/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)
Wantedly, Inc.では一緒に働く仲間を募集しています
内製ツール wantedly-maintenance を導入してシステムメンテナンスの体験を最適化する

on 2023/07/07
DX (Developer eXperience) Squad でソフトウェアエンジニアをやっている @igsr5 です。時期的にホットな Threads (@igsr5_) も載せておきます (やってみたかった)
最近はメインプロジェクトの傍ら、社内で放置されていた experimental なリポジトリや技術負債などを掘り起こしてなんとかすることに熱を上げています。そんなブームとは直接関係ありませんが、今回は私が今年の春ごろに行なった取り組みについてご紹介します。
はじめに
Wantedly では四半期に数回、システムメンテナンスを行いそれに伴う一時的なサービス停止が発生しています。メンテナンスの内容は様々で最近ではAmazon ElasticCacheで利用しているRedisのバージョンアップや Aurora PostgreSQLのバージョンアップが行われました。
これらのシステムメンテナンスは EOL(End of Life)対応やサービス機能の改善などさまざまな目的で行われていますが、どんな内容のシステムメンテナンスにしろシステム・ビジネスを持続させるために必要不可欠であるという重要な特徴を持っています。
しかしながらこれまでの Wantedly のシステムメンテナンスには、ユーザー体験の低下やオペレーションコストの増大といったボトルネックが存在し、サービスの安定性やスケーラビリティに影響を及ぼしていました。そしてこの問題を解決するため、私たちは新たに wantedly-maintenance と呼ばれるメンテナンス向けの仕組みを開発しました。
この記事ではその概要と wantedly-maintenance がどのようにシステムメンテナンスの体験を最適化しているのかを詳しく説明します。
wantedly-maintenance とは
wantedly-maintenance とはシステムメンテナンスのユーザー体験・開発者体験を最適化する内製ツールです。wantedly-maintenance は以下のような機能を持っています。
- 開発者の任意のタイミングでシステムへのリクエストを遮断できる
- リクエスト遮断中はWebアプリ、モバイルアプリでそれぞれ専用のメンテナンスページを表示できる
Webアプリ向けメンテナンスページの画面

モバイルアプリ向けメンテナンスページの画面

またシステムメンテナンス時のオペレーション支援として、上記の機能を実現するための自動化を提供しています。
$ script/switch-to-maintenance-mode
# メンテナンスを開始
$ script/switch-to-normal-mode
# メンテナンスを終了次の章では wantedly-maintenance がこれらの機能によって解決したかった課題について説明します。
存在した課題
前提として Wantedly のシステムメンテナンスはエンジニアがメンテナンスの準備と実施を担当しています。
そんなシステムメンテナンスですがサービスダウンに関して以下のような課題が存在していました。
1️⃣ ユーザーに見せるメンテ画面が存在せず、なるべくダウンタイムなしでメンテする必要があった
2️⃣ 完全ではない状態のシステムがユーザーリクエストを受けてしまうことでデータ不整合などのリスクを生んでいた
サービスダウン中の画面表示
1️⃣ はプロダクト品質とオペレーションコストに関する課題です。
サービスダウン中のメンテナンス画面が存在せず、何も考えないと Rails や RDB などのシステムエラーメッセージが直接ユーザーに表示されてしまうため、ダウンタイムが発生するメンテナンスが非常にやりづらい状態でした。
サービスダウン中のデータ不整合リスク
一方 2️⃣ はシステム基盤としての課題です。
