/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

Wantedly, Inc.では一緒に働く仲間を募集しています
こんにちは、Wantedly の Infrastructure Team で Engineer をしている南(@south37)です。
今日は、少し前に自分が取り組んだ「社内の推論スコアデプロイ基盤の扱えるデータ量を 100 倍以上に増やし、スケーラブルな設計に変えた Project」について、取り組み方や得られた学びについてまとめてみたいと思います。
この Project を進める中で、振り返ってみて重要な位置付けとなったのが「Proof of Concept(= PoC)実装の活用」でした。PoC 実装を用意することで、アイディアの実現可能性を素早く検証することが可能となり、さらに設計の議論や認識すり合わせの際にも「動くコード」をベースに具体的なイメージを持って話す事ができました。PoC 実装を上手く活用した事で、Project が成功した好例だと考えています。
この経験をベースに、1つのケーススタディとしてこの Project を振り返ってみたいと思います。
背景 - なぜ推論スコアデプロイ基盤を改善することになったのか
まずはそもそもの背景として、なぜ推論スコアデプロイ基盤を改善することになったのかについて簡単に説明したいと思います。
Wantedly では、プロダクトの様々な部分で「機械学習を利用した推薦」を行っています。「機械学習を利用した推薦」というと簡単そうですが、実際にプロダクトで継続的に機械学習を利用しようとすると様々なことを考える必要があります。
例えば、 Data Lake や Data Warehouse の構築、それらを活用したデータパイプラインの構築、データを利用した機械学習の実行、学習結果の評価、さらに学習結果である Machine Learning Model や推論結果データをデプロイするための基盤といった幅広い領域が、「機械学習のプロダクトへの継続的利用」という文脈で必要となります。こういった「機械学習を継続的に利用するために必要となる幅広い領域の思想およびプラクティス」は MLOps と呼ばれています。MLOps は例えば Wikipedia では以下のように説明されています。
MLOps (a compound of “machine learning” and “operations”) is a practice for collaboration and communication between data scientists and operations professionals to help manage production ML (or deep learning) lifecycle
cf. https://en.wikipedia.org/wiki/MLOps
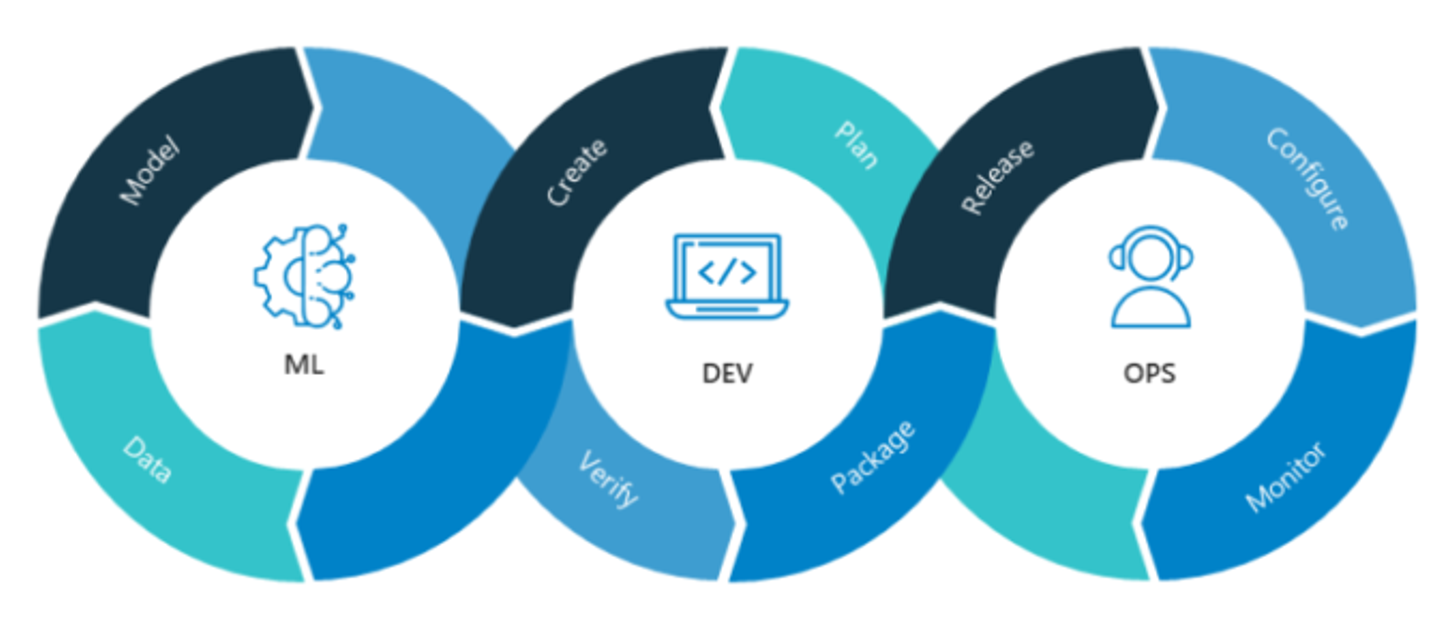
