/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)



Wantedly, Inc.では一緒に働く仲間を募集しています
- バックエンド / リーダー候補
- PdM
- Webエンジニア(シニア)
- 他19件の職種
- 開発
- ビジネス
こんにちは!Wantedly の Visit の推薦基盤チームでインターンをしている山村です。インターンとしてデータサイエンティストの生産性を向上するための課題を取り組みました。
今回はそれに関して書いていきます。
現在所属している Matching Squard では Github の Issue でプロジェクトの情報を管理していて、
データサイエンティストが、ある推薦アルゴリズムを改良してからユーザの元へリリースすること(以下、これをプロジェクトと呼びます)を行っています。プロジェクトの開始には、大本となる Issue を作成し、その Issue の子 Issue としてプロジェクトの各工程(事前分析、課題定義、実装方針、モデリング、オフライン評価、オンライン評価、リリース etc)の Issue を作成していきます。
ただ、現在のプロジェクトの運用方法では機械的に処理できる形ではないため、データサイエンティストが自身のプロジェクトの詳細を分析・調査するのが困難だという課題があります。具体的には、以下のような課題があります。
課題解決のためのアプローチとして、Issue ドリブンに BigQuery にボトルネックを発見する上で必要となるデータを保存して解析が行えるようにしました。また、Issue ドリブンで行う際に Issue に命名規則のあるラベルを付けることでプロジェクトによってラベルの命名が異なる課題を解決しました。
Wantedly の Matching Squard では プロジェクト開始時に Github の Issue で大本となるプロジェクト Issue を作成してから、その子 Issue を作成して、プロジェクトの各工程などを管理しています。親子というのは何かしらの参照関係でリンクされています。
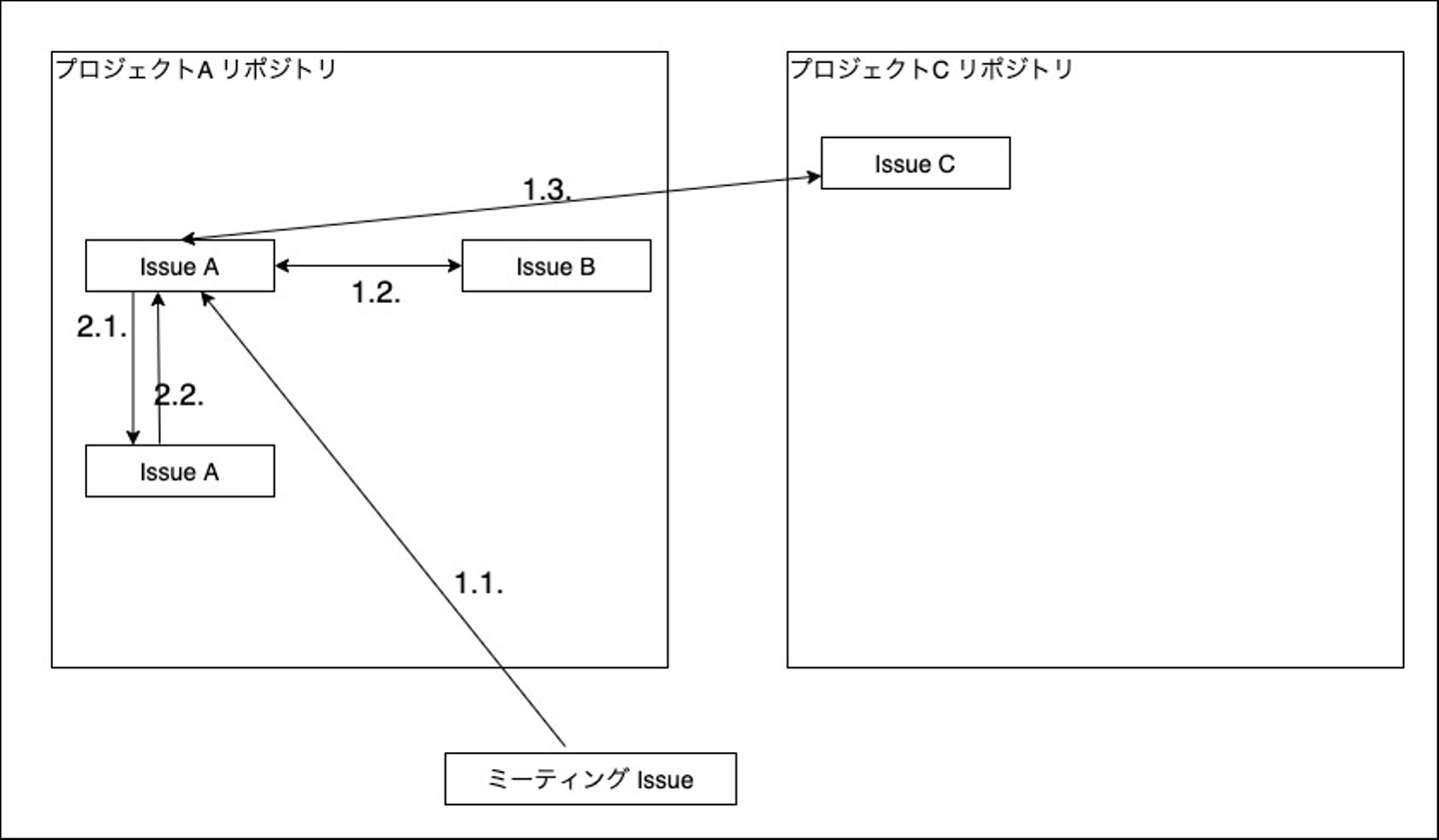
但し、Wantedly の Matching Squard で発生する Issue の参照パターンとしては、以下のようなパターンがあります。
過去のプロジェクトを分析すると、上記のようなパターンがあり、単純参照の Issue なのか親子参照の Issue なのかを分離するのが困難でした。また、プロジェクト毎に親子関係の参照の向きが異なるので、Issue の参照関係から親子関係を取得し、親子関係を保存する方針はボツとなりました。。。。
実装概要
