/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)
Wantedly, Inc.では一緒に働く仲間を募集しています
- バックエンド / リーダー候補
- PdM
- Webエンジニア(シニア)
- 他19件の職種
- 開発
- ビジネス
こんにちは、Wantedly の 2023 年サマーインターンに参加した Ran350 です。今回のインターンでは 3 週間 DX (Developer Experience) squadに所属し、「Wantedly における Ruby コードベースへの型システムの導入」をテーマに取り組んでいました。本記事では、その仮説検証の過程や調査記録を紹介します。
本議論はまだ検討段階です。Rubyの型システム導入という議題には多くの不確定要素がありますが、その中で可能な範囲で暫定結論を出したいという議論になります。また、本議論では多くの future work も残しています。そのため、新たな発見があれば結論も容易に変わりうると考えています。また、本調査で検証していない選択肢も多くありますが、単に時間的制約のためにできなかったというだけであり、必ずしも避けるべき選択肢というわけではないという認識です。
結論には推測も含まれています。時間的制約の中ですべてを明らかにするのは不可能なので、「事実、検証、推測、仮説」を混ぜ合わせながら議論しています。これらは本記事内でできるだけ分けて書くつもりではありますが、参考にする際はご注意ください。
あくまで Wantedly での導入という前提での議論です。 一般論としての議論ではありません。
Ruby3.0 から RBS が導入され、Ruby でも型システムの潮流が高まっています。Wantedlyでは数年前から検討こそしているものの運用に至ってはいません。同じ動的型付けのJavaScriptはというと、TypeScript の型システムにより素晴らしい開発者体験が得られる世界になりました。Wantedlyでも数年前に JavaScript → TypeScript への移行が行われました。型システムという夢を Ruby でもう一度見たい。という思いはありつつも WantedlyでRubyの型システムの運用に至っていないのはなぜか。それは、型システム導入によるメリット・デメリットの大きさが不明瞭で、メリットがデメリットを上回るかどうかを判断できず、意思決定ができないからというのが大きな理由です。ということで、意思決定の材料となる情報を調査しました。
「型システム導入によるメリットがデメリットの閾値を超えるような運用方針」を見つけ出すことを目的とします。
そのために、型システム導入における様々な選択肢を できるだけ漏れなくダブりなく洗い出し、
調査・検証しながら各選択肢の特徴を確認します。
型システム導入の恩恵として以下を検討し、型検査による事前のバグ検出に着目しました。
型システムによる弊害として以下を検討しました。
型検査手法として以下が挙げられ、Steep での検証を試みました。
RBSの作成方法として以下の選択肢の中から TypeProf、rbs prototypeについて検証を行いました。
型検査による恩恵を定量的に推定しました。
検討段階という前提で、暫定結論として以下の運用方針を提案しました。
本議論の目的は「型システム導入によるメリットがデメリットの閾値を超えるような運用方針を見つけること」だと先述しました。そのため、運用方針を評価する上でどんなメリット・デメリットがあるかを最初に整理しておきます。そのうえで、どのメリデメを重視して手法の評価を行うかも決めておきます。
型システム導入によるメリットとしては、以下が考えられます。
「ドキュメントとしての役割」に関して、型アノテーションを用いてプログラマの意図を説明することができるので、型自身がドキュメントの役割を果たします。
「IDEのコーディング支援の強化」に関して、例えば、RubyMine は標準でもコーディング支援を提供していますが、RBSへの対応により強力なコーディング支援機能もサポートしています。
ただ、型システム導入による最も大きい恩恵は「型検査による事前のバグ検出」だと感じたので、この仮定を基に以降の検証を進めていきます。そう感じているだけで他の項目も検討の余地があるので future work としておきます。また、テストが型検査の競合になるか?という疑問に関して、すべてをテストできれば良いですが、理想的なテストカバレッジは現実的には難しいところです。
型システム導入によるデメリットとしては、以下が考えられます。
ここでは、最も重要でありボトルネックになるのは「型付け作業にかかる労力」だと仮定します。その他の可能性に関しても検討の余地があるので、future workとします。
