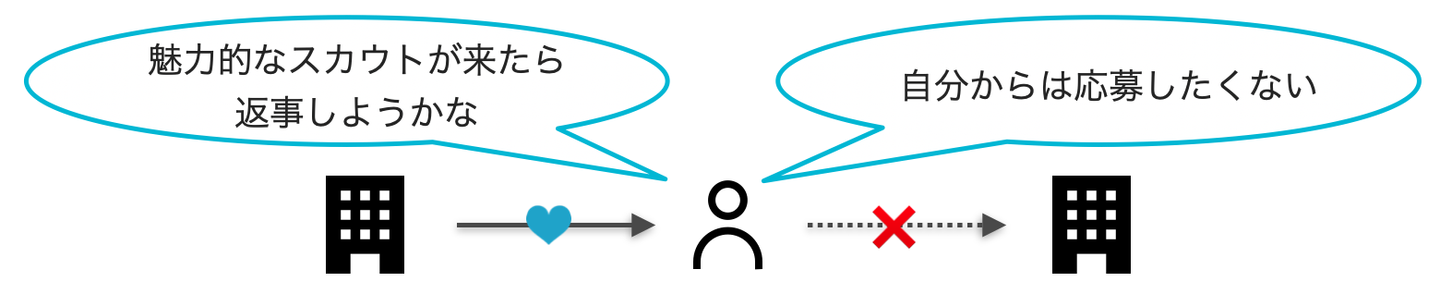
相互推薦システムが扱うサービスにおいては、ユーザーは他のユーザーからの「好意」を受け取ります。ここでいう好意とは、ジョブマッチングのケースでは企業から求職者へのスカウトであったり、求職者から企業への応募にあたります。ユーザーは受け取った好意すべてに対応できるわけではなく、ユーザーのリソースの上限(=キャパシティ)の範囲内で対応することになります。例えば求職者が100社からスカウトを受け取ったとしても、すべての企業と面談をするのは現実的でなく、実際に面談できるのはせいぜい数十社程度でしょう。
相互推薦を行う上でユーザーのキャパシティを考慮することは、ユーザーの体験悪化を防いだりプラットフォーム全体での利益を最大化するという観点で重要です。この特徴に起因する技術的課題や研究動向は、後続の「推薦が偏る問題への対処」の章でより詳細に紹介します。
一般的な推薦システムが扱うサービスでは、ユーザーはサービスを利用する目的を達成するために、購買やコンテンツ視聴といった行動を能動的にとる傾向があります。一方で相互推薦システムが扱うマッチングのサービスにおいては、能動的に行動を起こすユーザーもいれば、相手からの好意が来るのを待つ受動的なユーザーもいます。
受動的なユーザーは適切なユーザーに発見されてそのユーザーから好意を受け取らない限り、マッチングなどのサービス利用の目的を達成することができません。受動的なユーザーの存在を考慮した上で、行動ログが溜まりにくい受動的なユーザーの嗜好をいかに捉えるかを工夫したり、適切な推薦のアーキテクチャを検討したりすることが重要になります。
相互推薦システムでは、ユーザーは推薦を受け取る側になることもあれば、一般的な推薦システムにおけるアイテムのように推薦をされる側になることもあります。この特性によりユーザーは、自身が他のユーザーに認知され興味を持ってもらうために、プロフィールや自身の興味といった情報を積極的に提示する傾向があります。