"MLOps の概念図。出典: Neal Analytics"
Wantedly でも、継続的に機械学習をプロダクトで活用するために、MLOps を実現する基盤を整えてきました。その中でも、「推論したスコアのデプロイに利用される基盤マイクロサービス(以下、推論スコアデプロイ基盤)」が存在しており、それが今回の改善対象でした。
この「推論スコアデプロイ基盤」は以下のような設計となっていました。
- 機械学習推論結果である「Score データ」の活用に特化した作りになっている。具体的には、「推薦対象の item ごとの Score」を事前計算して BigQuery に Table として出力しておき、さらに recommendation.yaml と呼ばれる yaml file の内容を書き換えると、「指定した Score でソートした item を API response として返す」という振る舞いが実現される。
- この「BigQuery と recommendation.yaml の組み合わせ」が Data Scientist にとって「推論スコアデプロイ基盤を利用する際の Interface」となっており、デプロイ作業を Data Scientist だけで行う事が出来るようになっている。具体的には、「BigQuery に Score を出力して、yaml の内容を更新する PR を作る」という事だけをやれば良い。
- recommendation.yaml は「request parameter に応じて適用する Score を変える、複数の Score を足し合わせた Score を適用する」などのある程度複雑なロジックを記述出来るようになっている。その為、Data Scientist が考えるロジックの大部分はカバー出来るようになっている。
- カバー出来ないロジックが出てきたときだけ、Backend Engineer が協力して追加でコードを書く、という運用になっている。
recommendation.yaml は例えば以下のような file です。type として if, or, append, leaf などを選べるようになっており、これによってロジックを組み立てる事ができます。計算グラフの node を1つ1つ記述しているようなものと思ってもらって良いでしょう。
# recommendation.yaml
- name: Ranking
type: if
condition: isXXX
children:
- XXXRanking
- YYYRanking
- name: XXXRanking
type: or
children:
- ZZZRanking
- NormalRanking
- name: ZZZRanking
type: leaf
- name: NormalRanking
type: append
children:
- PersonalizedRanking
- DefaultRanking
...