型システム導入による恩恵として「型検査による事前のバグ検出」、弊害として「型付け作業にかかる労力」をについて着目すると述べました。これらの恩恵と弊害の大きさを推定するために、次のような問いに答える必要がでてきました。
時間的制約のある中で、不確定要素が膨大にあるのですべてを丁寧に調査・検証することはできません。したがって、少しの上手い実験と検証結果の掛け算で巨大な問題に一定の答えを出すことが、今回の仮説検証には求められます。
その上で、前節で紹介した「型システム導入による恩恵-弊害を評価するために知りたいこと」を明らかにするために、いくつかの検討方針案を考えてみました。
このうち「過去に発見された型起因のバグに対して型検査してみる」案を採用することにしました。理由としては、「型検査による事前のバグ検出」と「型付け作業にかかる労力」の両方を同時に検証できそうということ、型検査してみてエラーになる/ならないの2値で判断できること、そもそも型検査では防げないバグはどれくらいあったのかも検証できそうということなど、色々検証できそうだから〜という理由です。
「過去に発見された型起因のバグに対して型検査してみる」検証方法を採用することにしたので、まず Wantedly の GitHub リポジトリ内から型起因のバグに関連する Issue を探してみました。
調査方法としては、GitHub Code Search を用いて、Wantedly のメインリポジトリと post-mortems 用リポジトリから「型 fix」のようなキーワードで雑に検索してみました。
結果としては、16 件が発見されました。型起因のバグのうちのごく一部ではありますが、サンプルとしては有用だと思います。さらにサンプルを特徴別に分類してみました。
「型変換ミス」は、型変換が必要な箇所でしていなかったり、不適切な型に変換しているというパターンです。例えば、Symbol 型 の category に対して category.classify だが category.to_s.classify とすべきだったという事例がありました。また .to_s や .to_jsonをつければよいという単純なパターンもあれば、以下のような一見わかりずらいパターンもありました。
license_over_status_by_product = {} # Hash インスタンスを定義
# 正しい:HashのvalueにHashを指定
license_over_status_by_product[product] = { excess_license_count: status.excess_license_count }
# 誤り:Hashのvalueに独自classのインスタンスを指定
license_over_status_by_product[product] = status # 独自で定義したclassのインスタンス
# license_over_status_by_product[product] に代入された値は、後に ActiveJob からシリアライズされる。
# ActiveJob でシリアライズ可能な class は Hash や Array などあらかじめ決まって、独自定義したクラスは不可。
# ActiveJob でシリアライズできないclassをシリアライズしようとすると、ActiveJob::SerializationError
# 参考:https://edgeapi.rubyonrails.org/classes/ActiveJob/SerializationError.html
# 💥 上記原因によりランタイムで ActiveJob::SerializationError が発生してしまった「引数の指定ミス」は、例えば以下のようなパターンです。
# 正しい:第1引数にエラーが発生したクラス名を指定する必要がある
HBW.notify(
"UnsubscribableUserMailer",
"ここにエラーメッセージ",
# 誤り:第1引数のエラーが発生したクラス名を指定し忘れてしまった
HBW.notify(
"ここにエラーメッセージ",
# 💥 ランタイムで ArgumentError が発生してしまった「return式評価の見落とし」は、例えば以下のようなパターンです。
def insert( ... )
...
begin
Rails.logger.info table.insert(record)
# Rails.logger.info の結果が返るが、本当は table.insert() の返り値を意図していた
# 💥 本メソッドの利用側で意図しない挙動が発生してしまった
resue => e
raise ...
