/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

Wantedly, Inc.では一緒に働く仲間を募集しています
こんにちは、Wantedly People 開発チームの塩津です。趣味でよく色々なツールやライブラリ、言語のソースコードを読んでいます。今回は fzf のスコア計算処理を読んでみたので、備忘録がてら記事にしようと思います。
あいまい検索
皆さんはあいまい検索 (Fuzzy Find) を使っていますか? VSCode などのエディタではファイル検索が大体あいまい検索に対応しているので、何かしらで使ったことのある、または使っている人は多いと思います。
CLI ツールでよく聞くのは peco と fzf でしょうか。ghq との連携でよく紹介されているのを見ます。
僕は検索結果が自分の直感に近いという理由で fzf を使っています。この“直感に近い”というのがどのように実装されているのかふと気になったので調べてみました。
fzf のアルゴリズム
ヘルプを見てみると v1, v2 という2種類のアルゴリズムを選べるようです。
$ fzf -h
...
--algo=TYPE Fuzzy matching algorithm: [v1|v2] (default: v2)
...README では「推奨はしていないが、どうしてもパフォーマンスを優先したい場合はv1を使うと良い」と書いてあります。
それぞれのアルゴリズムについて見ていくことにしましょう。
fzf では検索アルゴリズムについては algo パッケージに全て書かれています。src/algo/algo.go には詳細にコメントが書いてあり、これを読めば大体雰囲気が掴めるようになっています。
v1
algo.FuzzyMatchV1 に実装されています。計算の流れは下記の通りです。
前方から1文字ずつクエリの文字を探していくクエリの最終文字まで見つかったら、後ろに戻りながら一致文字列を決定していくスコア計算
ソースコードのコメントから例を借りますが、例えば "axxbxxabc" という検索対象文字列と "abc" というクエリがあった場合、下記の用に1つずつクエリの文字の出現を判定していきます。最後の文字が見つかったタイミングで探索を打ち切り、先頭方向に向かって一番距離の近い一致箇所を決定していきます。
axxbxxabc
*--*----*>
<***いわゆる貪欲法ですね。探索の計算量は検索対象文字列の長さをnとして、O(n) です。クエリの文字が全て見つからなかった場合はスコア0となります。
とてもシンプルな方法ですがソースのコメントにも書いてあるとおり、この方法では最適な一致文字列が見つからないケースがあります。例えば検索対象文字列が "axxbxxcxabc" だった場合です。この場合、最初に現れる"c"で探索が打ち切られてしまうため、その後に現れる連続した "abc" は一致文字列として扱われません。
axxbxxcxabc
*--*--*>
<*--*--*検索していて連続文字列が優先されない場合があるのは結構嫌なので、こういうこともあって非推奨なのでしょう。
スコア計算
( ここはチューニング項目なので、数値に関しては「大体こんな条件でこれくらいが足されるんだなぁ」くらいの温度感で読んでください。確定数の定義場所はココ。 )
