/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

オンデマンドインスタンスの料金 - Amazon EC2 (仮想サーバー) | AWS
オンデマンドインスタンスについては、お客様が使用された EC2 インスタンスの料金のみのお支払いとなります。オンデマンドインスタンスを使用することにより、ハードウェアのプランニング、購入、維持に伴うコストや手間が省け、高額な固定費となりがちな運用コストを、より低額な変動費に抑えられます。
https://aws.amazon.com/jp/ec2/pricing/on-demand/
こんにちは。8月初めから3週間、Wantedly Infrastructure Squadで夏季インターンに取り組んでいた @logica と申します。
今回の記事は、そのインターンの成果をまとめたものです。
さて、「インフラコストを削減する」と言った時、みなさんの頭には何が思い浮かぶでしょうか?
サーバー数の削減?パフォーマンスチューニング?良いですね。
果てにはクラウドベンダーの乗り換えなども視野に入るでしょう。
今回のインターンで、私はネットワークの通信費を抑えることによるコスト削減に取り組みました。
いくつかのカテゴリに分けながら、その過程を紹介させていただきたいと思います。
Wantedly Visitを始めとするWantedlyのサービスにおいて、ほぼ全てのバックエンドシステムはKubernetesクラスタの上で動いています。
この基盤は本番サービスが稼働するシステム基盤でありつつ、Wantedlyのすべての開発者がアプリケーションの開発運用で使うことになる開発者のためのプラットフォームでもあります。
KubernetesクラスタはAWS上でEKSを用いて建てられています。
本番や開発など、環境ごとにクラスタを構成しており、また全てのクラスターは東京リージョンの中で異なる2つのAvailability Zoneにまたがっています。
詳しくは、Engineering Handbookをご覧ください。
インフラ構成概要 - Wantedly Engineering Handbook
これより先は、KubernetesのPod・Serviceといったビルトインコンポーネントについて、ある程度理解していることを前提として話を進めます。
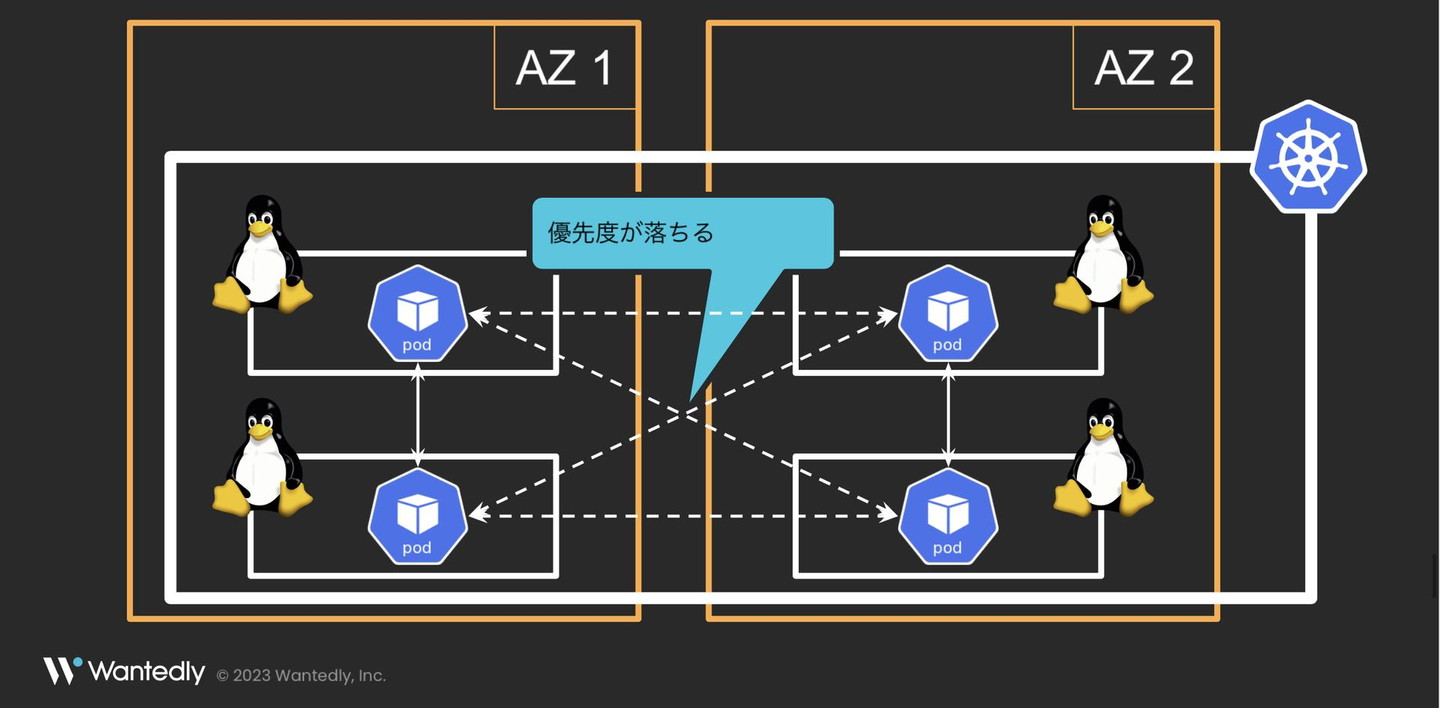
上記現行インフラの、「AZにまたがっている」という部分にお気づきになったでしょうか。
何も対策を施さない場合、kube-proxyと呼ばれる内部トラフィックルーター(大抵の場合実態はiptables)は、AZ内外問わずServiceに来た通信をselectorで指定されたPod群に対して均等に振り分けます。
すなわちKubernetesをデフォルト設定で使っている限り、AZ内通信とAZ外通信はおおよそ半々になるよう設計されているのです。
ここで、AWSの料金体系を見てみましょう。WantedlyではEKSのバックエンドとしてEC2 Auto Scalingグループを使用していますので、EC2の通信料金がそのまま反映されます。
公式ページを参照すると、同一AZ内であれば通信料金は無料ですが、AZをまたいだ通信はIn・Outどちらも$0.01/GBかかります(「同一の AWS リージョンでのデータ転送」を参照)。