ユーザーから明示的に提示される情報は、ユーザーの嗜好を推薦に取り入れて活用する上で有用です。ただしそれらの情報には、ユーザーが他のユーザーからより良く見られたいという思いから、事実とは異なる情報が含まれる可能性があることに注意が必要です。
相互推薦システムが適用されるドメインの特性上、ユーザーの行動特性という観点で一般的な推薦システムとは異なる点があります。例えばジョブマッチングのケースを考えると、求職者は転職という目的が達成されるとそのサービス内では二度と活動しない、または次にまた行動を起こすまで長い期間がかかる、ということが想像されます。このユーザーの行動特性は、複数の商品を何度も買うような e コマースにおける推薦システムで扱うものとは全く異なるものとなります。
ユーザーの行動履歴はユーザーの嗜好を暗黙的に表現する情報として推薦に活用することが可能です。しかし相互推薦システムにおいては、そのような行動履歴の情報が手に入りにくい(=スパース性がある)ということを考慮した上で設計を行う必要があります。このトピックに関する技術的課題や研究動向については、後続の「マッチングのスパース性への対処」の章でより詳細に紹介します。
ここからは相互推薦システムが抱える技術的課題と、それらの課題に対して近年の研究ではどのようなアプローチが取られているか?を紹介します。
相互推薦システムにおいて、推薦される機会が特定のユーザーに偏ることで問題が引き起こされる可能性があります。大勢のユーザーに推薦されるユーザーは、多くのユーザーから好意を受け取ることになります。しかし、前述の相互推薦システムの特徴の章で触れた通り、ユーザーには好意に対応するためのリソースの上限(=キャパシティ)があるため、キャパシティを上回る好意には対応することができません。一方で全く推薦されないユーザーは誰からも好意を受け取れず、マッチングという目的がいつまで経っても実現できない、という体験をしてしまうかもしれません。
ユーザー体験の悪化やユーザー間での不公平性といった問題に加え、推薦の偏りはサービスが生み出す利益にも問題を与えます。キャパシティを上回ってしまった好意が、もし適切なユーザーに配分されていれば、その分サービス全体でのマッチングの数が増えるかもしれません。このように相互推薦システムの推薦の偏りを是正することは、ユーザー体験の向上・プラットフォームの公平性・サービスが生み出す利益といった複数の観点において重要です。