この推論スコアデプロイ基盤は、Data Scientist にとって 「推薦スコアのデプロイを自分たちでコントロールする形で進められる」という意味でとても素晴らしいものでした。
一般に、機械学習をプロダクトで活用する際には、どうしても「学習結果のデプロイまでに時間がかかる」、「デプロイに Backend Engineer が関わる事で、クオリティコントロールが難しくなる」、「継続的な更新の実現方法を考える必要がある」などが難しさとして出てきます。この「推論スコアデプロイ基盤」はそれらの問題を解決するものとして作られています。
もちろん、「Score を事前計算する」という前提をおいているために「実行時の推論が出来ない」などの制約はあるものの、Data Scientist からは上手く活用される基盤となっており、機械学習結果の改善サイクルも上手く回っていました。
しかし、推論スコアデプロイ基盤はその内部実装の都合上、「1つの Redis instance に filtering と sort に利用する全てのデータを載せなければいけない」という作りになっており、その設計が「扱える Score データのサイズを制限してしまう」という致命的な問題がありました。これが今回の Project が始まった根本の問題意識です。
この「内部実装とそれによる課題」については、次のセクションでもう少し掘り下げて説明したいと思います。
推薦スコアデプロイ基盤の元々の実装と当時の課題
推論スコアデプロイ基盤は、実装としては以下のようなものになっていました。
- Go で記述された gRPC server として実装されている。「parameter を受け取り、Score 順にソートされた item のリストを response として返す endpoint」を持っており、他のマイクロサービスからはその endpoint が利用される。
- 前述した recommendation.yaml は Go のコード生成に利用される。具体的には、if, or, append, leaf などの type は対応する Go のコードに変換されて、実行される。
- 内部では Searcher と呼ばれる struct が計算グラフの node となっており、この Searcher を組み合わせる処理が buildSearcher と呼ばれる自動生成された関数で実行される。
- Searcher は内部では Redis の Sorted Set と呼ばれるデータ型に極めて依存した設計となっている。Searcher
は内部で lister と呼ばれる「Redis の Sorted Set と1対1対応した struct」を利用しており、lister 同士の intersection 操作 や union 操作を実行する事で filtering や sort などの機能を提供している。 - lister の内部実装としては、 Redis の ZINTERSTORE や ZUNIONSTORE という命令が利用されている。
- 事前計算して BigTable に出力した Score データは Redis に Sorted Set として保存されるようになっており、Go コード中では「1つ1つの Sorted Set に1対1対応する lister」が利用される。「Searcher に対してどの lister が利用されているか」という情報は、strategy と呼ばれる struct で表現される。具体的には、Searcher -> strategy -> lister という依存関係となっている。
少しコードも見てみましょう。buildSearcher 関数は build_searcher.generated.go という自動生成された file の中で定義されています。例えば以下のような内容となっています(注: 引数が多いので、context 以外は ... として省略しています)
// build_searcher.generated.go
// Code generated by `go run xxx`. DO NOT EDIT.
package server
import (
...
)
func buildSearcher(ctx context.Context, ...) (search.Searcher, error) {
searcher, err := buildRanking(ctx, ...)
return searcher, fail.Wrap(err)
}
func buildRanking(ctx context.Context, ...) (search.Searcher, error) {