仮に1日に10TBのAZをまたぐ通信があるとすると、1日で$100、一ヶ月で約$3,000かかる計算になります。日本円にすると月40万円超えという、無視できない数字です。
これを逆に考えれば、Pod同士が通信する時に、同じAZにいるPodに対して優先的に通信を飛ばすことができれば、AZをまたぐ通信の量は少なくなり、結果的にコストが削減できるわけです。
いきなり見出しから出してしまっていますが、Kubernetesには最近Topology Aware Routingという機能が追加されました。
Kubernetes 1.21から「Topology Aware Hints」としてalphaで提供が開始。1.23時点でbetaとなり、1.27時点で「Topology Aware Routing」に名前とAPIが変更され、現在1.28時点でもまだbetaとして機能提供がされている、比較的新しい機能です。
詳しいことは上記記事をお読みいただきたいのですが、ざっくり説明すると、Serviceに備わった、通信の発火点と同じトポロジー(リージョン・AZなど)にあるPodに優先して通信を振り分ける機能です。
下のイメージ図を見ていただけると一発でご理解いただけるかなと思います。
これを利用することによって、今まで無駄にAZをまたいでしまっていた通信を、AZ内に向けさせることができるというわけです。
ただし、利用するAZの数を超えるPodがある・AZに対してPodが均等に配置されているなど、有効になるために必要な条件がいくつかあるので注意が必要です(上記公式ページの「Safeguards」を参照)。
この機能は利用が簡単なのも非常にありがたいポイントで、ServiceのAnnotationに service.kubernetes.io/topology-mode: Auto と付けるだけで導入が終わります(1.27以前は service.kubernetes.io/topology-aware-hints というannotationを使って利用ができます)。
apiVersion: v1
kind: Service
metadata:
+ annotations:
+ # 1.27以前ならこちら
+ # service.kubernetes.io/topology-aware-hints: Auto
+ service.kubernetes.io/topology-mode: Auto
labels:
app: test
name: test
namespace: test-ns
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
selector:
app: test
type: ClusterIPこのように、書式を多少間違えても他の箇所に影響が及びにくいannotationを使用して設定が済むのは、サービスを壊すリスクを出来るだけ抑えたいインフラエンジニアの視点からすると非常にありがたいことかなと思います。
さて、上記Topology Aware Routingですが、利用に1つ重要な条件があります。
それは、振り分けたい通信がkube-proxyを通っているということです。
Istioのような独自プロキシを使うService Meshや、Ciliumのようにkube-proxyを独自のプロキシで置き換えてしまうCNIなどでは、Feature ParityとしてTopology Aware Routingが移植されていない限りは使えません(CiliumはTopology Aware Routingへの対応が行われています)。