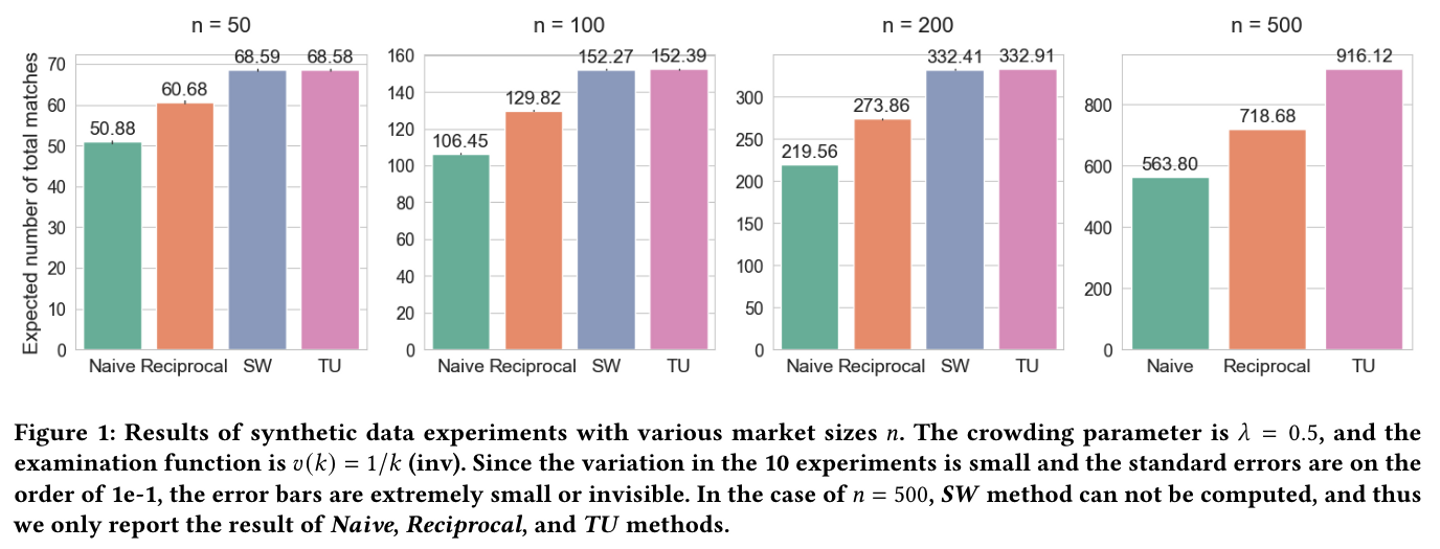
この推薦の偏りという問題を解消するために「マッチング理論」に基づく手法が提案されています。マッチング理論は経済学の分野などで発展してきた理論で、人と人、あるいは物を、それぞれの嗜好とキャパシティを考慮した上でどのように最適にペアリングするかを分析するものです。マッチング理論を相互推薦に応用した研究として、例えば Su et al. (2022) はプラットフォームにおけるマッチング総数の期待値(social welfare)を近似的に表現する目的関数を定義したうえ、この関数を最大化するランキング計算のアプローチを提案をしています。
また Tomita et al.(2023) では、移転効用つきマッチングモデル (Matching with Transferable Utility) というマッチング理論に基づく相互推薦手法が提案されています。この研究では従来の手法が抱えていた、実サービスのデータ規模を想定したときに計算量が大きくなりすぎるという課題や、アイテムがリスト化されたランキングをユーザーがどの範囲まで注意を向けるか?を表現する関数 (examination function) の仮定が必要であるという課題を解決し、より実用的な相互推薦手法を提案しています。
関連研究
相互推薦システムのアーキテクチャの章で紹介した通り、相互推薦システムのアーキテクチャには各方向の嗜好予測の結果を集約するコンポーネントがあります。このコンポーネントによって、それぞれの嗜好予測の結果を融合し、相互の嗜好のマッチ度合いを示す単一のスコアを生成します。それぞれの嗜好を如何に集約するかは自明ではなく、様々な方法が考えられます。
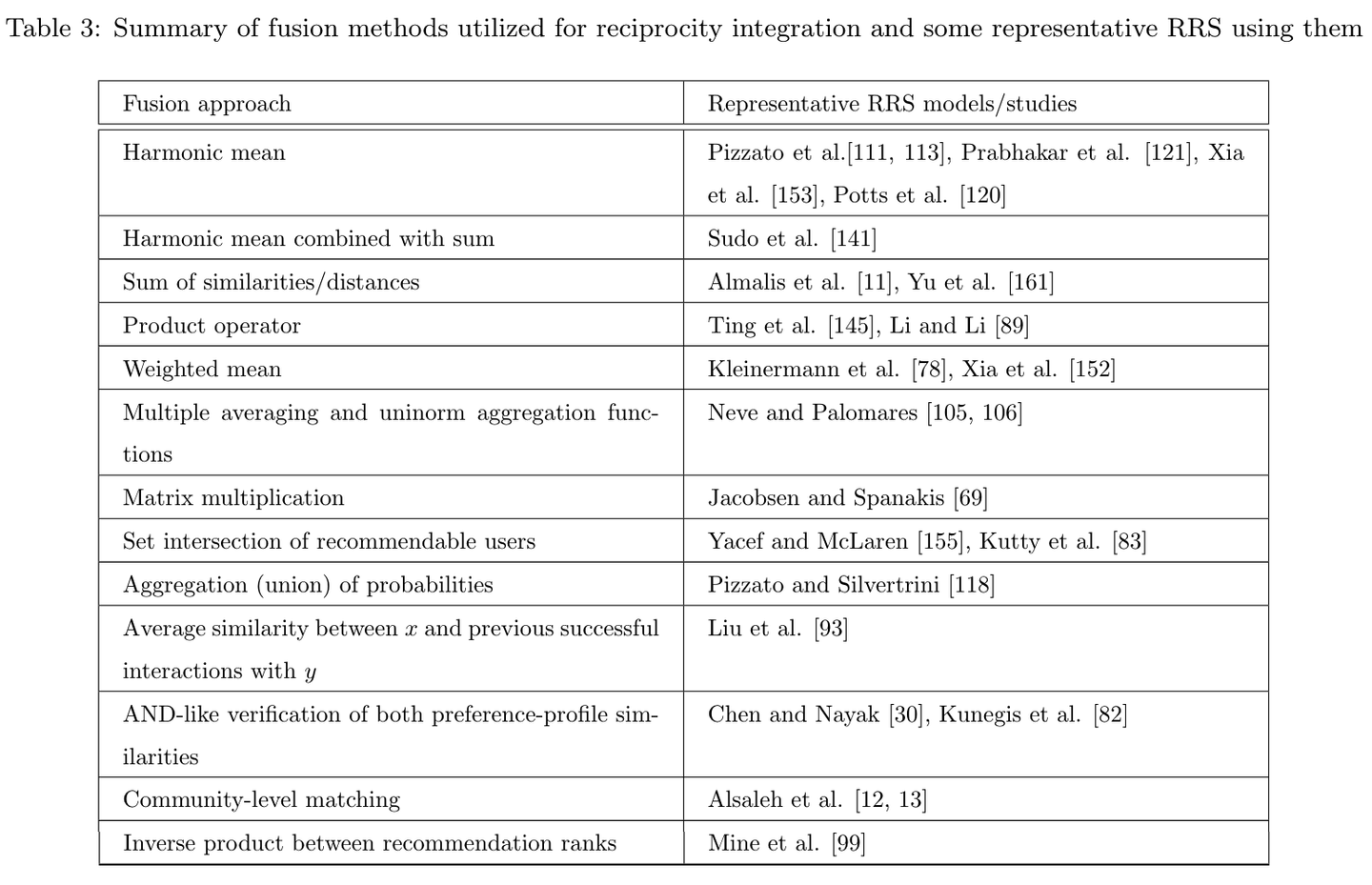
以下の表は、Palomares et al. (2021)で紹介されている、相互推薦に関する研究で取られているアプローチがまとめられた表を抜粋したものです。各研究それぞれで様々なアプローチが取られているという現状がわかります。