AWS サービスのバージョンアップなどの作業時にユーザーからのリクエストを遮断することができないことから、リクエストが意図しないシステム影響を与えてしまうといったリスクがあります。
例えば以前行われた Amazon ElasticCache for Redis のバージョンアップ時にはこの事情によりオペレーション時のデータ不整合が問題となっていました。
これらの課題はエンジニアのオペレーション難化につながり、、
上で挙げた2つの問題は結果的にエンジニアのオペレーションの複雑化を招いていました。
また Wantedly サービスの特性や守るべきユーザー体験、社内の開発リソースを考えるとこれらの問題は十分にサービス成長のボトルネックであるといえる状態でした。
そこで上で挙げたようなシステムメンテナンスの課題を解決することでサービス成長のボトルネックを排除したいという思いのもと wantedly-maintenance の開発が行われました。
wantedly-maintenance で課題はどうなったか
既に wantedly-maintenance が本番導入されて2ヶ月経過していて、いくつか利用事例も出てきています。
ここではそれらの事例のうち特にプロジェクト前後で変化がわかりやすかった事例をご紹介します。
【事例】Amazon ElasticCache for Redis の EOL 対応
2 回目は 2023 年前半に行った「Amazon ElasticCache for Redis 3.X EOL」の対応でした。今回は wantedly-mainteanance を前提としたオペレーションで対応を行ったため前回とは状況が変わりました。
wantedly-maintenance 導入前
1 回目は 2022 年後半に行った 「Amazon ElasticCache for Redis 2.X EOL」の対応でした。この当時はまだ wantedly-maintenance は存在せず先ほど説明したようなシステムメンテナンスの課題が存在していた時期でした。
また、このシステムメンテナンスでは特にオペレーション時のデータ不整合リスクが問題になっていました。
- バージョン切り替え時にElasticCacheとアプリケーションとの接続が不安定になりデータ不整合が発生するリスクが存在
- その対応にバックエンドエンジニアも巻き込んでかなりの工数を費やした
wantedly-maintenance 導入後
2回目は 2023 年前半に行った「Amazon ElasticCache for Redis 3.X EOL」の対応でした。今回は wantedly-mainteanance を前提としたオペレーションで対応を行ったため前回とは状況が変わりました。
具体的にはオペレーション時にサービスへのリクエストを遮断できるようになったのでデータ不整合リスクの対応は行わなくて良くなっています。結果として以下のような変化が起こりました。
- 準備・実施にかかった作業工数の縮小
- オペレーションするエンジニアの負荷軽減
- スクリプト一発でメンテモードに入れる上、オペレーション中のインシデントリスクを格段に下げられる
また、システムメンテナンスにおけるスケジュールやエンジニアリソースに余裕ができたことでエンジニアが別の施策に取り組めるようになりました。
さて、ここからは wantedly-maintenance の裏側の仕組みついて解説していきます。
全体設計
基本として wantedly-maintenance はシステムメンテナンスの開始・終了タイミングに ALBのリスナールールを操作することでリクエストの遮断とメンテナンスページの表示を実現しています。
ただしWeb ユーザー(例: www.wantedly.com)とモバイルアプリユーザー(例: Visit iOS)で一部異なる点があるためそれぞれ解説します。
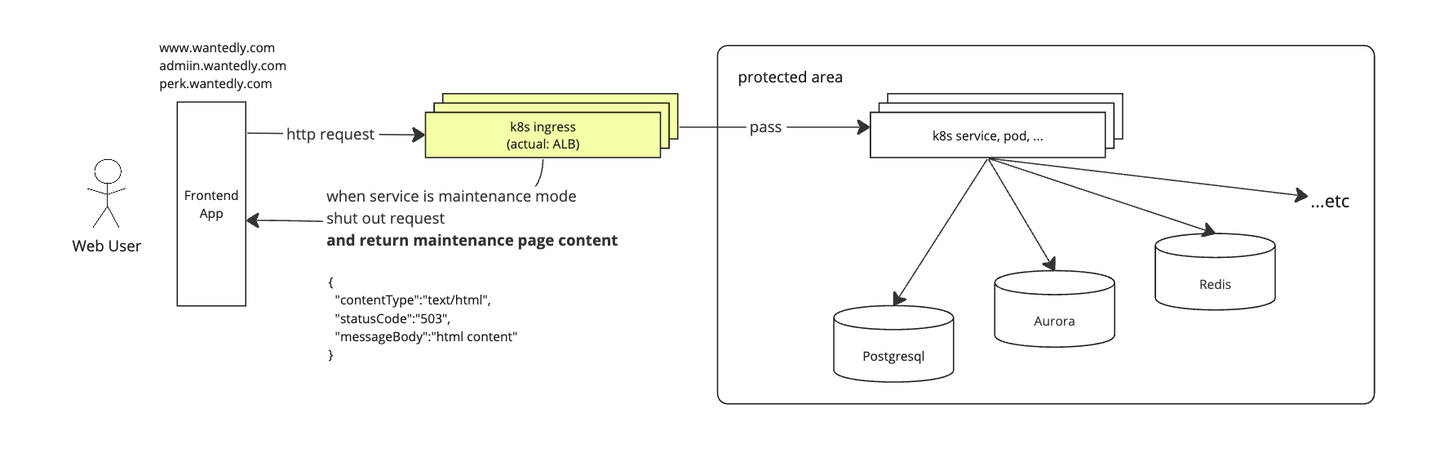
Web ユーザー
www.wantedly.com や perk.wantedly.com のような Web アプリは基本設計通りのシンプルな作りになっています。