WantedlyではIstioを一部使用しているため、その部分はTopology Aware Routingが効かなくなってしまいます。
ですがIstioには、Locality Load Balancingという名前で、以前からTopology Aware Routingとほぼ同じ機能が実装されています。
設定はIstioのカスタムリソースであるDestinationRuleを使います。
上記のServiceに対応させるのであれば、以下のようなDestinationRuleを設定すれば良いです。詳しい設定の意味は、Istioの公式ページを参考にしてください。
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: test
spec:
host: test.test-ns.svc.cluster.local
trafficPolicy:
loadBalancer:
localityLbSetting:
enabled: true
failoverPriority:
- 'topology.kubernetes.io/region'
- 'topology.kubernetes.io/zone'
outlierDetection:
consecutive5xxErrors: 10
interval: 1s
baseEjectionTime: 1m { name }.{ namespace }.srv.cluster.local の形でLocality Load Balancingを適用したいServiceを指定し、リージョンとAZが同じところに通信を振り分けるようfailoverPriorityを設定します。
Topology Aware RoutingとLocality Load Balancingは、有効になる条件が相互に排他的です。
通信が発火するPodにIstio Proxyが挿入されている場合はIstio Proxyがルーティングを担当するのでLocality Load Balancingのみが使えますし、逆に挿入されてない場合はkube-proxyがルーティングを担当するためTopology Aware Routingのみが使えるということが実験によってわかりました。
簡易的なテスト用アプリケーションを用いた調査の結果、これらを同時に導入しても特に干渉などはせず、相補的に全範囲をカバーしてくれることがわかったため、今回はこの2つの機能の併用を決めました。
今回Topology Aware RoutingとLocality Load Balancingを導入するにあたって、最も重要かつ難しかったのは正確な効果測定でした。
AZ内の通信とAZをまたぐ通信の量をそれぞれ分けて計測したいと思っていましたが、このタスクの開始時点でWantedlyの監視基盤はその機能を持ちませんでした。
できるだけAWSか現在の監視基盤(Datadog)の中で実現したいという方針で、サポートへの問い合わせや部署内からのアイデア出しを経て候補に上がったものをいくつか紹介します。
VPC内での通信のログを全て取ってくれる機能です。
なお、Wantedlyのクラスタでは、CNIとして「Amazon VPC CNI plugin for Kubernetes Amazon EKS アドオン」を使用しているため、クラスタ内通信は全てVPC内の通信としてカウントされます。