Palomares et al. (2021) では集約を行う関数として、調和平均を選択することの合理性が述べられています。調和平均には片方のスコアが低い場合、集約したスコアも低くなるという特徴があります。比較として算術平均を考えると、算術平均は片方のスコアが低くてももう一方のスコアが高ければ、集約後のスコアは調和平均に比べ高く出ます。マッチングが成立するにはお互いがある程度十分な興味があることが必要と考えられるため、調和平均の持つ性質がマッチングという事象をより良く表現すると言えるケースがありそうです。実際に異なる集約関数で比較実験を行っている Neve and Palomares (2019) では、協調フィルタリングベースの相互推薦において、調和平均のパフォーマンスが算術平均を上回るという実験結果が得られています。
また、上記に挙げたような単一の集約関数を用いた方法以外のアプローチの例として、Kleinermann et al. (2018) は推薦を受ける側の嗜好と推薦される側の嗜好の重みを、ユーザーごとに最適化する手法を提案しています。
関連研究
次に紹介するのは、ユーザーの嗜好を表現するインタラクションデータがスパースであるという課題です。前述の相互推薦システムの特徴の章で触れた通り、相互推薦システムが適用されるマッチングというドメインでは、ユーザーがサービスを利用する目的(例えば転職や結婚など)が達成されるとサービスを離脱する傾向があります。この結果「ユーザーのマッチング」という嗜好を捉える上で重要な情報が得られづらく、嗜好の予測が難しいという課題があります。
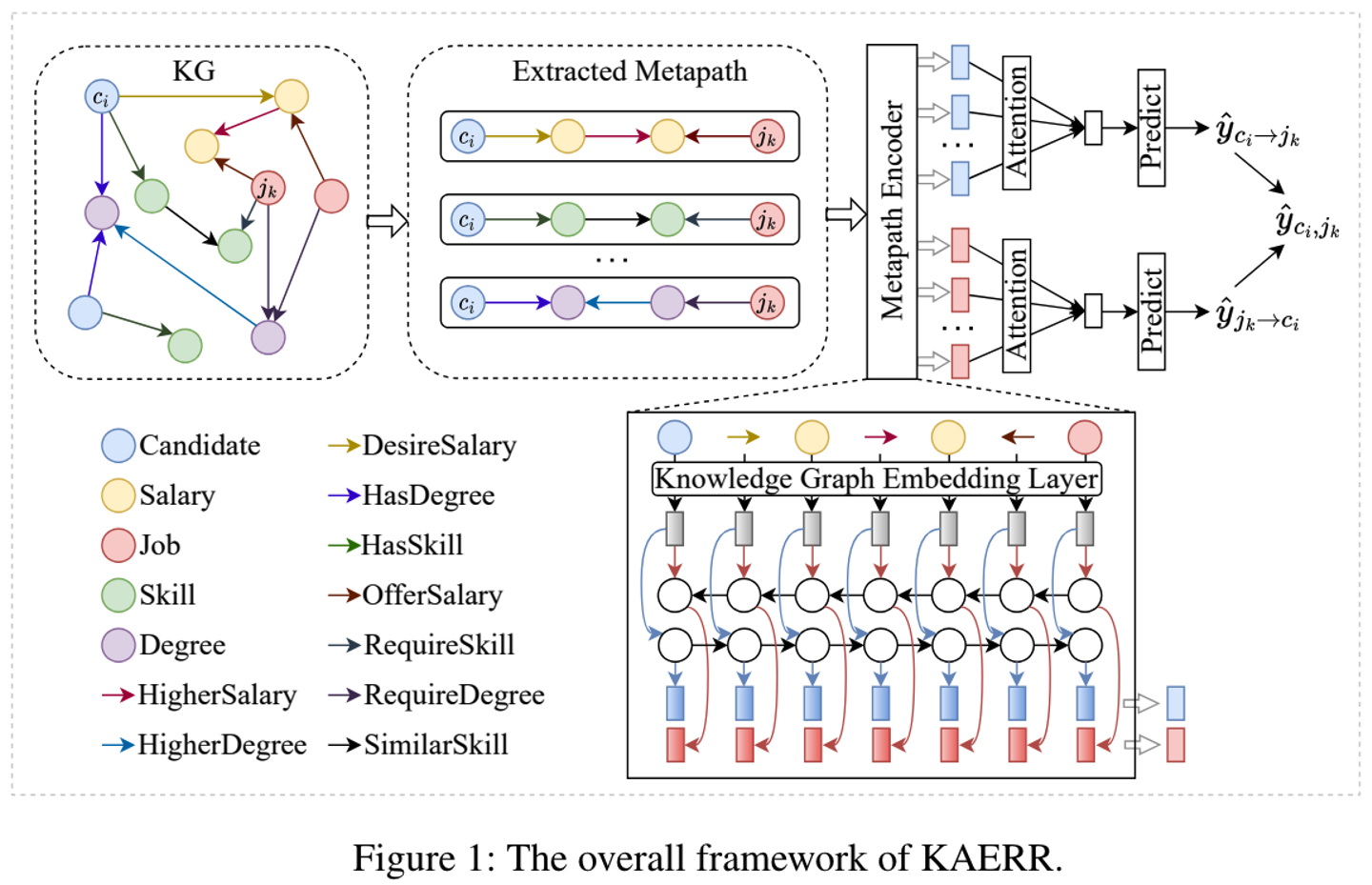
この課題を解決するための一つの方向性として、インタラクションではなくコンテンツのデータを有効に活用することでユーザーの嗜好を読み取り推薦に活かすというものがあります。例えば Lai et al. (2024) では、知識グラフからメタパスを抽出しモデリングに用いることで、コンテンツの情報を組み込んで相互の嗜好予測を行うアプローチを提案しています。