具体的には ALB レイヤで fixed-response type のリスナールールを設定し、かつその messageBody にユーザーに表示するHTMLコンテンツを埋め込むことでリクエスト遮断とメンテナンスページの表示をおこなっています。
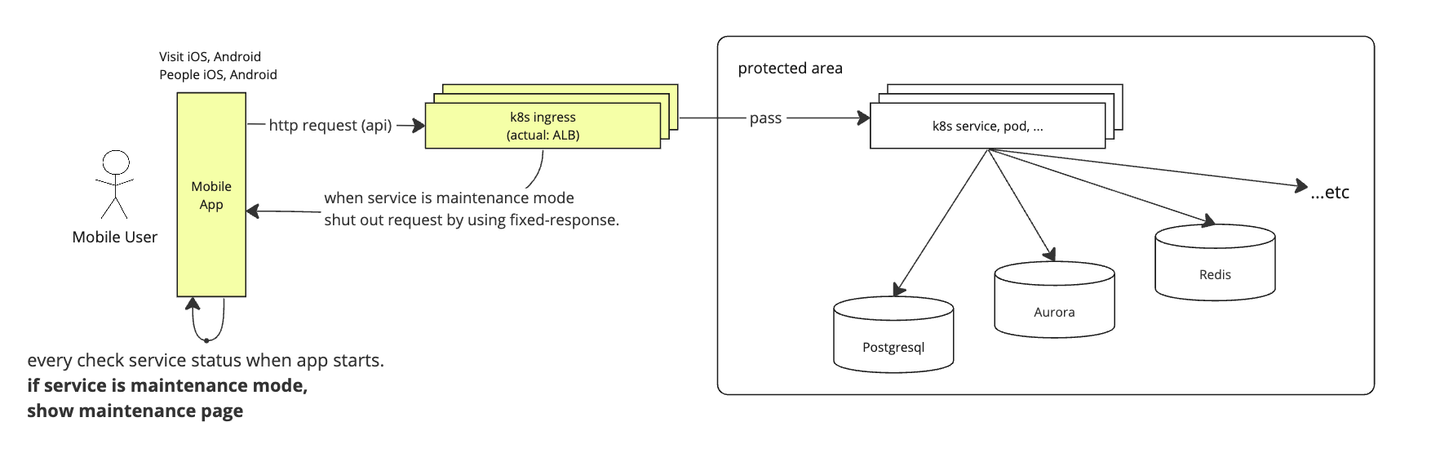
モバイルアプリ ユーザー
一方 Visit や People アプリのようなモバイルアプリは Web アプリに比べて 1 点だけ異なる点があります。
具体的にはモバイルアプリは、ユーザーに表示するコンテンツを自身で管理する必要があるため「アプリ起動時に service status をチェック & maintenance mode であればメンテナンス用の画面を表示する」という処理を各アプリごとに実装しています。
設計時の考慮
上記の設計を行う際にはさまざまな考慮を行いましたが、その中でも特に注力して考慮を行ったトピックについていくつかご紹介します。
① メンテナンスモードにより守ることのできる領域
プロジェクトの初期段階では「ユーザーからのリクエストをどこで遮断するか?」にいくつかの選択肢がありました。例えば以下のような選択肢です。
- DNS レイヤでリクエストを遮断する
- ALB レイヤでリクエストを遮断する
- アプリケーションレイヤでリクエストを遮断する
それぞれ実装コストと守ることができるシステム領域が異なりますが、Wantedly の場合は k8s cluster 内へのリクエストを遮断することが出来ればサービスダウン中のデータ不整合リスクをほぼほぼ減らせることが予想されたので今回は「ALBレイヤでリクエストを遮断する」を採用しています。
② メンテナンスモードの切り替え時のタイムラグ
前提としてシステムメンテナンスは深夜帯に行われるとはいえ、サービスを止めるということはサービスの価値の提供をストップさせることになります。
当然長時間のリクエスト遮断は好ましくありません。例えばメンテナンスモードの切り替えに5分も10分もかかっているようではそれだけでサービスが提供できるはずだった価値を減らしてしまいます。
今回はそのような事情を踏まえメンテナンスモードの切り替えを平均10秒、最大1分程度で行えるような仕組みを意識しました。
③ 機能を盛り込みすぎず最低限のシンプルな形に
これは
- メンテナンスモードを導入するのは今回が初めてなので上手くいくどうかが定かではない
- 小さく始めることで手戻りのリスクを減らし、メンテナンスページの価値を早期に検証することを優先したい
という理由のもとの意思決定です。リーン生産方式をプラットフォームエンジニアリングに適用したイメージです。ステータスページ系の SaaS に関する調査も行いましたが同様の理由で採用を見送っています。
④ インフラエンジニアの使いやすいように最適化した形で提供する
これは Wantedly で現状システムメンテナンスに責任を持つエンジニアは Infra Squad であり、その体制は今後もしばらく変わらないことが事前に分かっていたためです。ツールの利用者がインフラエンジニアであることを設計時にも抑えておけば初期実装コストやその後の運用コストも削減できるためこの特性を意識しています。
例: シェルスクリプトによる自動化が選択肢に入る
個別設計・実装
この章では個別の実装について触れていきます。
wantedly-maintenance を実装する際に行った作業はざっくりと以下の通りです。
- Web/Mobile App それぞれでユーザーに表示するメンテナンスページのデザイン
- Web 向けメンテナンスページの実装
- Mobile App 向けメンテナンスページの実装
- Mobile App 起動時のサービスステータスの確認処理の実装
- ALBレイヤでリクエスト遮断を行うための検証
- ALBリスナールールの切り替えの自動化の実装
これらのステップのうち、後半のリクエスト遮断と Web アプリ向けの Webアプリ向けのメンテナンスページ配信の話が面白いのでそれぞれご紹介します。
リクエスト遮断の仕組み