最終的にマッチした文字の数×16ポイントがベースのスコアになります。これにマッチした文字の位置によって下記のようにボーナスポイントが加算されます。
以下のように fzf では Unicode の Letter クラスと Number クラスに属さないような文字を charNonWord として扱っています。
func charClassOfNonAscii(char rune) charClass {
if unicode.IsLower(char) {
return charLower
} else if unicode.IsUpper(char) {
return charUpper
} else if unicode.IsNumber(char) {
return charNumber
} else if unicode.IsLetter(char) {
return charLetter
}
return charNonWord
}fzf では charNonWord で区切ってそれぞれを文字の塊として見ているので、例えば "hoge/piyo" という文字列があった場合 h と p が先頭文字に該当します。
記号等は特別扱いしてるようです。確かに "/" などは階層構造を示していたりするので、ファイル名よりは強めにスコアリングされてほしいですよね。
これも単語の先頭文字を特別扱いするための条件です。snake_case の場合は "_" が charNonWord なので1つ目のボーナス条件に引っかかって加点されます。
その他
ボーナスの項目を見ていると、検索対象文字列を意味のある単位で区切って、それぞれ人間が特別だと感じそうな箇所でマッチしたときに高いポイントが加算されるようになっていますね。
これらのボーナススコアの計算は次に説明する v2 アルゴリズムでも使用されています。
v2
algo.FuzzyMatchV2 で実装されています。v1 とは違い編集距離をもとにスコアを計算します。アルゴリズムは Smith-Waterman 法をベースにしており、fzf では大体以下の式で Matrix が計算されます。H が DP で使う Matrix で、q はクエリ、t は検索対象文字列を示しています。
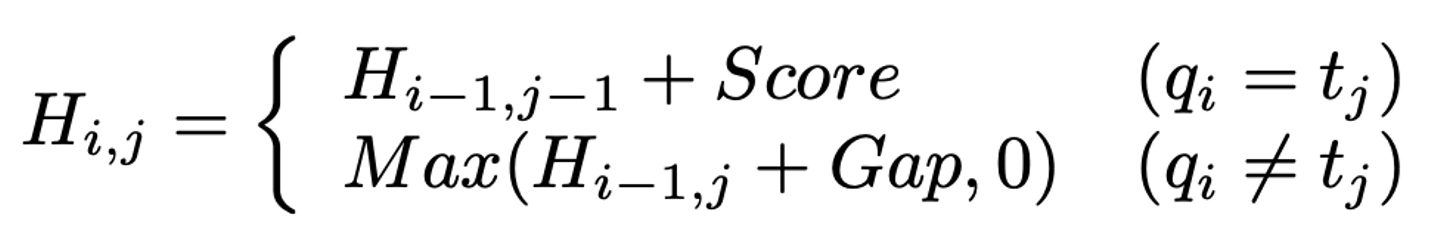
Score は先述したスコア計算に則ってボーナススコアを含めて算出されます。Gap はミスマッチが起き始めたときが-3で、それ以降は-1となります。Matrix の最大値が最終的なスコアになります。
ただし、計算するのはクエリの文字がマッチした区間のみです。例えば検索対象文字列が "github.com/wantedly" でクエリが "wtd" だった場合、実際に計算されるのは "wanted" の区間になります。以下がその計算例です。
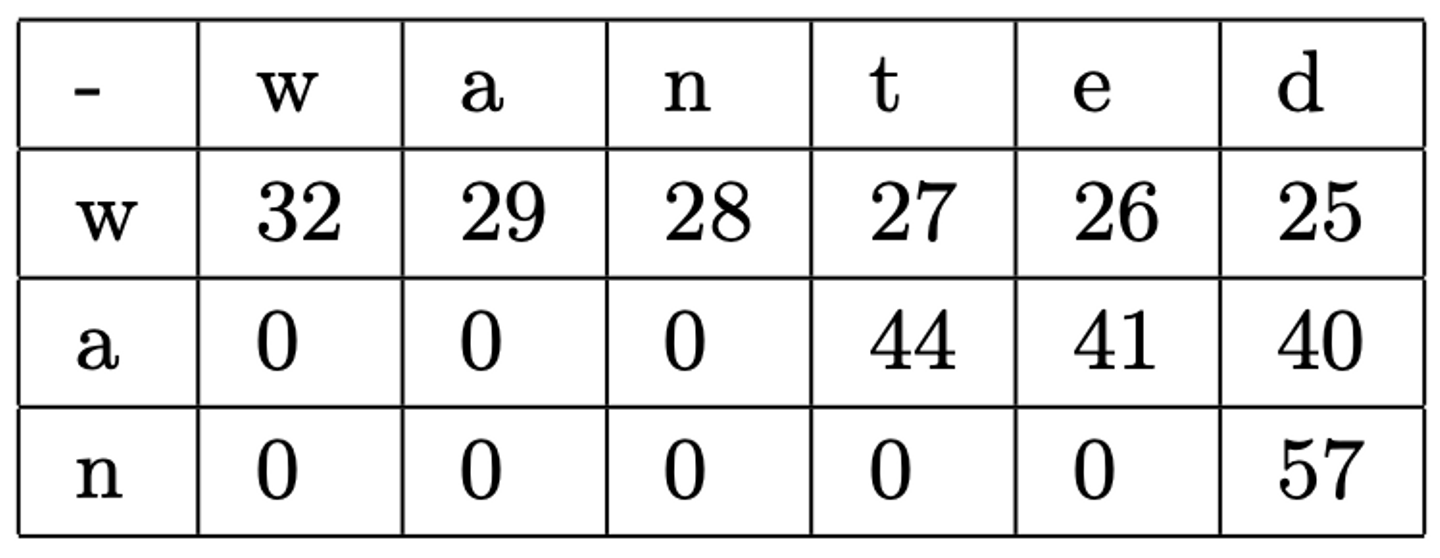
また、検索対象文字列に存在しない文字が含まれていた場合、不一致と判定しスコアを0としています。
計算量は検索対象文字列の長さをm、クエリの長さを n として O(mn) です。
ライブラリとして使ってみる
スコア計算をしている関数は exported なので、import して外部から使うことができます。( fzf 用に作られているため使いやすいかと言われると微妙ですが。)