知識グラフとは仕事・求職者・スキルといったような異なるエンティティとそれらの関係をグラフとして表現したもので、メタパスとはグラフにおける特定の関係性(例:求職者が望む給料が、仕事が提示する給料を上回る)を表現するノードとエッジのパスを意味します。
この研究のポイントは、同一の知識グラフからそれぞれのメタパスを別々にモデリングしている点です。例えば「候補者は PhD を取得しており、学位以上を求める求人の募集要件を上回る」というメタパスを考えた場合、求人を出す側からするとその情報はポジティブな意味を持ちますが、候補者からすると自身のレベルに合わないというネガティブな意味を持つかもしれません。このように同じ知識グラフで表される関係であっても、候補者側と募集側とでその情報の持つ意味が変わるため、別々のメタパスとして分けてモデリングを行います。
さらにこの研究では学習に用いる損失関数に「マッチしたか否か?」という双方向の嗜好の情報だけでなく「求人に応募したが断られた」「候補者をスカウトしたが断られた」というような片方向の嗜好の情報を組み込むことで、限られたインタラクションデータを最大限に活用するアプローチをとっています。以上の工夫により、従来の相互推薦の手法と比較して高い精度を実現しています。
関連研究
この記事では、相互推薦システムの概要を説明した上で、相互推薦システムが抱える技術的課題とそれに対する研究の動向を紹介しました。ウォンテッドリーが開発する Wantedly Visit も同様の技術的課題を抱えているため、こうした研究の内容をインプットにしてより良いマッチングの実現に活かしていきたいです。
また、私たちと一緒に、推薦システムという技術活用を促進して人と会社の理想的なマッチングを追求するデータサイエンティスト・機械学習エンジニアの仲間を探しています。少しでも私たちの取り組みに興味を持っていただけたら、以下の募集から「話を聞きに行きたい」ボタンをクリックしてください!
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)