var searcher search.Searcher
var err error
isXXX, err := registry.IsXXX(ctx, q)
if err != nil {
return nil, fail.Wrap(err)
}
if isXXX {
searcher, err = buildXXXRanking(ctx, ...)
if err != nil {
return nil, fail.Wrap(err)
}
} else {
searcher, err = buildYYYlRanking(ctx, ...)
if err != nil {
return nil, fail.Wrap(err)
}
}
return searcher, nil
}
.
.
.
この実装を踏まえた上で、当時の推論スコアデプロイ基盤のアーキテクチャを模式的に書くと次の図のようなものになります。Searcher がそれぞれ lister を保持していて、それが全て1つの Redis を共通で参照している事が分かります。
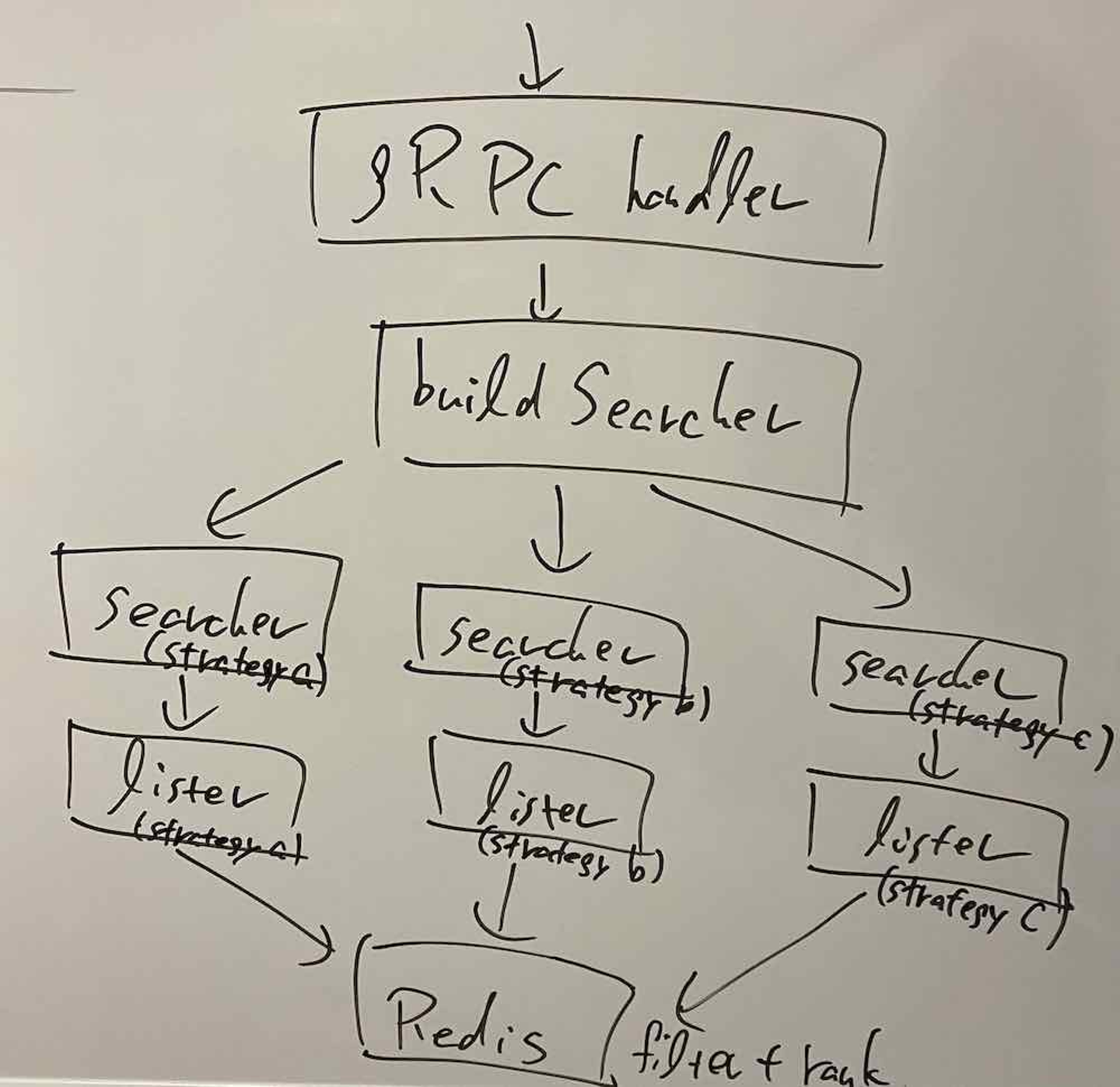
"推論スコアデプロイ基盤のアーキテクチャの模式図"
この推論スコアデプロイ基盤のアーキテクチャは、以下のような課題を持っていました。
- Redis の Sorted Set 機能にかなり依存しており、「1つの Redis instance の内部に全てのデータを保持する必要がある」という設計になっていた。これにより、以下のような様々な課題があった。
- 1つの Redis instance の memory 使用量には限界があるため、スケーラビリティに限界が存在。また、その限界が既に目の前に迫っていた。具体的には、その時点の Redis の memory 使用量が 40GB 程度。ElastiCache の最大 instance の memory size が 600GB 強であるため、memory 使用量はせいぜい 10 倍程度にしか増やせない状態だった。
- 「filtering のためのデータ」と「sort のための Score データ」が混ざっており、どちらがどのくらいのサイズになっているかも分からない 状態だった。そのために、sort のための Score データを10倍に増やすと memory の限界に来てしまうのでは?という懸念が存在した。
- filtering のためのデータは、「request パターン」に応じてダイナミックに増減するキャッシュ的な側面を持っており、利用頻度の低いものは LRU で evict したい。一方で、sort のための Score データは evict されると困る。「性質の違うデータ」が1つの Redis instance に混在することで、扱いを難しくしていた。
上記でいくつか挙げた課題のうち、特に致命的だったのは「1 つの Redis instance を前提としているためにスケーラビリティに限界がある」という部分で、これから推論の対象 pattern 数を増やしてアクセルを踏もうとしてる段階でこれは致命的でした。
そこで、「その時点での限界を超えられるアーキテクチャ」へと推論スコアデプロイ基盤を作り変える事にしました。これが、Project を始めた経緯です。
ここからは、実際に Project を進めた際の様子について、時系列の step 順で振り返ってみたいと思います。
- 前提条件の把握
- アーキテクチャの検討
- PoC 実装
- 本実装
コラム: Redis の eviction policy の設定について
課題として最後に挙げた「性質の違うデータの混在」という部分については、実は Redis では「TTL が設定されている key だけを evict 対象にする eviction policy 設定」が可能であり、実際に我々はその設定を利用していました。しかし、以下に引用するように Redis のドキュメントではこの設定は推奨されておらず、可能であれば「evict 前提のデータ」と「evict させない前提のデータ」は分けて別 instance で管理したいと考えていました。
The volatile-lru and volatile-random policies are mainly useful when you want to use a single instance for both caching and to have a set of persistent keys. However it is usually a better idea to run two Redis instances to solve such a problem.