end
endSteepなどの静的型検査で防げるかという疑問について考察しておきます。型変換ミス、引数の指定ミス、return式評価の見落とし、例外時の返り値型の不考慮、存在しないメソッド呼び出しについては期待できると考えます。一方で、ランタイム型チェッカー、API のリクエスト/レスポンスの不整合に関しては、静的型検査の責務外のため難しいと考えています。
検証を行うに当たり、どんな(静的)型検査CLIツールが存在するかを調査しました。
Diamondback Ruby(DRuby)は、2009年に開発された初期の型システムおよび型検査ツールです。型推論 ##% で始まるコードコメントを用いて型アノテーションをつけることもできるそうです。
##% "+" : (String) -> String
def +(p0); endSolargraph は、Microsoft の LSP を通じて intellisense 機能を提供する Ruby の gemで、YARD記法 のコードコメントを解析して型検査する機能も提供しているようです。現在は、RBSもサポートするよう進められているみたいです(RBS Support · Issue #464 · castwide/solargraph)。Wantedlyのコードベースにおいて YARD 記法でのコメントも存在するので、YARD記法のコメントを追加していき Solargrapで型検査するという運用も候補としてありそうです。
Sorbet は、Stripe によって開発された静的型チェッカー 兼 ランタイム型システムです。2021年時点では Wantedly で RBI で型定義を用いてSorbetで型検査する方法も検討していました。現在も Sorbat という選択肢は十分検討の余地があると考えています。
Wantedly のコードベースに適用するのにより良い型チェッカーは Sorbet だと考えました。
理由としては、やはり一回の型チェックの速さが Sorbet のほうが圧倒的に速かった点が一つあります。
Ruby の型チェッカーの比較 | Wantedly Engineer Blog
Steep は、Ruby 3.0で導入されたRBS (Ruby Signature) 言語を使用して、Rubyのコードに静的型チェックを追加するためのツールです。
どの選択肢も検討の余地があると考えています。ただ、RBS が Ruby 3.0 から標準となったことで将来的にRBS周りのエコシステムが充実してくるだろうという予測も踏まえ、今回は RBSベースの型検査ツールとして代表的な Steep での導入から検討していきます。
Rails プロジェクト
Ruby ファイル
Gem
Rails が提供するクラスの型定義 と ユーザーが定義したモデルクラスの型定義を生成する機能を提供してくれる gem です。
rbs prototype は RubyのコードなどからRBSの型定義のプロトタイプを自動生成するためのツールです。rbs prototype rb コマンドおよび rbs prototype runtime での動作検証を行います。その名の通り型定義のプロトタイプを吐き出すので、生成されるほとんどの型は untyped になります。
事前調査で発見した、以下の過去の型起因のバグをサンプルとして検証していきます。
# 引数 category は Symbolを想定している
def self.resolve(user, target, category)
# 誤り: Symbol class に classify メソッドはない
"NotificationDb::Content::#{category.classify}".camelize.constantize.new(user, target)
# 正しい: String に変換
"NotificationDb::Content::#{category.to_s.classify}".camelize.constantize.new(user, target)
endrbs prototype rb で rbs を生成してみます。
$ rbs prototype rb app/services/user_service.rb
class UserService
中略
