hi18nとは
hi18n は現在Wantedlyで開発中の、TypeScript/JavaScript向け翻訳テキスト管理ライブラリ (i18nライブラリの一種) です。
本記事ではhi18nの重要な設計上の判断やその背景について説明します。
なぜ新しく作ったのか
React向けのi18nライブラリとしては react-intl (FormatJS) や LinguiJS などが知られており、WantedlyでもLinguiJSを使っています。
このLinguiJSはよくできたi18nライブラリですが、現代的なJavaScriptにおける宣言的なプログラミングへのサポートが軽視されている傾向にあります。たとえば、LinguiJS v3ではこれまでReact contextとして管理されていた状態がグローバルオブジェクトの状態に変更されています。これは宣言的なパラダイムへの逆行といってもいいでしょう。
LinguiJSのよいところは引き継ぎつつ、宣言的プログラミングとの相性を重視すれば優れたi18nライブラリになるだろうと考えを実証すべく生まれたのが今回紹介するhi18nです。
hi18nの基本方針
- 国際化の基礎部分はできるだけICUやLinguiなど既存ライブラリの知見を受け継ぎ、ECMA-402 (Intl) など既存の仕組いを再利用する。
- 一方、JavaScript特有の部分に関しては現代的なJavaScriptのエコシステムへの適合性を重視する。
- できるだけ適切なレベルのツールを使う。
- ランタイムでできることはランタイムで行う。
- 型でできることは型で実現する。
- ランタイムでも型でできないことだけ、専用のツールで行う。
- あるべきデータをあるべき場所に配置する設計にする。
メッセージ形式
システムメッセージを翻訳可能な状態にするには、十分な一般性が必要です。ライブラリに十分な一般性がなかったためにうまく翻訳できない事例は実際に存在しています。
- フォーマット引数の順序が固定だったために不自然な翻訳になってしまったと考えられる例がある。 (→「"read" になることはできませんでした」のひみつ)
- (正確にはアプリケーション側の一般化が不十分であることを指摘するのが同記事の主旨だが、当時のprintf系フォーマット関数の機能不足の話ともとれる)
- JavaのChoiceFormatは不等式によるメッセージの分岐を可能にしている。その想定された用途のひとつは複数形の処理だが、ロシア語のように周期的に複数形が変化する場合には対応できない。
- n%10が1のとき単数主格 (n%100が11のときを除く)、 n%10が2,3,4のとき単数生格 (n%100が12,13,14のときを除く)、 それ以外のときは複数生格になる。 1, 101, 201, 301, ... のように周期的に単数形があらわれる点に注意。
他にどのような一般性が必要になるのか、一介のプログラマーが予期するのは困難です。ここで独自に頑張る必要もないので、メッセージ形式に関しては偉大な先達であるICUとLinguiのやり方を模倣します。
ICUが提供するメッセージ形式はおおよそ以下のようなものです。
- `{foo}` のように書くことで名前つき引数を参照し、 `{0}` のように書くことで位置引数を参照できる。
- 特に指定がなければ文字列として挿入される。
- 数値や日付時刻に対しては `{foo,number}` などのようにしてフォーマットを指定できる。
- 複数形対応として `{foo,plural,...}` と `{foo,selectordinal,...}` という特別な形式がある。これは `foo` の値によって分岐して、以降で指定した分岐のうちのひとつを採用する。分岐内に再帰的にフォーマット指定があればそれも評価される。
- 文法上の性などに対応するための汎用の分岐として `{foo,select,...}` がある。
Linguiではこれをさらに拡張しています。
- `<0>...</0>` のようにXMLのタグのような構文を使って、メッセージにマークアップを含めることができる。マークアップは翻訳呼び出し側で提供するReactの要素で置き換えられる。
- これにより、改行やリンクなどを含むUIの翻訳を、複数の翻訳IDに分割することなく自然に行うことができるようになる。
翻訳ID
たとえば以下のような翻訳メッセージがあったとします。
- Hello, {name}!
- こんにちは、{name}さん!
- Привет, {name}!
- {count, plural, one {You have # message.} other {You have # messages.}}
- {count, number}件のメッセージがあります。
- {count, plural, one {У вас есть # сообщение.} few {У вас есть # сообщения.} other {У вас есть # сообщений.}}
ここには2種類の翻訳メッセージがあるので、これらを区別するためのID (翻訳ID, translation ID) を付与する必要があります。これには大きく2つの流儀があります。 (以下名称は本稿独自のもの)
人工翻訳ID
UI上でその翻訳がどう呼び出されるかに応じて、プログラマーがIDを付与します。たとえば、以下のようなIDを付与します。
- example/greeting
- Hello, {name}!
