/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

この先も「シゴトでココロオドルひとをふやす」ために。Wantedlyのミッションをアップデート | Wantedly, Inc.
「仕事が楽しいなんて夢物語だ」「仕事は生きるために仕方なく行う、退屈で我慢してやるもの。」多くの方が一度はこんなことを聞いたり、思ったりしたことがあるのではないでしょうか?転職や副業、多様な働き...
https://www.wantedly.com/companies/wantedly/post_articles/499117
こんにちは、ウォンテッドリーでデータサイエンティストをしている樋口です。
今年の4月にウォンテッドリーはミッションを新たにし、「究極の適材適所により、シゴトでココロオドルひとをふやす」と掲げました。
本記事では、この新しいミッションにある"究極の適材適所"を達成させる取り組みの一つである、Wantedly Visitの募集一覧画面における推薦システムの改善について、具体的には、多様な募集を推薦できるようにした施策をご紹介します。
ウォンテッドリーの推薦チームで、どのような課題にどう取り組んでいるかや、そこで得られた開発の知見などをお伝えできればと思います!
今回推薦システムの改善を施したWantedly Visitは、人と会社が気軽に想いでマッチングするサービスです。このサービスがより多くの良いマッチングを生むためには、優れた推薦システムが不可欠です。
なぜ、どのようにWantedlyで推薦システムが必要なのかは、Tech Leadの合田さんのブログで詳細に解説されています。
今回のPJでは、ユーザー体験における起点として位置づけられている、募集一覧ページの推薦システムを改善しました。
この募集一覧の推薦システムとは、募集の並び順をユーザーにとって好ましい順序に並び替えるシステムを指します。レコメンデーションチームが機械学習を駆使し、ユーザーや企業の興味に関する情報を入力に、理想のマッチングが実現できるような順序に並び替えています。
本記事においては、"募集一覧のおすすめ順をユーザーごとに出し分けるシステム"のことを"募集一覧の推薦システム"と呼び、これについて解説していきます。
次に、募集一覧のおすすめ順をユーザーごとに出し分けるために、推薦システムの内部でどのようなことをやっているかを紹介します。
平たく言うと、各ユーザーに対して、掲載されている募集をマッチングできる順に並べ替えています。つまり下記のような、各ユーザー(user_i)に対する募集のリスト([project_i, ....] )を作っているのです。
上記のように、募集をユーザーごとにマッチングできる順に並べるには、どのような作業が必要でしょうか。
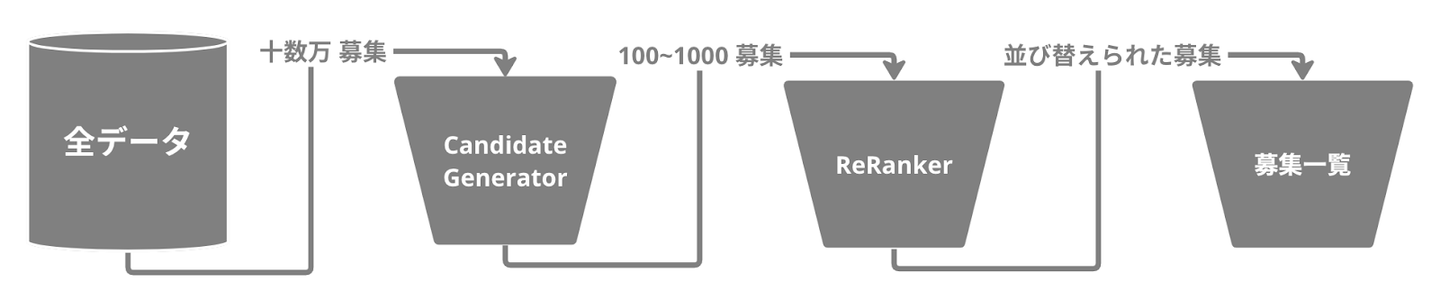
単純に考えるとアクティブなユーザーと全募集の組み合わせに対して「マッチングする度合い」をスコア化し、並び替えることで実現できそうです。しかし、Wantedly Visitでは 数十万の募集があり、アクティブなユーザに対して全ての組み合わせにリッチな計算(ex. 機械学習を用いた推論)をすることは現実的ではありません。
そのため、ユーザーが興味を示す可能性の高い募集をあらかじめ選定し、推薦システムの計算対象を絞りこむ処理が必要になります。このブログではこのように絞りこんだ計算対象を「候補集合」と呼びます。
このようにユーザにとって興味のある募集を選び出すコンポーネントをCandidate Generator(候補集合生成)、その候補集合を並び替えるコンポーネントをReRanker(ランク付け)と呼びます。二つのコンポーネントで構成された推薦システムのことを2-stage推薦システムと呼びます。
これまでのVisitの募集一覧の推薦システムでも、2-stage推薦システムが使われていました。
下記のように、Candidate Generatorで1ユーザーに対して興味のある募集が100~1000件にざっくりと絞られ、その後計算コストが高いReRankerで正確に並び順を計算するイメージです。
2-stage推薦システムでどんなアイテムをユーザに推薦するかは、どのような候補集合を選定するかが重要です。Wantedlyではこれまで、”ユーザーが以前に募集一覧で目にした募集”を中心に候補集合を作っていました。
このように候補集合を作るアプローチを選択した妥当性は主に以下の3つです。