前提としてWantedly サービスの全てのリクエストは Next.js 等の Web アプリを含め、以下の図で示されるフローに沿って処理されます。
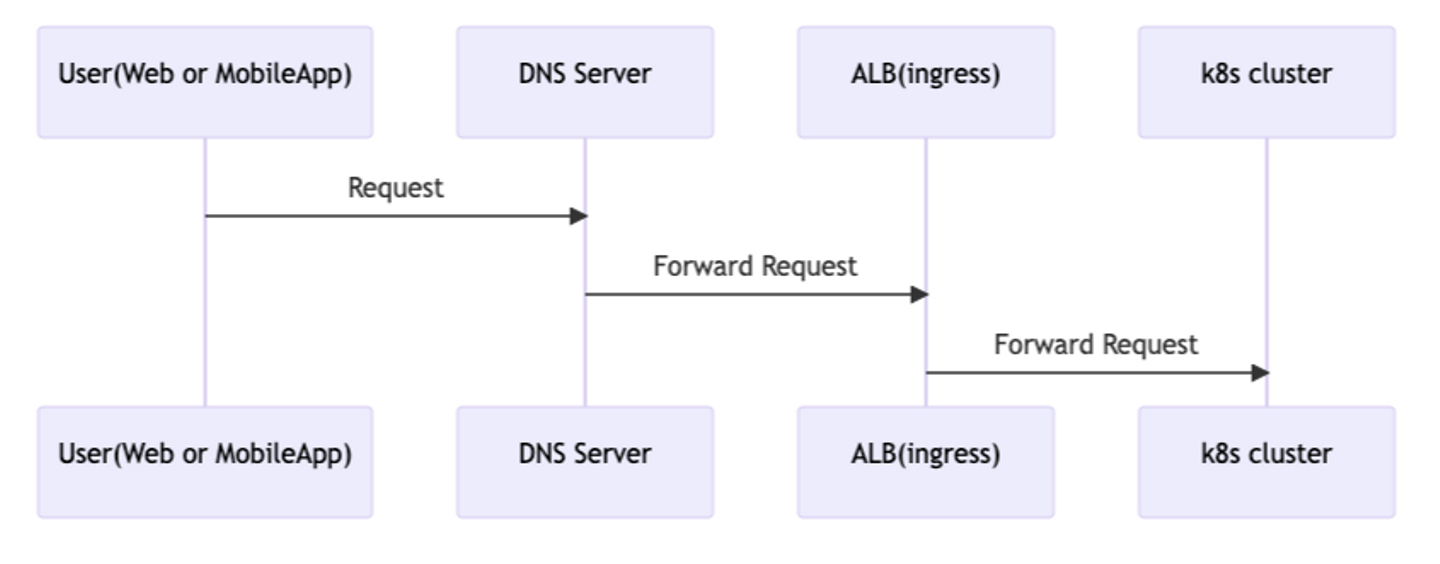
また Wantedly サービスで利用される k8s manifest は全て Argo CD で管理されています。
wantedly-maintenance はこれらの既存のインフラ特性を利用してリクエスト遮断を実現しています。
それでは具体的なリクエスト遮断の仕組みの話に移ります。
まず基本として wantedly-maintenance では上記のリクエストフローのうちALBに専用のリスナールールを一時的に追加することでメンテナンスモードを実現しています。
また Wantedly では AWS Load Balancer Controller を使っていて k8s manifest から ALB リソースを作っているので実際のオペレーション時には以下のような k8s manifest を kubectl patch コマンドで当てています。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
alb.ingress.kubernetes.io/actions.response-503-with-maintenance-page: {
type: "fixed-response",
fixedResponseConfig: {
contentType: "text/html",
statusCode: "503",
messageBody: (メンテページのHTMLコンテンツ)
}
}
spec:
rules:
- http:
paths:
- backend:
service:
name: response-503-with-maintenance-page
port:
name: use-annotation
path: /*
pathType: ImplementationSpecific自動化の話
とはいえオペレーション毎に kubectl コマンドを発行するのは負荷が高い上、Wantedly のシステム内には既にいくつもの k8s ingress (ALB) が存在しているので時間もかかってしまいます。
そこで wantedly-maintenance ではオペレーション自動化の機能をシェルスクリプトと config yaml という形で提供しています。
具体的には以下のような yaml を事前に用意しておき、オペレーション当日に専用のシェルスクリプトを実行することで全ての対象 k8s ingress のオペレーションを数秒で行うことができます。
config yaml の設定例
# ここに記載されたingressはメンテモード中、text/htmlフォーマットの503レスポンスが返る
application_settings:
- namespace: hoge-service
ingress_name: public
healthcheck_url: https://hoge.wantedly.com/ping
- namespace: fuga-service
ingress_name: public
healthcheck_url: https://fuga.wantedly.com/healthcheck
# ここに記載されたingressはメンテモード中、application/jsonフォーマットの503レスポンスが返る
system_settings:
- namespace: hoge-api-gateway
ingress_name: hoge-api-gateway
healthcheck_url: https://hoge-api.wantedly.com/pingメンテナンス開始用スクリプトの実行例
❯ ./script/switch-to-maintenance-mode
Please select an environment:
1) sandbox
2) qa
3) prod
#? 3
You have selected the prod environment.