Wantedly の Matching Squard では Github の Issue でプロジェクトの情報を管理していて、本来の Github のラベルを付けるや、IssueやPRを開閉するなどの使い方が、データ収集に向いているので、今回はプロジェクトの大本となる Issue が閉じられたのをトリガーとして、必要なデータを Github Graphql API から取得して、BigQuery に保存します。BigQuery を使用する主な理由としては、Wantedly の Matching Squard では、分析するには BigQuery を用いることが多いからです。
使用手順
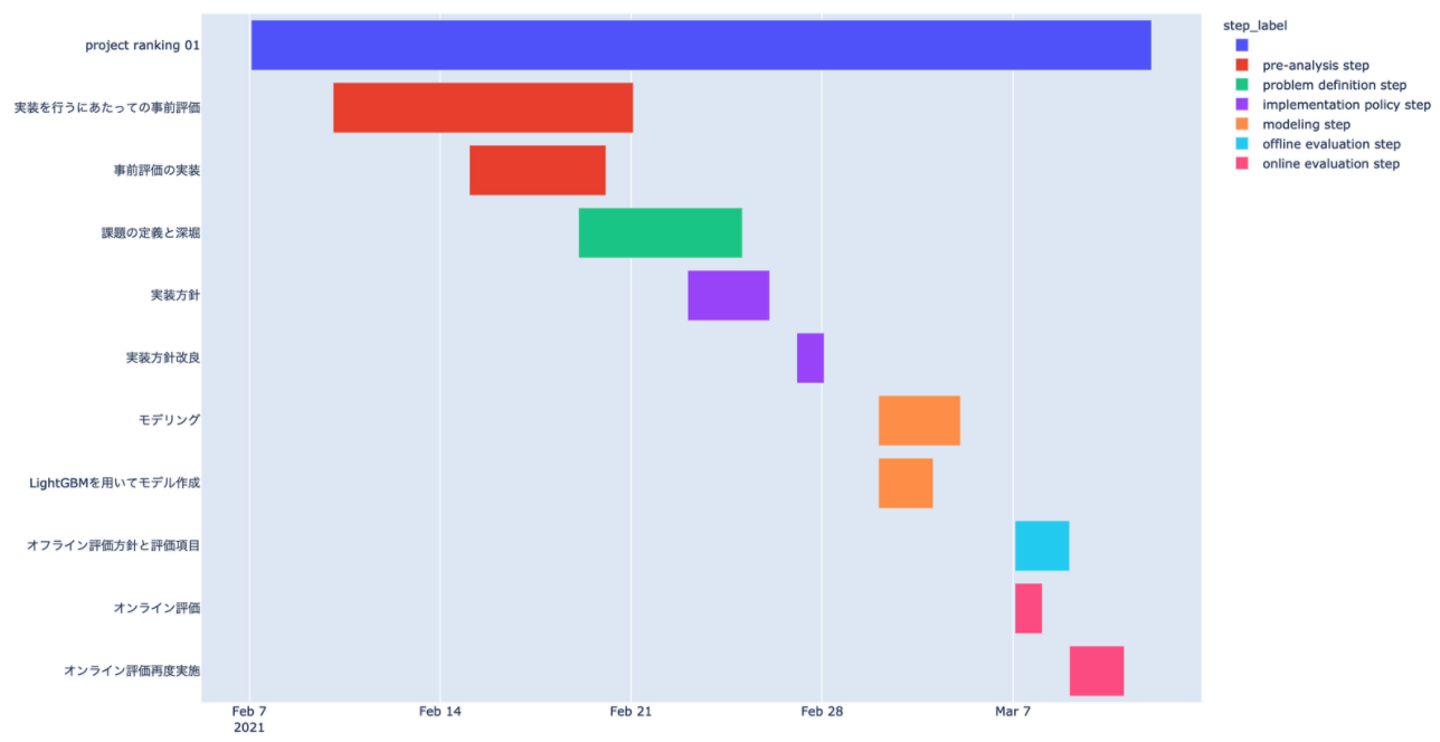
project-ranking-01 のようなプロジェクトの開始が決定wantedly/visit リポジトリ(データサイエンティストのプロジェクト以外にも様々な Issue が作成されるリポジトリ)に大本となるプロジェクト Issue を作成wantedly/visit リポジトリ Issue一覧
wantedly/project-ranking-01リポジトリ Issue一覧
処理手順
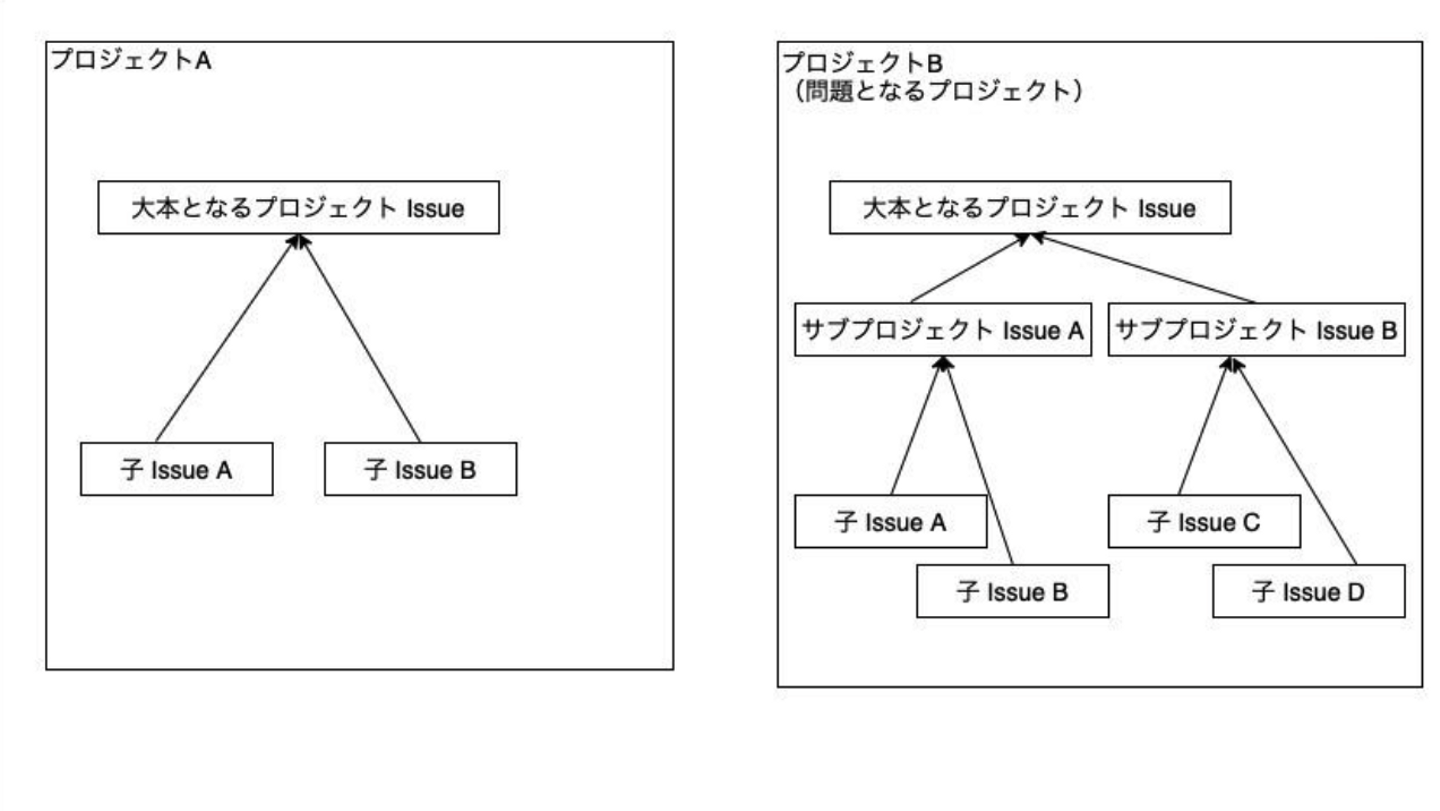