- こんにちは、{name}さん!
- Привет, {name}!
- example/messages
- {count, plural, one {You have # message.} other {You have # messages.}}
- {count, number}件のメッセージがあります。
- {count, plural, one {У вас есть # сообщение.} few {У вас есть # сообщения.} other {У вас есть # сообщений.}}
たとえば以下のようなライブラリは人工翻訳IDで使われることが多いようです。
- Ruby (Rails) のi18n
- FormatJS
自然翻訳ID
主要な言語を1つ決め、その言語でのメッセージをそのままIDとして利用します。たとえば、以下のようなIDを付与します。 (英語を主要言語とする例)
- Hello, {name}!
- Hello, {name}!
- こんにちは、{name}さん!
- Привет, {name}!
- {count, plural, one {You have # message.} other {You have # messages.}}
- {count, plural, one {You have # message.} other {You have # messages.}}
- {count, number}件のメッセージがあります。
- {count, plural, one {У вас есть # сообщение.} few {У вас есть # сообщения.} other {У вас есть # сообщений.}}
以下のようなライブラリは自然翻訳IDで使われることが多いようです。
- gettext …… gettextのngettext関数は単数形と複数形の2つを引数に取る。つまり、英語でのメッセージを翻訳IDにすることが想定されている。
- LinguiJS …… 自然翻訳IDでの利用を想定したマクロが存在する。
- ただし、Wantedlyでは人工翻訳ID方式で運用しています。
それぞれの利点
人工翻訳IDと自然翻訳IDにはそれぞれの利点があります。
- 人工翻訳IDのメリット
- 翻訳IDの衝突が起きにくい。たとえば、自然翻訳IDでは “Refreshing” を「更新しています」と訳すと、本来「更新(する)」と訳すべき場所でも「更新しています」と表示される事故が起こるが、人工翻訳IDではこの種の事故は起きにくい。
- 翻訳ID順でソートしたときに、翻訳カタログ上でUIの構造順に並ぶので文脈がわかりやすい
- 自然翻訳IDのメリット
- 翻訳ファイルのフォーマットによらず、原文が参照しやすい (ID自体が原文であるため、翻訳ファイル内の近い位置に必ず存在する)
- 実装側でメッセージを変更したとき、自動的に「翻訳が必要な状態」に戻るため、翻訳の鮮度管理のミスが起きにくい。
- 実装が読みやすい。 (実際に主言語で表示したときの文字列がソースコード中に現われるため)
これらを踏まえつつ、hi18nでは人工翻訳IDをメインのパラダイムとして扱うことにしました。これには以下の理由があります。
- 人工翻訳IDをベースにした構文のほうが、JavaScript/TypeScriptと自然に統合するため。
- hi18nでは「ランタイムでできることはランタイムで行う」「型でできることは型で実現する」という方針であり、人工翻訳IDのほうがこの理想に近い
- Wantedlyとしての都合。Wantedlyでは (おそらくRailsの影響もあって) 人工翻訳IDのワークフローが浸透しているため、これにあった機能を優先的に提供したい。
とはいえ、自然翻訳IDをサポートしないわけではありません。まず、hi18nでは任意のJavaScript文字列 (UCS-2文字列) を翻訳IDとして使えるため、自然翻訳IDを採用できないシステム上の制約はありません。
その上で、「ランタイムでできることはランタイムで行う」の制約を最大限守りつつ、自然翻訳IDをサポートするAPIやツール上のサポートも余裕があれば実装したいと考えています。たとえば、tagged template literalを使えば以下のようなAPIを提供できます。
// 国際化する前のコード
console.log(`Hello, ${name}!`);
// 国際化後のコード ({} を二重にする)
// 型システム上のサポートは限定的になるが、ランタイムでは十分にサポートできる
console.log(t`Hello, ${{name}}!`);
あるべきデータをあるべき場所へ
プログラミングにおいて状態の設計は最も本質的な問題のひとつです。そして、それには状態を持たないという判断も含まれます。
hi18nでは、旧来のi18nライブラリで状態として管理されがちだった以下のデータを状態として持たないという判断をしています。
- 翻訳カタログはデータであって状態ではない
- 翻訳カタログをデータストアにロードする、という手順は存在しない
- 現在のロケールは文脈/環境 (Reader r) であってあって状態 (State s) ではない
- ロケールを更新・上書きする、という手順はhi18n内には存在しない
- 利用者がロケールを状態として管理し、hi18nをその配下に置くことは考えられる
たとえば、hi18nの主要なAPIのひとつである useI18n はこの考え方を忠実に反映しています。
import { useI18n } from "@hi18n/react";
// 翻訳カタログはデータである → importして使う
import { book } from "../../locale";
// 現在のロケールは文脈である → 文脈から取得 (この場合はuseI18nがやってくれる)
const { t } = useI18n(book);
// 翻訳カタログと現在のロケールから翻訳処理が取得できた。あとは使うだけ
t("example/greeting"); // => Hello, world!