cf. https://redis.io/topics/lru-cache#eviction-policies
step 1. 前提条件の把握
まず最初に行ったのは、「前提条件の把握」です。すなわち、ステークホルダーである「Data Scientist」や「推薦デプロイ基盤の Ownership を持つ開発者」を集めて、何が「制約」として存在しており、何が「ゴール」なのかのすり合わせを行いました。そして、以下のような機能要件・非機能要件を明らかにしました。
機能要件:
- Data Scientist から見た体験は基本的に変えない
- これが大きく変わると、Data Scientist の生産性が一時的に落ちると予想されるため。もちろん、この部分の変更も場合によっては検討する。
- gRPC server としての振る舞いも基本的に変えない
- protobuf で記述された Interface を変えず、あくまで内部実装の変更として完結させる
非機能要件:
- その時点での限界値を超えて、100倍以上にデータサイズを増やせるようにする
- 具体的には、その時点で数万パターンの Score データを保持して 40GB 程度の memory 使用量だったので、そこから数百万パターンまで増やせることをゴールとした
- latency の増加は 100ms 程度に抑える
- 実装やデータベースの変更によって latency が増加する可能性は考えられたので、あらかじめ「どのくらいの値であれば許容出来るか」を明らかにしておいた
- ElastiCache の利用料金などのデータベースコストは一旦無視するが、「コストを考えて後からデータベースを差し替える」などが可能な構成にする
要件には入ってないが、preferred なもの:
- この時点では推論スコアデプロイ基盤は「事前計算した Score データ」のみを利用する前提だったが、将来的に「ML model を利用した Inference を実行時に行う(= Inference Server を利用する)」という選択肢も取れるようにする
- 推論対象の item 数が増えると、事前計算が現実的でなくなる時が来るはず。その時を見越した考え。
また、判断のために必要な重要な情報としては、以下を前提として共有してもらいました。