========================================================================
WARNING: You've selected the production environment! Please be careful.
========================================================================
Is this correct? (yes/no): yes
ingress.networking.k8s.io/visit-ambassador-v2 patched (no change)
auto sync is disabled in "hoge-service"
ingress.networking.k8s.io/visit-ambassador-v2 patched (no change)
auto sync is disabled in "fuga-service"
ingress.networking.k8s.io/public patched (no change)
auto sync is disabled in "hoge-api-gateway"
ingress.networking.k8s.io/public patched (no change)
...- スクリプトでは初めに対象の k8s cluster を選択し、その後 Argo CD の Automated Sync の停止と ingress の書き換えを行うようになっています。
またリクエスト遮断の解除 (サービス復旧) も同様にシェルスクリプトで自動化されています。さらにリクエスト遮断の開始時とは違い、内部で kubectl patch コマンドではなく Argo CD の Automated Sync の再開を行うことで自動的に元の master の状態に戻すという小さな工夫をしています。
メンテナンス終了用スクリプトの実行例
❯ ./script/switch-to-normal-mode
start to enable argocd autosync.
Please select an environment:
1) sandbox
2) qa
3) prod
#? 3
You have selected the prod environment.
========================================================================
WARNING: You've selected the production environment! Please be careful.
========================================================================
Is this correct? (yes/no): yes