この設計のデメリットとして、翻訳のために各ファイルで2回インポートを書く必要があり手間がかかるという点が挙げられます。しかし、hi18nではあえてこの部分を簡略化せず、「あるべきデータをあるべき場所へ」の原理を優先することでトータルで高い生産性を実現することを目標にしています。
翻訳データの階層性を見直す
hi18nでは翻訳カタログをデータストアにロードするという手順を排した結果、「翻訳カタログを束ねたもの」を明示的に扱う必要が出てきました。
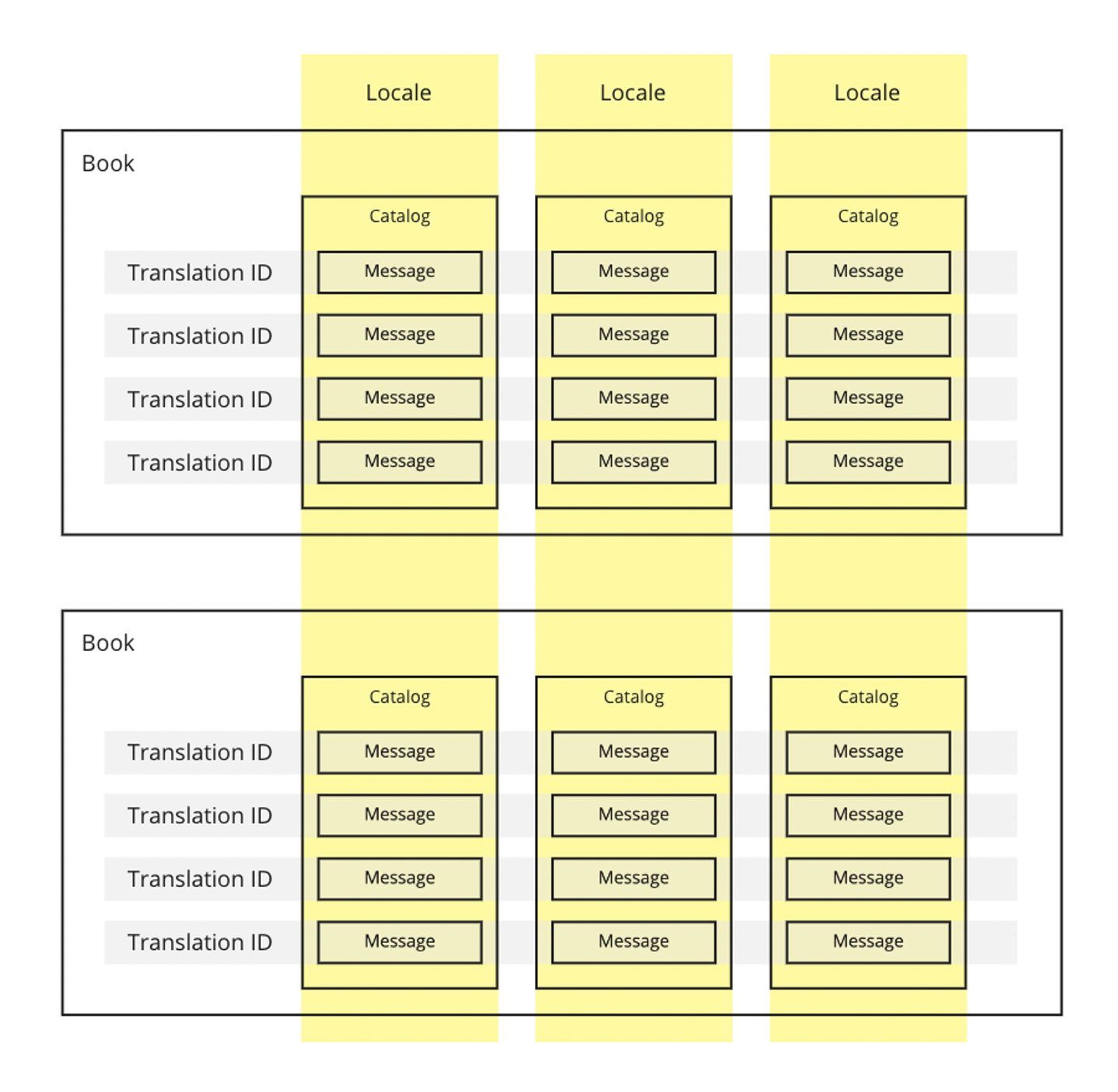
そこでhi18nでは「翻訳カタログを束ねたもの」にブックという名前をつけて以下のような階層性で翻訳データを表現することにしました。
![]()
- Message (メッセージ) は単一の翻訳されたメッセージ。
- Catalog (カタログ) は特定の1言語のメッセージを束ねたデータ。
- Book (ブック) はカタログをサポートされている全言語にわたって束ねたデータ。
この Book > Catalog > Message という階層性に加えて、以下の軸による分類が存在します。
- Translation ID (翻訳ID) はCatalogと直交する (Catalogとは別の視点でMessageを分類する) 。
- Locale (ロケール) はBookやTranslation IDと直交する (これらとは別の視点でMessageを分類する) 。
hi18nでは特別な設定をしなくてもBookのインスタンスを複数持てるようになっています。これは以下のような構成に向いています:
- 翻訳を含むコンポーネントを共通ライブラリとして別のパッケージに切り出す。
- ページごとに翻訳データを分割することで、無関係なページのための翻訳データを読み込まないようにする。
Bookの軸にそってデータを分けるのが簡単なのに対して、Locale軸でデータを分けて読み込み量を減らすには工夫が必要です。これは現時点では実装されていませんが、hi18nの今後の構想には含まれています。
カタログフォーマット
翻訳データをどのような構造で整理するかが確定したところで、これを具体的なデータ形式に落とし込む必要があります。ICUは個々のメッセージのフォーマット (MessageFormat) は規定しているものの、メッセージカタログについては決定版のようなものがありません。
たとえばLinguiJSは複数のカタログフォーマットをサポートしていますが、デフォルトではgettext由来のpo形式を使います。