上記のような理由から、2-stage推薦システムの導入当時は、”以前に募集一覧で目にしたものを中心に候補集合をつくる”ことは、妥当性の高い戦略と考えられていました。
しかし、運用する上で、以前に募集一覧で目にしたものを中心に候補集合をつくるアプローチがいくつかのユーザ体験上の問題を生んでいる事がわかりました。具体的には、ユーザーが積極的に新しい募集を探索しない限り、同じ募集が繰り返し推薦される傾向を生んでしまうのです。
この現象は、ユーザーがまだ知らない魅力的な募集と出会いにくい状況を作り出しています。さらに、一度閲覧したが興味を持たなかった募集も推薦リストの上位に残りがちです。
このような状態が続くと、ユーザーは新しい募集を見つける際に多くの時間と労力を費やす羽目になり、最終的にはWantedly Visitの利用をやめてしまう可能性が高まります。
また、ウォンテッドリー自体もこの問題により影響を受けます。特定の募集へのデータが偏在することで、全体として質の高い推薦システムの開発が難しくなってしまうのです。
上記のような問題を解決するために、プロジェクトが開始しました。
プロジェクトで達成したいことは、候補集合の多様性を増やし、見たこと無い魅力的な募集を、募集一覧で推薦できるようにする”と定めました。これにより、ユーザーはWantedly Visitに存在する多数の募集の中から自分にあった魅力的な募集を早く見つけることができます。
解決に当たっては、2-stage推薦システムのCandidate GeneratorとReRankerの責務を明確に分けて定義し、それぞれのコンポーネントが責務を全うし、望んだユーザー体験を実現できているかをオフラインテストで評価するという方針を取りました。このような方針を取ることで、問題を小さく分割し、正確に改善・評価できます。
上記方針に基づき、Candidate Generatorは、”計算リソースに収まる範囲で、ユーザーが興味を持つ可能性のある募集をなるべく多く取得する”ことを責務と定義しました。
この責務を達成することで、”みたこと無い魅力的な募集の表示されにくい”、という現状の問題が解決され、次のReRankerを経てユーザにより魅力的な募集が表示される確率が高まります。
改善に当たって、従来の”ユーザーが過去に見た募集”の他にも、複数の候補生成アルゴリズムを追加するという方針を取りました。具体的には下記のアルゴリズムを追加しています。
このように複数のアルゴリズムを使うことで、多様な募集を候補集合に含められるように工夫しています。
ReRankerの責務は、"生成された候補集合をユーザーの興味に合致する順に並べ替える"こととしました。この責務を達成することで、”すでに検討済みで興味がなかった募集も滞留する”、という現状の問題が解決されます。
ReRankerが並べ替えを効率的に行えるように、特徴量を追加しています。具体的には、選択された候補がユーザーの過去の活動とどれほど類似しているか、どのアルゴリズムから選ばれたか、さらには候補生成時の予測スコアや順位(例: 行列分解による予測値)などが考慮されています。
CandidateとReRankerの修正内容を合わせて、図にすると下記のようになります。
上記のような改善がどれほど効果があったのか、オフラインテスト、オンラインテストでそれぞれ評価しました。
”計算リソースに収まる範囲で、ユーザーが興味を持つ可能性のある募集をなるべく多く取得する”という責務を実現できているか確認するためにオフライン評価では、将来にインタラクションが発生したペアをどれだけ多く候補に含められているか(Recall)などの指標を計測しました。
複数回の実験を重ねた結果、計算リソースに収まる範囲でRecallにおいては40%近くの改善をすることができました。🎉
”生成された候補集合を、ユーザーがよりマッチしやすい順序に並べ替える”ことが実現できているか確認するために、nDCGなどを用いて評価しました。
こちらも複数回の実験を重ねた結果、nDCGは33%ほど改善をすることができました。🎉
上記のオフラインテストを経て、オンラインテストのリリースの判断をしました。オンラインテストではユーザ体験が実際に意図通りに良い結果を示しているかを確認しています。
最終的にはA/Bテストで介入領域において複数のオンラインメトリクスが 30%以上改善されたことを確認し、本施策のリリースによってビジネス上重要なKPIが大きく向上できました🎉
また、一人のユーザとして募集一覧にアクセスすると、今まで以上に見たことがなく、魅力的な募集が推薦されていることがしっかりと体感できました。