- 推薦対象の item 数は、ざっくり10万件程度
- id は int64, score は float64 として、圧縮などが何もなければデータサイズは 64bit * 2 * 100,000 = 1.6MB 程度
- 推薦対象の item 数はさほど多くない代わりに、「パターン数」が多かった。具体的には、「検索したキーワードに応じて、異なる Score を適用する」、「検索を行ったユーザーに応じて、異なる Score を適用する」などをやっていたので、その数だけ「Score のパターン」が増えるようになっていた。
- だいたい約1万パターンとして、1.6MB * 10,000 = 16GB 程度。実際、 memory 使用量はこのくらいのオーダーになっていた。
- このパターン数を100倍以上に増やしたいというのが、今回のプロジェクトを開始した根本の問題意識。
これらの情報をもとに、アーキテクチャを検討することにしました。
step 2. アーキテクチャの検討
次に、step 1 で明らかにした「制約とゴール」を元に、いくつかのアーキテクチャを検討しました。この時点では、ざっくり以下の2つを方針として検討していました。
方針A. 既存の実装を最大限残しつつ、スコア付け専用のマイクロサービス(= Score Microservice)をスケーラブルな形で用意する
検討した方針のうち1つは、「既存の実装を最大限残しつつ Score Microservice を新しく用意する」というものです。具体的には、既存の「Redis の Sorted Set を利用した filtering + sort」という処理の中で、sort の部分で「他のマイクロサービスに問い合わせた Score データを小さい TTL で Redis に保存し、それを利用して Redis の機能で sort」を行うということを考えていました。
この方針の Pros/Cons をまとめると次のようになります。
- Pros:
- 既存の実装を最大限活用出来るので、追加実装量が少ない。開発コストが小さい ことが予想される。
- Cons:
- マイクロサービス間通信の latency が overhead として挟まる。latency 増加量が許容範囲に収まるかを調べる必要あり。
- Reids の Sorted Set へ Score データを保存する latency も overehead として挟まる