==================================
changing hoge-service ingress...
auto sync is enabled
==================================
==================================
changing fuga-service ingress...
auto sync is enabled
==================================
==================================
changing hoge-api-gateway ingress...
auto sync is enabled
==================================
successfully enabled argocd autosync!
will check following urls.
- https://hoge.wantedly.com/ping
- https://fuga.wantedly.com/ping
- https://hoge-api.wantedly.com/ping
✔ https://hoge.wantedly.com/ping responded with HTTP 200
Remaining URLs:
- https://fuga.wantedly.com/ping
- https://hoge-api.wantedly.com/ping
✔ https://hoge-api.wantedly.com/ping responded with HTTP 200
Remaining URLs:
- https://fuga.wantedly.com/ping
✔ https://fuga.wantedly.com/ping responded with HTTP 200
Remaining URLs:
waiting for remaining URLs to respond with HTTP 200....
=======================================================
All URLs have successfully responded with HTTP 200!!
=======================================================
Argo CD の sync がたまにトリガーされないことがあるので、スクリプトでは Argo CD の Automated Sync を有効にした後に各サービスのhealtch checkが完了するまで待機するよう実装しています。
またこの自動化スクリプトは実際に社内で wantedly-maintenance を利用したエンジニアからもとても好評で「スクリプト一発でメンテモードに入れるのはとてもいい体験だった!」という声をもらっています。