msgid "Hello, {name}!"
msgstr "こんにちは{name}さん!"
また、Ruby (Rails) のi18nでは階層化されたYAMLファイルに翻訳を書き込んでいきます。
hi18nではこれらの例とは異なり、JavaScript (TypeScript) の内部DSLでカタログを定義します。
export default new Book({
"example/greeting": msg("こんにちは{name}さん!"),
// ...
});
これもまた「ランタイムでできることはランタイムで行う」の原則に由来するものですが、以下のような利点があります。
- 翻訳データのコンパイル処理がなくなることで、更新忘れなどのミスによる手戻りを軽減できる。
- 翻訳データのコンパイル処理がなくなることで、ホットリロード環境での開発サイクルが短くなる。 (翻訳の適用作業をプログラマーが行っている場合)
- TypeScriptの表現力の恩恵をそのまま受けることができる。
一方、内部DSLを使う場合、これを実行環境の外から静的に解析・変更するのは大変になります。
しかし現代のJavaScriptではパーサーを含む静的解析のためのエコシステムが充実しているため、この部分は何とかなります。 (これについては続く記事で説明する予定です)
hi18nの使い方
ここまでの説明を読んで気になった人はぜひhi18nを試してください! READMEにも説明を書いていますが、別記事にて日本語で導入方法を説明しています:
まとめ
Wantedlyで開発中のi18nライブラリである hi18n の設計思想は以下の通りです。
- ICUやLinguiJSなどの既存のエコシステムの優れた部分を引き継ぐが、現代のJavaScript開発環境にそぐわない部分は再設計する。
- 具体的には、あるべきデータをあるべき場所に置く。翻訳データを状態として扱わず、現在のロケールの状態をライブラリ内部に持たない。
- また、できるだけ素朴な実現方法を優先する。ランタイムでできることはランタイムで、型でできることは型で実現し、外部ツールを入れないとできないことは最小限にする。
次回はここまでの設計を実際のライブラリとして実現させるにあたって必要だった実装上の判断やテクニックなどを紹介する予定です。
次に読む
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)



/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)