- スコア付け専用のマイクロサービスの内部実装をどうするかは別途考える必要がある
- 大量の pattern のデータを扱うので、「sort 時に動的に保存する Score データの TTL」を上手く調整しなければ、簡単に memory 使用量が限界に達してしまう。また、memory 使用量が限界に達すると evict が走る事になるが、1つの Redis instance 上で filtering のためのデータと sort のためのデータが混ざっているために「evict 対象としてどの key を選ぶべきか」があまり自明ではない。
方針Aのアーキテクチャを模式的に図示すると、下図のようなものになります。
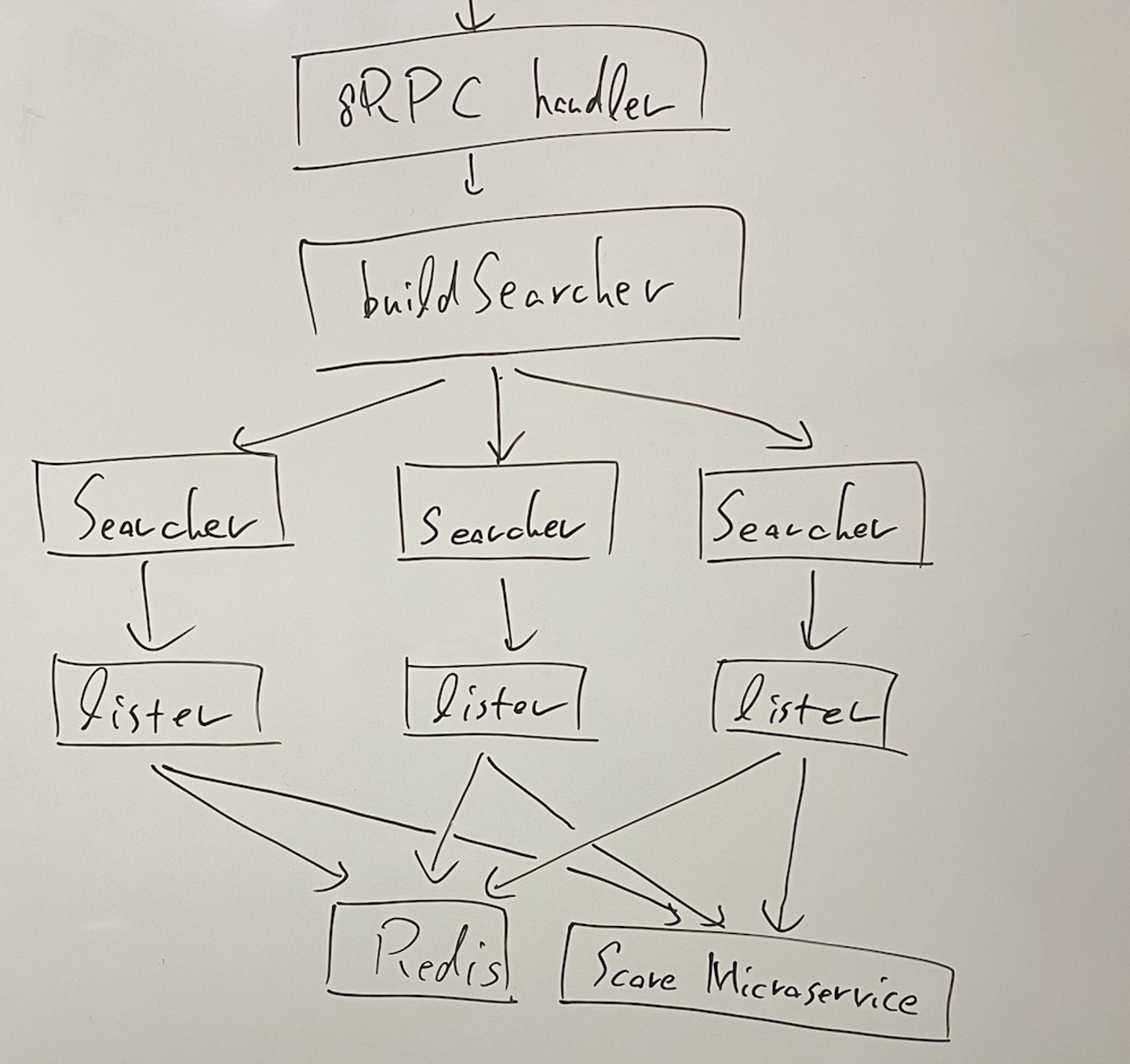
"推論スコアデプロイ基盤で検討した方針Aのアーキテクチャ模式図"
方針B. 既存の実装に大きく手を入れて、sort の仕組みを変える
検討した方針のうち2つめは、「既存の実装に大きく手を入れて、sort の仕組みを作り替える」というものです。具体的には、「filtering だけを行う処理(= filterer の処理)」と「sort だけを行う処理(= ranker の処理)」を完全にコードベースとして分離して、「sort だけを行う処理」はスケーラブルなものに差し替えられるようにするというものです。実際の sort 処理の内部実装としては「KVS から id, score を取り出し、それに基づいて sort した状態で値を返す」のが有力候補でした。
この方針の Pros/Cons をまとめると次のようになります。
- Pros:
- sort 部分で Redis への依存を無くせるので、Bigtable のようなスケーラブルな KVS を選択できるようになる。Redis を使う場合でも、Sorted Set を利用しなくなるので sharding などのスケーラブルな構成が選択できるようになる。
- filtering 部分と sort 部分が完全に分離出来るので、「filtering 部分の処理は独立した Redis を利用して、適切な eviction policy を設定する」ということが可能になる