Webアプリ向けのメンテナンスページ配信
wantedly-maintenance では Web アプリ向けの HTML 配信を ALB リスナールールの fixed-response type を用いて実現しています。実装はシンプルでメンテナンス開始時の kubectl patch コマンドで HTML コンテンツを message body に直で埋め込んでいます。
{
type: "fixed-response",
fixedResponseConfig: {
contentType: "text/html",
statusCode: "503",
messageBody: (ユーザーに表示したいHTMLコンテンツ)
}
}今回このような実装方法を採用したのは主に以下のような理由です。
- ユーザーがメンテナンス終了時にページリロードによって元いたページに戻れるようにしたい
- これは我々が担保したいと考えるユーザー体験の話
- 例えば fixed-response ではなく redirect のリスナールールを採用するとメンテナンス中にサービスにアクセスしたユーザーは当初アクセスしようとしていたURLを失ってしまう
- この要件は fixed-response だけでなく forward でも実現できるが、次に示す理由で forward の採用は見送っている
- forward を利用するためにはメンテナンスページ自体のホストするサーバーを個別に用意する必要がある
- これは AWS の提供する ALB リスナールールの仕様によるもの
- つまり forward を利用すると fixed-response を利用する際に比べて運用コストが上がってしまう
今までの Wantedly では「基盤開発を行なってもそれらが運用フェーズで適切に回らない」という課題を抱えがちで、それに対して今回の wantedly-maintenance では持続可能な開発基盤を実現したいと言う思いがありました。
ただし fixed-response にも弱点はあって message body の文字数に上限が存在します (参考: 1024文字)。
今回デザインされたメンテナンスページはHTMLコードにしても 1024 文字以内に収まりましたが、今後その前提が崩れる際には再度メンテナンスページの配信方法を検討する必要があります。
そのような考慮を重ねた上で初期実装コストと運用コスト、今後のメンテナンスページの拡張可能性の低さを鑑みて今回は「fixed-responseで HTML コンテンツを配信する」という選択肢を取りました。
初本番導入
この章では wantedly-maintenance を始めて実際に使ってみた際の様子をご紹介します。
wantedly-maintenance の初利用は記事途中でも紹介した通り ElastiCache for Redis 3.x EOL の対応です。このタイミングでは実際に Infra Squad のメンバーに wantedly-maintenance を利用してもらい無事オペレーションが完了しました。