ある程度大きいプロジェクトの場合、大本となるプロジェクト Issue から、いくつかの大本となるプロジェクト Issue と同様の役割を持つサブプロジェクト Issue が作成される場合(右図)があります。
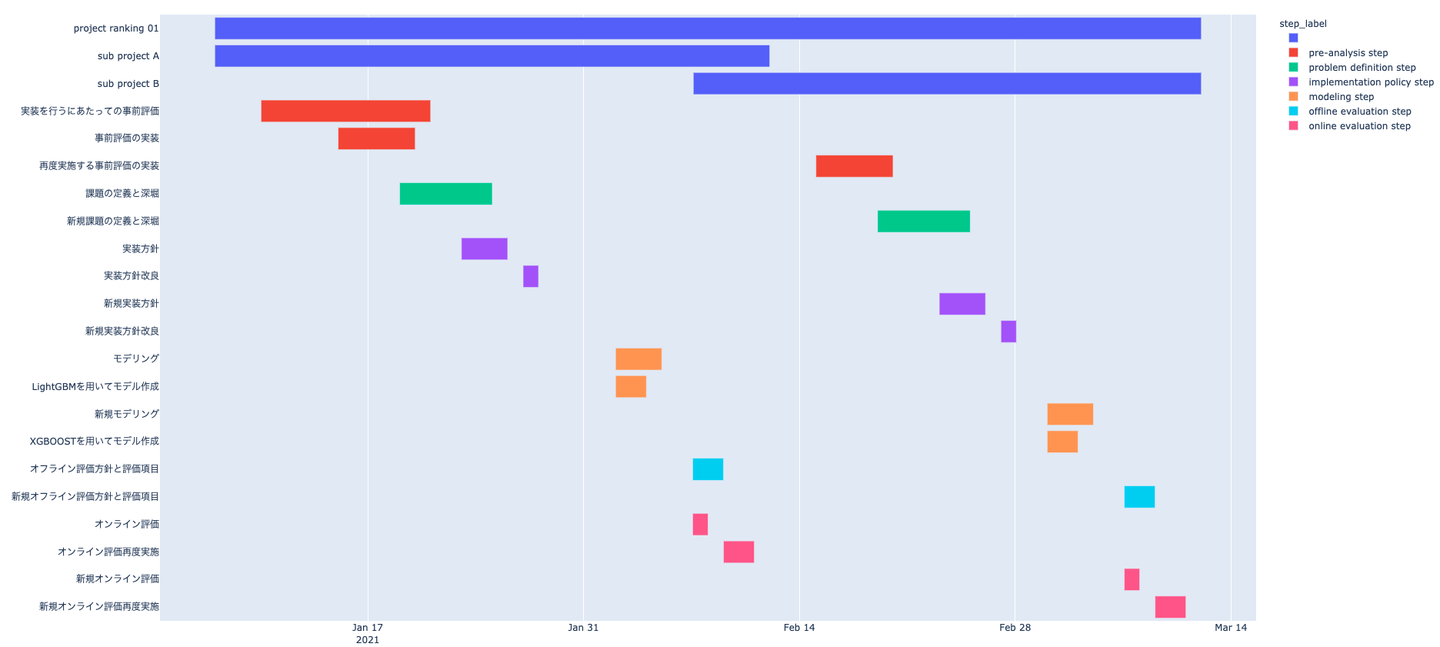
この場合上記のアプローチだと、ガントチャートなどで可視化すると図のようにサブプロジェクトの存在などは自明であるが、BigQueryなどのテーブルデータだけで分析する際に、同じプロジェクトラベルが付けられていて、工程ラベルも同じものが付けられている場合、工程の開始と終了から工程の時間を取ると、長時間各工程を行っていると扱われてしまう問題があります(下図で言えば、 pre-analysis step が1月中頃から2月中頃まで行われたとされる)。
今回は、データサイエンティストの生産性を向上するための課題を取り組みました。
課題としては、
を挙げ、アプローチとしては、Event ドリブンでやりやすい Github Actions を用いて BigQuery に必要なデータを保存する方法を取りました。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

![]()





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)