def self.resolve: (untyped user, untyped target, untyped category) -> untyped
end引数や返り値はすべて untyped ですが生成されました。引数に型エラーが出る最小の型付けをしてみます。
- def self.resolve: (中略, untyped category) -> untyped
+ def self.resolve: (中略, Symbol category) -> untypedSteepfile で 型検査レベルをdefaultに設定してみます。
configure_code_diagnostics(D::Ruby.default) steep checkしてみると、無事型エラーになりました。
$ bundle exec steep check app/services/user_service.rb
app/services/user_service.rb:29:41: [error]
Type::Symbol` does not have method `classify` Diagnostic ID: Ruby: : NoMethod
"NotificationDb::Content::#{category.classify}".camelize.constantize.new(user, target)
Detected 4 problems from 1 filerbs prototype rb はソースコードを静的に解析して型定義を吐き出すツールと紹介しました。一方で、メタプログラミングを多用する Ruby だと、ランタイムでメソッドを定義する〜みたいなユースケースでは rbs prototype rb では認識することができません。一方で、rbs prototype runtime はランタイムでの型情報を基に型定義を生成してくれます。Rails プロジェクトに対して rsb prototype runtime で型定義を生成する方法については以下の記事で検証されています。
TypeProf は、解析対象のプログラムを実行してランタイムでの型推論しながらしてくれます。事前調査で発見された過去の型起因のバグを対象に、TypeProf で型付けしてみます。
$ bundle exec rbs prototype rb lib/huntr/pubsub/project_subscriber/worker_job.rbmodule Huntr がないとのこと。ネストしたモジュールを仕様するとき、上位のモジュールが定義されている必要があるとのことでした。
module Huntr::Pubsub
class ProjectSubscriber
中略したがって、 上位のmoduleのrbsも生成した上で再度挑戦してみると上手く生成されました。生成された型定義を見てみると、同一ファイル内で宣言されたclassやメソッドについてはうまく型推論されていそうということがわかりました。
orthoses は、RubyコードからRBSを生成するためのフレームワークです。詳しくは以下記事で詳しく解説されていました。
また、orhoses をベースに、orthoses-rails や orthoses-yard などいくつかの派生ツールも作成されているようです。
orthoses 関連ツールも検討の余地がありそうだったので future work としておきます。
今回の検証で、TypeProfがuntypedを吐いたメソッドへ型定義をするのにかかった作業時間は、1メソッドあたり平均 約 30 分ほどでした。プリミティブな型だと数秒ですが、依存するクラスやgemがある場合に時間がかかった印象です。Wantedly メインシステムのコードベースでは 約1.7万のメソッドが定義されています。そのため、上達していくほど短くなるとはいえ地道にすべてのメソッドを追加していくとなると、数千時間かかりそうです。
型検査による恩恵を評価するために、型検査で防ぐ余地のあった型起因のバグはどの程度あるかを推定していきます。統計情報が不足していて正確な推定は困難ではありますが、ランダムよりかはマシな値を求めることを目標とします。
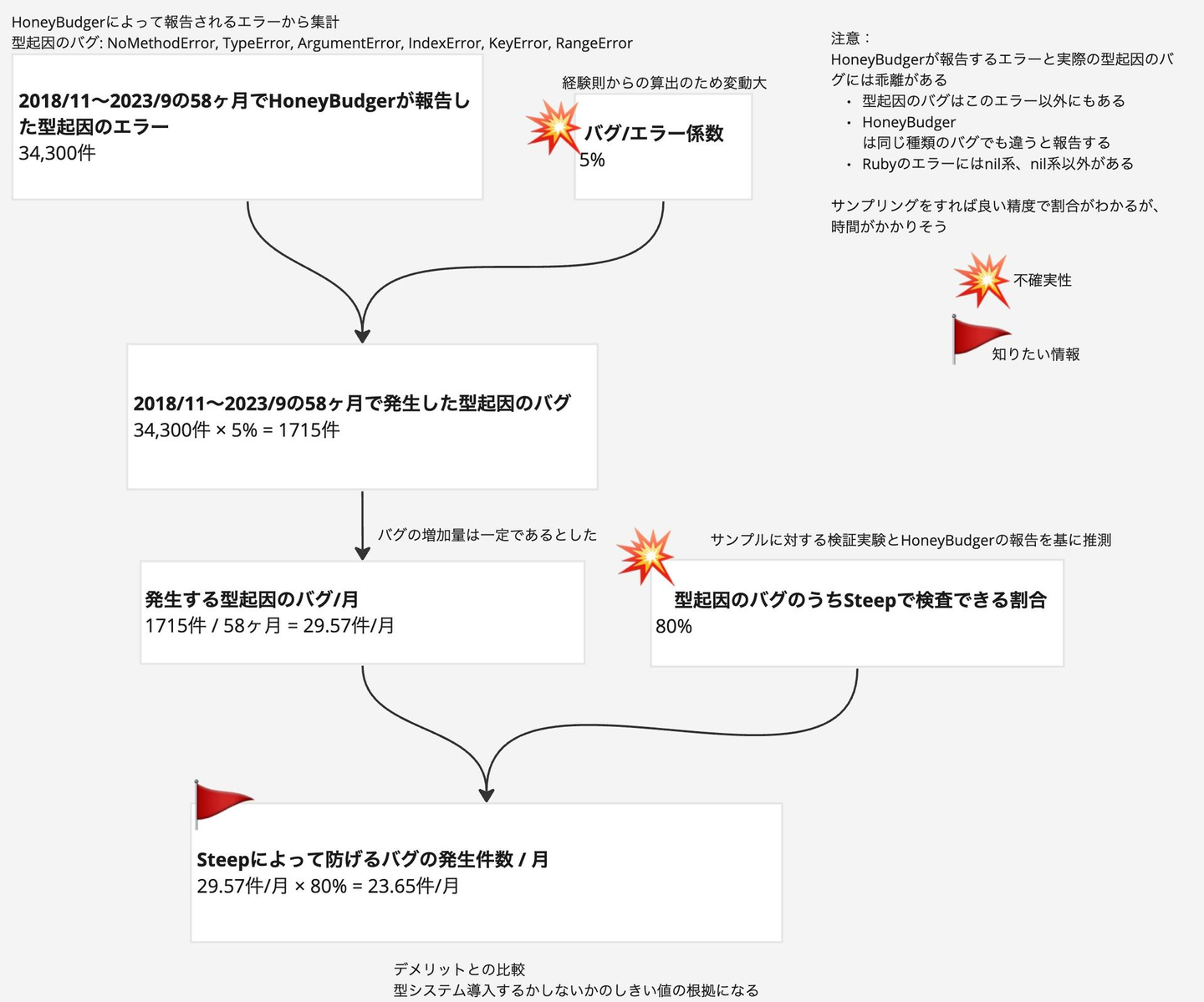