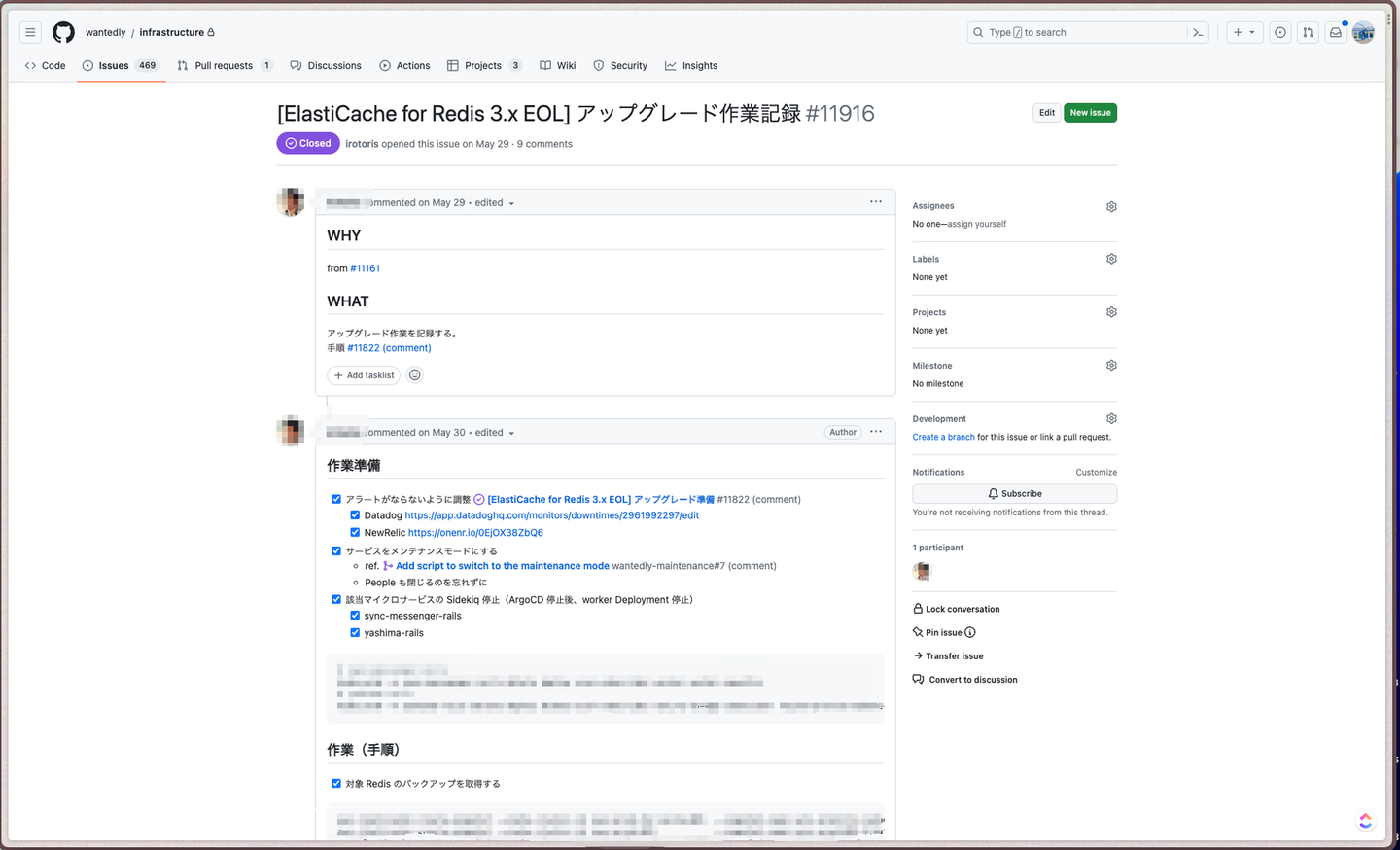
しかし実際にはこのシステムメンテナンスの前に一度自分たちで wantedly-maintenance の試運転を行なっていました。
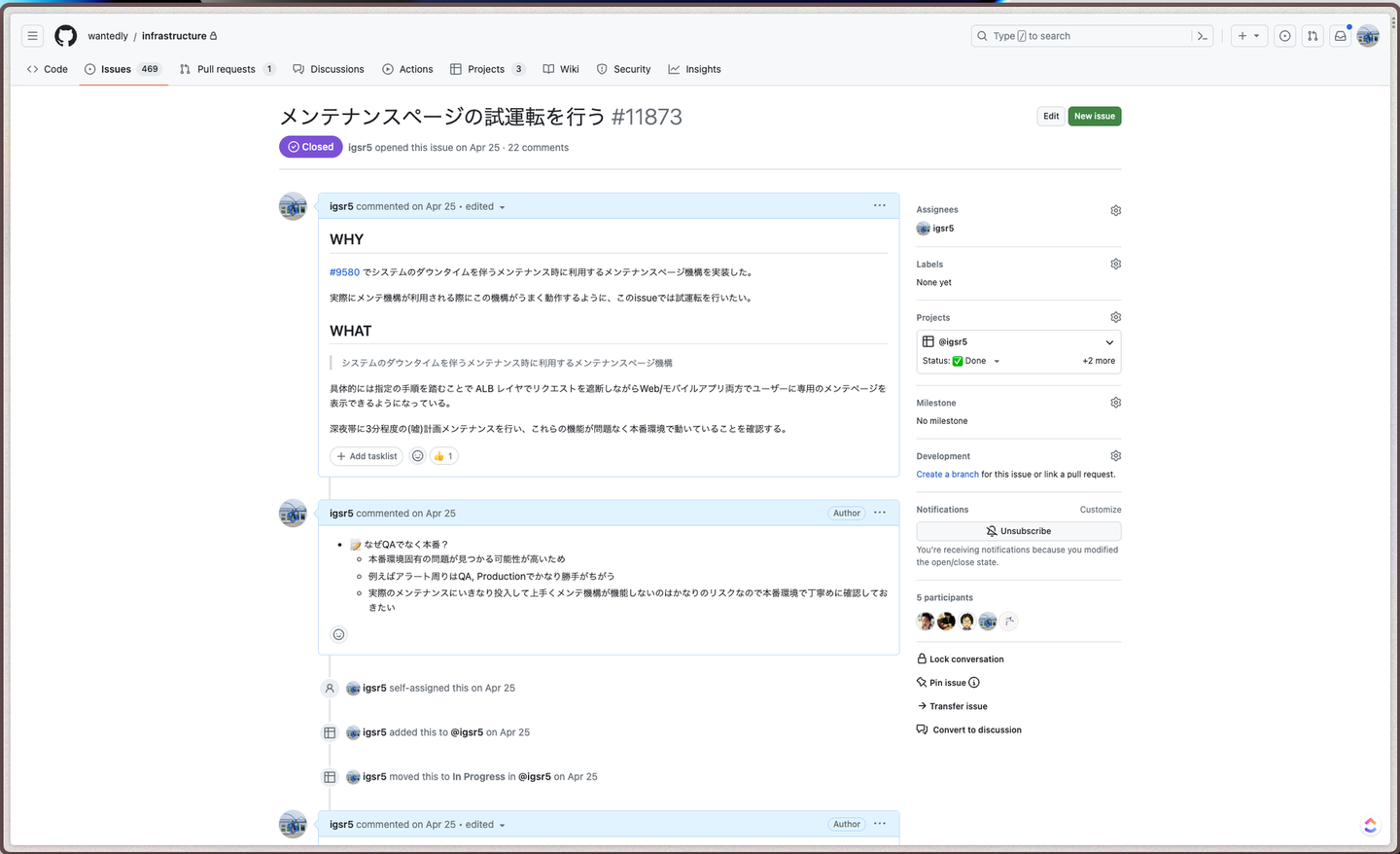
この試運転が非常に上手くハマっていて、結果的に先ほどの ElastiCache for Redis 3.x EOL でのスムーズなオペレーションに大きく貢献していました。
試運転の話
今回の試運転では自分たちで意図的に本番環境を落として wantedly-maintenance が上手く動作するか?をシミュレーションしました。
シミュレーションによって確認した項目は以下の通りです。
- wantedly-maintenance に必要な機能が適切に動作しているか (メンテナンスページ表示、リクエスト遮断)
- メンテナンス中・メンテナンス復帰後のユーザー体験は悪くないか
- メンテナンス開始・終了の切り替えはスムーズに行えるか
- wantedly-maintenance によって社内のDatadogやNewRelicなどのアラートが鳴りまくらないか
あらかじめこれらのような観点を整理し、試運転に臨んだことで実際にいくつかフィードバックを得られたのでその後1~2weeksかけて改善を行いました。
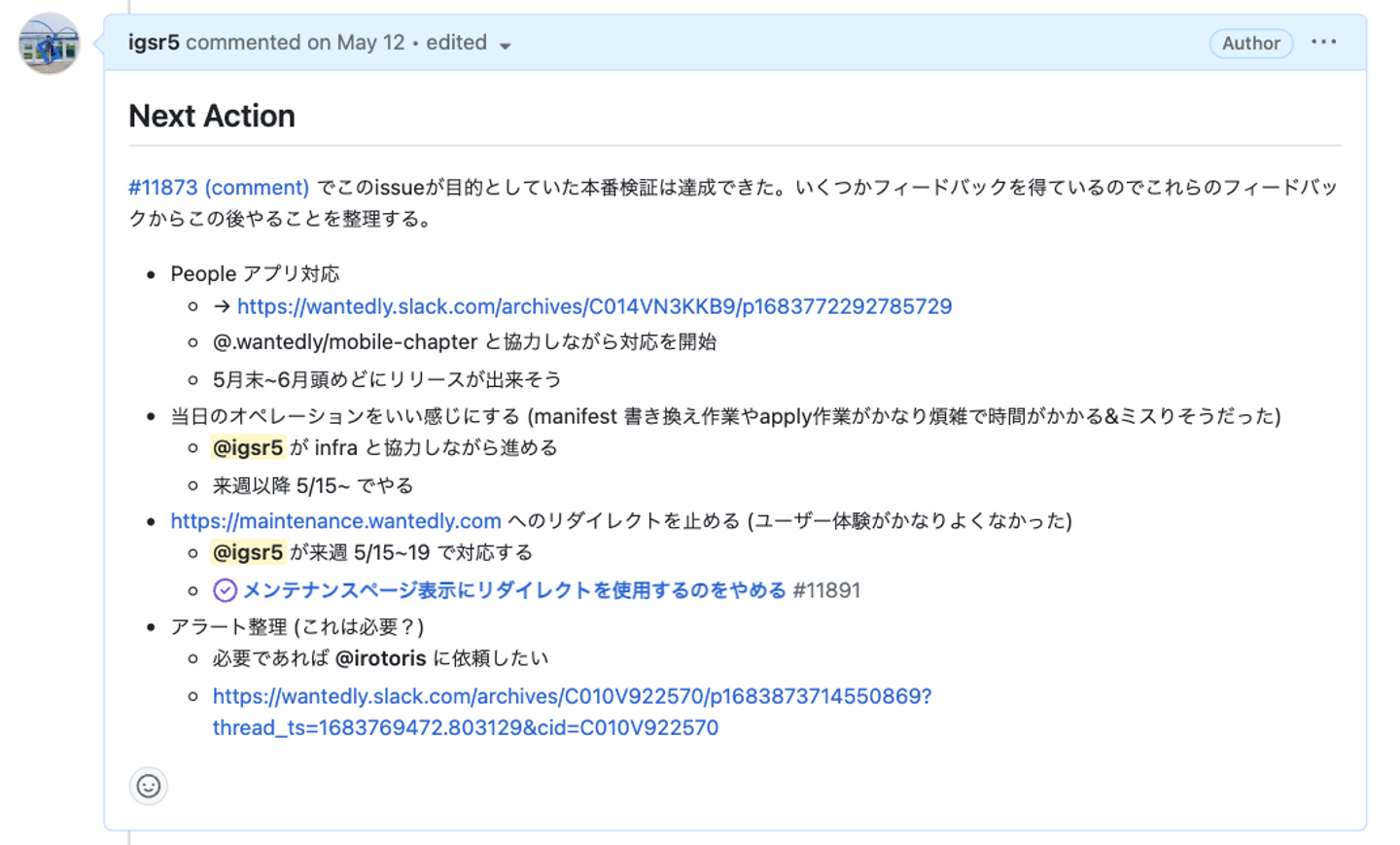
終わりに
今回の記事では Wantedly のシステムメンテナンスに関する改善とその効果について紹介しました。
この記事の内容が世の中のサービスメンテナンスに悩む人々の参考になれば幸いです。
参考サイト
- AWS Documentation| Listeners for your Application Load Balancers
- Kubernetes Documentation | Ingress
- Better Stack: Spot, Resolve, and Prevent Downtime.
- status.io - Hosted Status Pages
- https://argo-cd.readthedocs.io/en/stable/user-guide/auto_sync/
- Automated Sync Policy - Argo CD - Declarative GitOps CD for Kubernetes
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

Wantedly, Inc.からお誘い
この話題に共感したら、メンバーと話してみませんか?
内製ツール wantedly-maintenance を導入してシステムメンテナンスの体験を最適化する

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)