この施策を通じていくつかの学びを得ることができました。順不同ですがいくつかここにピックアップします。
1 . コンポーネントごとに責務・評価の分割することの重要性:
Candidate Generator、ReRankerなど、改善するコンポーネントを分け、それぞれの責務を定義し、それが達成されているかを別々に確認する方針はとても上手く行きました。
このように分割統治することで、どこが問題だったのか切り分けやすくなりますし、達成したいことを意図通り実現できているかを調査できます。実際、このように細かく評価することで、オフラインテストの結果とオンラインテストの結果をとても相関させることができました。
2. 定性評価の重要性:
各候補生成の結果を定量指標とともに、ユーザーのプロフィールや、募集のテキストのような定性的情報を合わせて見ることで、なぜこの指標が低いのかや、どうしたら改善できるかよりイメージを持つことができました。
今回のPJでは行列分解で生成された候補に含まれる募集がジャンルとしてすごく偏っていることが目視でわかったので、BM25などを使って頻出のアイテムの影響を軽減させるなどのアイディアを取り入れました。定性評価が改善のアイディア創出にも繋がっています。
3 . 疎結合なアーキテクチャの重要性:
候補集合が増えることで、必要な計算リソースや実行時間が増大し、結果フィードバックループが遅くなってしまいます。これを放置すると、実験の効率も開発者体験も悪くなってしまうため、コンポーネント単位で改善・評価できるアーキテクチャの必要性を強く理解しました。
(その時に感じた、気をつけるべきことは下記のブログに詳しくまとめてます)
この問題に対応するために工夫したポイントとして、例えば、複数の候補生成アルゴリズムはそれらを単独で実装・評価可能なアーキテクチャにしています。
# 実装イメージ
candidates = [
CandidateStrategy1(),
CandidateStrategy2(),
CandidateStrategy3(),
]
aggregated_candidates = []
for candidate in candidates:
candidate.fit()
candidate.evaluate()
aggregated_candidates.append(candidate.construct_dataframe())
aggregated_df = pl.concat(aggregated_candidates)このように各候補集合アルゴリズムを疎結合に保ち、それぞれで評価できるようにすることで、それぞれのアルゴリズムに対して早いフィードバックループを実験することができました。
導入に至ったアルゴリズムの一つである行列分解などはハイパーパラメータに敏感であり、反復的な試行が必要と見込まれていましたが、早いフィードバックループを得られる実装のおかげで、多くの反復実験ができ、良い精度を出すことができました。
また、上記のような改善方針やシステム設計や適切なハイパーパラメーターを選択できたのは、このPJ以前にKaggleの H&Mコンペティションに参加していたことが要因として大きかったと感じています。
Wantedly Visitの2段階の推薦システムを改善し、ユーザがまだ見ぬ魅力的な募集を推薦できるようにしました!
このようにウォンテッドリーではミッションの実現にむけて、ユーザー体験上の課題を推薦システムを経て改善しております。実はこの施策以降にも技術的に面白く、かつ成果が出た施策がいくつもあるため、また別の記事でも紹介していきたいです。
しかし実はまだまだ”究極の適材適所により、シゴトでココロオドルひとをふやす”というミッションの実現のためには、解くべき未解決かつチャレンジングな多数の課題があります。
これらのチャレンジングな課題を解決するため、ウォンテッドリーではデータサイエンティストを積極的に採用しています!!
ミッションの実現にはどんな課題があって、どう取り組んでいくのかや、チームとしてプロダクトにおける推薦システムをどうやって開発しているのかなど、すこしでも気になった点があればぜひ気軽に"話を聞きに行きたい"ボタンを押していただいてカジュアル面談できればと思っております!
もしくはTwitter DMで気軽に声をかけていただけたらと思います。最後までお読みいただきありがとうございました。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()