オーソドックスで良い方法でしたが、以下のような欠点がありました。
今回は3週間のインターンで、ログの集計方法を0から考えて実装するとそれだけでインターンが終わってしまいそうなため、候補から除外しました 。
以下のAWS公式ブログでも使用されている方法です。
EKS上にADOTコレクターアドオンを導入し、取得したトレース情報をX-Rayサービスマップに表示するというものです。
可視化したサービスマップも非常に見やすく、AWS内で完結する良い方法ではありましたが以下の欠点がありました。
全てのサービス開発チームに影響が及んでしまうため、候補から除外しました。
Datadogに備わっている、ネットワーク監視に特化した機能です。
通常のメトリクス取得では通信の片側(送信側 / 受信側)単位でしか情報を取得せず、通信の両端の情報を使って絞り込むことが困難です。
ですが、この機能を有効にすると送信部分と受信部分を内部でリンクさせ1つのデータとして扱うことができ、これによりAZ内かAZ間かの識別が可能となります。
通常のメトリクス同様グラフ等での可視化はもちろん、Service Mapという上記X-Rayサービスマップと似たネットワークマップを出すことも可能です。
導入に関しても、現在HelmチャートでDatadogをデプロイしているため、Helmのvalueを1つtrueに設定するだけで有効化が完了します。
唯一の懸念点は料金でしたが、Infrastructure Squadの皆さんに「今回のタスクに必要な期間のみ有効にすればそこまで問題はない」という判断をしていただけたのと、何より導入さえすればすぐに計測が始められる利便性に勝るものはないという考えのもと、導入が決定しました。
Wantedlyでは、Infrastructure Squadが「kube」というツールをアプリケーションエンジニアに対して提供し、アプリケーションエンジニアはそのインターフェースを通してKuberenetesクラスタを操作するという仕組みを取っています。
kube - Wantedly Engineering Handbook
kubeの機能の1つにManifest Generatorというものがあり、文字通りInfrastructure Squadが用意したテンプレートに従って各マイクロサービスをデプロイするのに必要なManifestを自動生成するという機能です。
(下記スライドの9ページ)
現在、内製サービスの半分以上がこのGeneratorによるManifest管理を導入しています。
内製でないサービス(監視など)は全てHelmで管理していますし、内製の中でも独自Manifestを使う方針のサービスはこの対象ではありません。
今回は、こちらのGenerationに使われるTemplateで、Serviceが存在する物に対してannotationとDestinationRuleを追加することとしました。
これにより、内製サービスの大部分にTopology Aware Routing / Locality Load Balancingが導入できるため、効果を出すには十分なスコープだろうと考えたわけです。
Templateで管理されていない範囲に関しては、インターン期間の短さもあって今回は対象外としました。
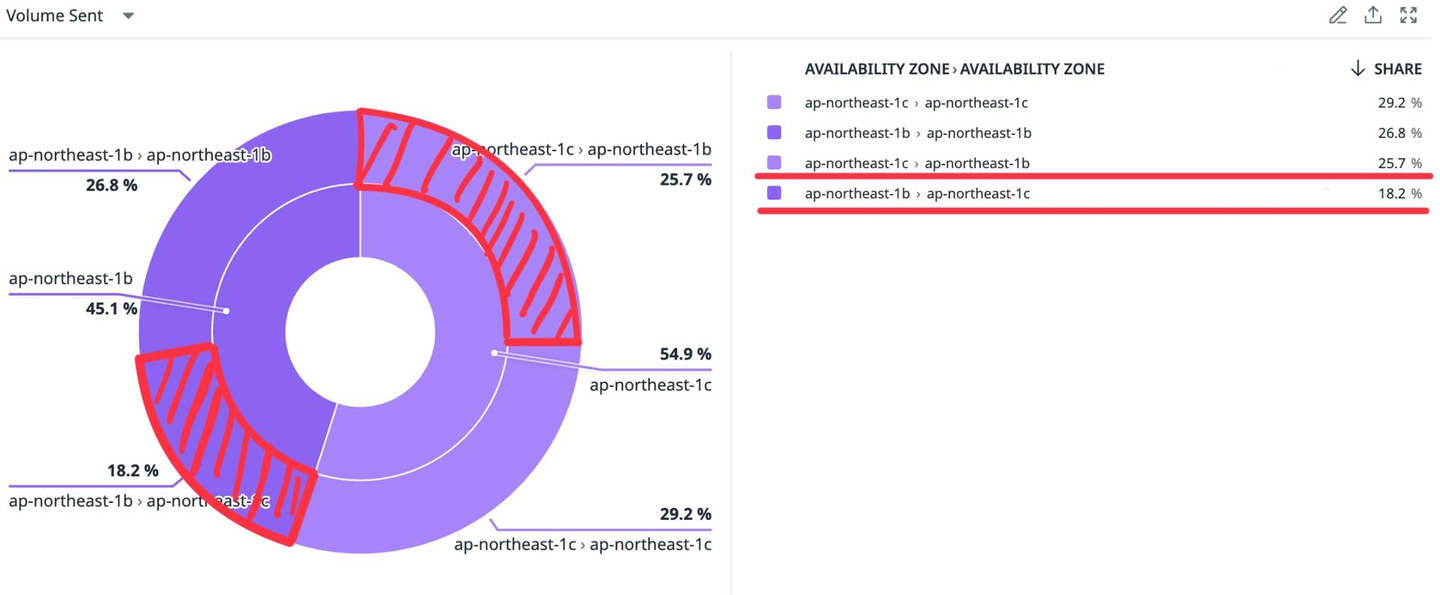
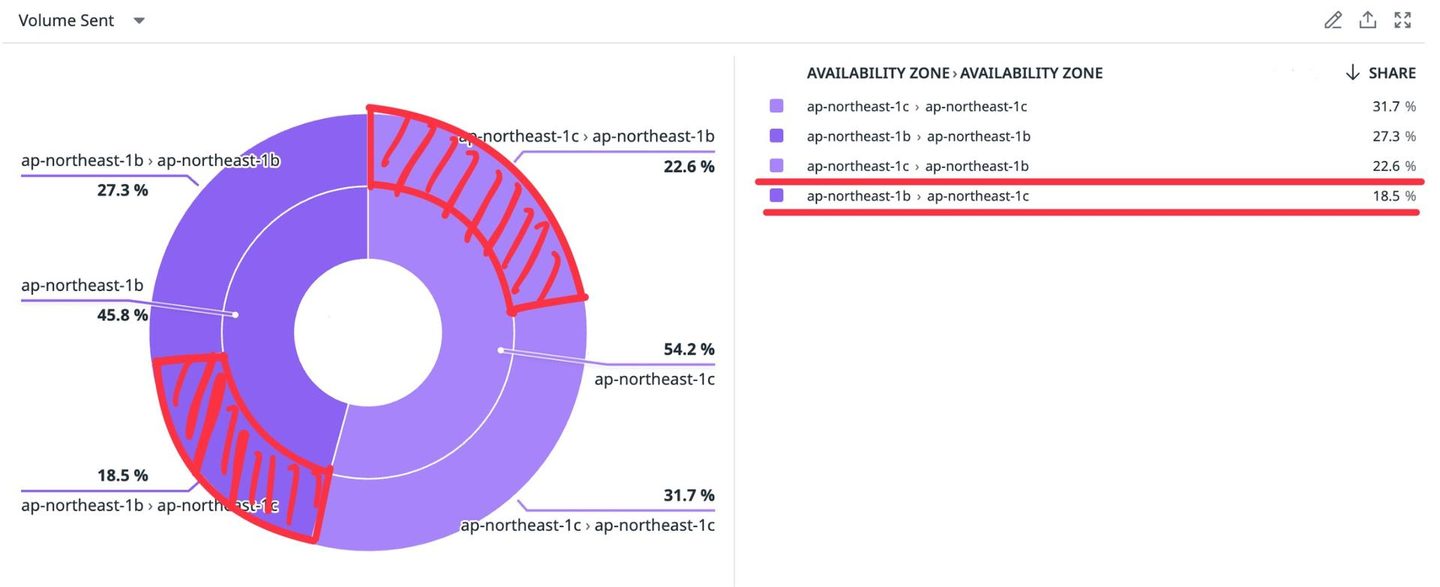