代表的な型起因のバグとして、NoMethodError, TypeError, ArgumentError, IndexError, KeyError, RangeError をピックアップしました。これらをキーワードに、HoneyBudger のエラーログを検索しまし、その結果を基に推定します。かなり無理やりなフェルミ推定ですが、以下の図ような流れで計算しました。結果としては、現実的には 一月あたり2桁代の型起因のランタイムエラーを型検査によって防げそうだと推定しました。
RBSをどのファイルから追加していくかという点について検討します。以下の選択肢が考えられます。
「他のclassに依存するclassから型付けする」選択肢が現状最も良いと判断しています。理由としては、検証したバグの 2/3 が gem の rbs なくても検査できたこと、型エラーを出せなかったものも後から追加しても労力が増加しなさそうだろうということ、などがあります。gem の型定義の追加に注力するよりも、ドメインに注力するほうが効果が高いのではと予想しています。
今後用検討とした選択肢も多くあり、検証結果に基づかない推測に基づく項目もあります。という前提で暫定の運用方針を考えました。考案した内容を Wantedly のバックエンドチームに提案しました。
RBS 周りのエコシステムはこれからもっと発展の余地があると感じています。例えば、RBS に対応しているgem(rbs_gem_collection を参照)は今後より増えていく可能性があると思います。し、RBS の型としての表現力もTypeScript までとは言わないまでも発展の可能性があると考えています。そんな進化の様子を追いながら運用する必要がありそうです。
TypeProf + 手書き での追加が好ましいと考えています。理由としては、検証結果から、ファイル内での推論ができたこと、型定義が増えるほど推論精度が上がる見込みがあることなどが挙げられます。また、上位の名前空間がある場合(module A::B の場合 A)のための rbs ファイルを作る必要もあるが、ファイル生成 した上で型はuntyped のままにしておくのであれば労力的に大変ではないだろうという考えです。
また、追加順序は「RBSの追加順序の検討」で議論した理由から「他のclassに依存するclassから型付けする」のが良いと考えています。
基本的には rbs_gem_collection から取得します。ない場合は、TypeProf で生成し、エラーが出る場合は手書きで修正する方針です。プロジェクト内で管理する想定ですが、運用がうまくいけば社内 gem_rbs_collection に移動させる選択肢もありそうです。また、gem_rbs_collection に commit する選択肢も考えられますが、リードタイムの長さが懸念されるためにしない方針です。
Steep で型検査を行います。型検査レベルに関しては、最初は default から運用してみて必要に応じて厳しくする方針。検証結果から、default で想定のエラーがでてくれたということを参考にしています。
CI 時に型検査し、型エラーがでたらCIを落とすようにします。また、VSCode での開発の場合は 拡張機能の Ruby TypeProf のインストールを推奨します。
型システム導入の恩恵として以下を検討し、型検査による事前のバグ検出に着目しました。
型システムによる弊害として以下を検討しました。
型検査手法として以下が挙げられ、Steep での検証を試みました。
RBSの作成方法として以下の選択肢の中から TypeProf、rbs prototypeについて検証を行いました。
型検査による恩恵を定量的に推定しました。
検討段階という前提で、暫定結論として以下の運用方針を提案しました。
今回のインターンでは、型システム導入するとどれくらいの恩恵があるかや、どんな運用方針があるかを考える という非常に曖昧耐性の求められるタスクで、大変苦戦しました。「曖昧で不確実性の高い課題をどう解くか」という観点での学びが大変大きかったです。
学びの多いインターンになりました。ここまで読んでいただきありがとうございました!
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)
![]()



/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)