どちらも algo.Algo の型として振る舞えるように定義されているので一応抽象化とかはできそう...?
以下がそのサンプルです。
package main
import (
"fmt"
"github.com/junegunn/fzf/src/algo"
"github.com/junegunn/fzf/src/util"
)
func main() {
input := util.RunesToChars([]rune("github.com/wantedly/wantedly"))
pattern := []rune("wanwan")
slab := util.MakeSlab(100*1024, 2048)
result, _ := algo.FuzzyMatchV2(false, true, true, &input, pattern, false, slab)
fmt.Printf("Result: %+v\n", result)
}
// go run ./main.go
// Result: {Start:11 End:23 Score:144}slab はパフォーマンスのために事前に確保しておくメモリです。内部でも util.MakeSlab(100*1024, 2048) が使われています。ここで確保している容量を超えた場合、v1 アルゴリズムでスコア計算がされます。クエリと対象文字列の長さをかけ合わせて102,400文字を超えた場合なのであまり無いとは思いますが、長い文字列を対象にスコア計算する場合は注意しましょう。
ちなみに v2 の場合 algo.DEBUG = true にすることで、計算過程の行列が print されるようになっています。
計算後のソート
各検索対象文字列に関するスコアの計算後、結果として表示されるまでにソートが行われます。まずはスコアによるソートが行われ、その後に下記の項目で同じスコアを持つ結果の順番が決められます。
検索対象文字列の長さ (length)最初にマッチした文字の場所 (begin)最後にマッチした文字の場所 (end)検索対象文字列の入力順 (index)
これは --tiebreak で指定することができ、デフォルトでは length のみが有効になっています。
個人的にはこの length でのソートが地味に良く効いていて、自分の直感に近い結果を出力するのに貢献しているのだと思っています。ツールによっては同スコアの場合入力した検索対象文字列の順番どおりに表示されることがあり、結構よく分からない検索結果になってしまい困惑することが多いです。
終わりに
fzf の検索部分の実装を読んでみました。スコア計算とソートの挙動が分かると「こう検索した方が良いのでは?」と思えるので、日々のリポジトリ移動時のタイプ数が1文字くらい減ったのが今回の一番の収穫でした。
インターフェース周りは全く見ていないのですが、丁寧に作られている印象で学びも多そうなので次はこっちを掘り下げてみたいですね。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

Wantedly, Inc.からお誘い
この話題に共感したら、メンバーと話してみませんか?
fzfのスコア計算を読んでみる

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)