Templateに変更を反映し、効果測定をした結果です。
Datadog Network Performance Monitoringの画面から、具体的なデータ通信量を伏せさせていただいています。
導入前がこちら。赤い部分がAZ間通信です。
導入後がこちら。
お分かりいただけたと思いますが、今回導入した範囲ではほぼ効果なし(AZ間通信は2.8%のみ削減、コストは微減だが誤差の範囲内)という不甲斐ない結果に終わってしまいました。残念です。
AZをまたいだ通信は、大半が内製でないサービス由来だった
結果を不思議に思い調査をさらに進めたところ、AZをまたいだ通信は大半がLokiやFluentd、Elasticsearchなど内製でないサービスから出ていることがわかりました。
内製サービスの中でAZ間通信量がトップのサービスでもせいぜいAZ間通信全体の数%程度しか占めておらず、結果が出なかった理由も頷けます。
これに関してはそれぞれのサービスに対して個別に対処していくことにしました。
ただ、サービス内部のバッチ処理など、Serviceを通していない通信に関しては別方法で対処しなければいけず、さらに工夫が必要そうです。
Topology Aware Routingが有効になる条件を満たしていなかった
ただし、利用するAZの数を超えるPodがある・AZに対してPodが均等に配置されているなど、有効になるために必要な条件がいくつかあるので注意が必要です(上記公式ページの「Safeguards」を参照)。
Topology Aware Routingの紹介で以上のようなことを書きましたが、この条件を満たせていなかったサービスも少なくありませんでした。
WantedlyではPodのスケーリングにVPAとカスタムメトリクスベースのHPAを併用しており、Podの水平スケーリングがそこまで活発に行われないのもあまりPod配置が均等にならない理由かもしれません。
これに関しては、前々から検討が進んでいるPTSC制約を厳しくするなどの方法で解決を図ることができると考えています。
ただ、上記の内製でないサービスへの対処より優先度は下がるため、すぐさま何か対処する方針はありません。
今回は、AZをまたぐクラスタ上において、AZをまたいだ通信を減らしクラスタ内部のネットワークをコスト最適化する取り組みについて書かせていただきました。
もしみなさまのユースケースでもお役に立つ情報が提供できていたなら幸いです。
特にTopology Aware Routingについては、比較的新しい機能で企業での導入実績が検索してもほとんど見つからないという状態ですので、導入の輪を広げていただきたいなと思っております。
最後に、僕と同じようにクラウドインフラを将来主戦場としたい学生の皆様へ。
WantedlyのInfrastructure Squadインターンでは、学生の身分で通常触ることのない、プロダクション基準のKubernetesクラスタを触る機会を得ることができます。
ぜひ自分に合った形態のインターンに応募してみてください!

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()
/assets/images/5673658/original/767e046d-422d-44e3-ac17-74af4a96146e?1709547072)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)