- sort 部分は「id を受け取って、score で sort して返す」というシンプルな Interface にすることで、他の実装にも差し替え可能。具体的には、「将来 inference server を利用したい」と思う時が来たとしても対応可能である。
- Cons:
- 既存の実装では想定していなかった振る舞いなので、コードベースを大きく書き換える必要がある。開発コストが大きい ことが予想される。
方針Bのアーキテクチャを模式的に図示すると、下図のようなものになります。
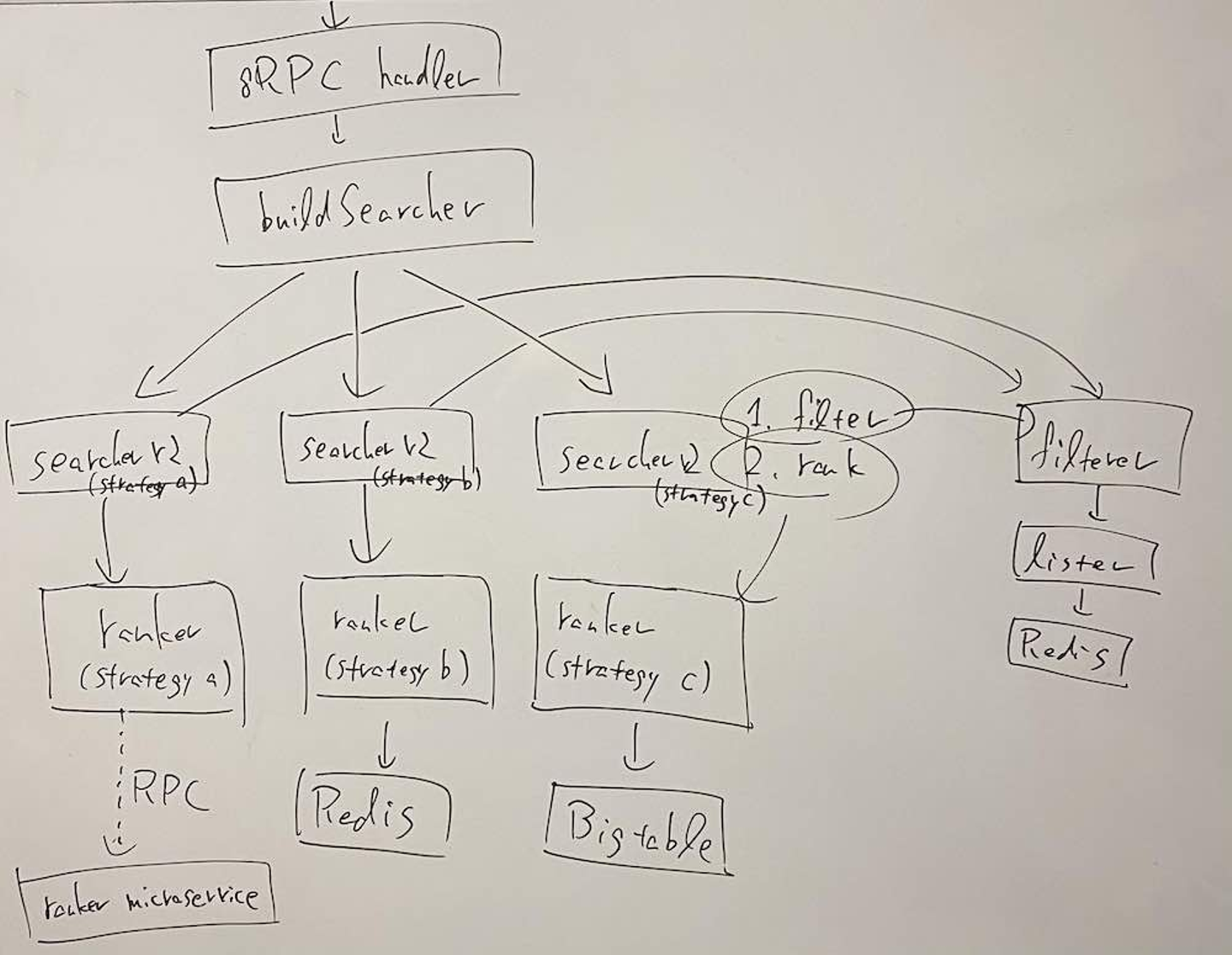
"推論スコアデプロイ基盤で検討した方針Bのアーキテクチャ模式図"
上記の方針はどちらも Pros/Cons があり、一概に「こちらが良い」と言えるものではないと感じていました。強いて言えば、「方針Aはコードとしての実現可能性は高いがパフォーマンス上のリスクが大きい、方針Bは設計が大きく変わるのでよく考える必要はあるがパフォーマンス上のリスクは小さい」という想定をしていたように思います。
なお、両方の方針に共通する部分として、「将来、Inference Server を利用したくなった時にそれが実現可能である」という特徴も兼ね備えています。これは Required な要件ではありませんでしたが、これを見越した設計にしておくことにデメリットは無いと判断して、ある程度考慮しています。
最初に方針を考えた時点では、上記の方針はどちらも、理論的には実現し得る構成だと思ってました。例えば、方針 A では 1.6MB のデータをマイクロサービス間でやり取りする必要がありますが、以下のような概算で「latency 増加は数十 ms 程度に抑えられるのでは」と期待してました。
- "Latency numbers every programmer should know" に記載された `Send 1 KB bytes over 1 Gbps network: 10 us` という数字を参考にすると、1.6MB 程度なら 16ms で通信できるはず
しかしながら、机上の空論を避けるためには「実際に動かしてみる」のが最も手っ取り早いのも事実です。そこで、それぞれの方針ごとに PoC 実装を作成して、「本番環境と同等のデータ」および「本番環境の 100 倍のデータ」を保存した状態でパフォーマンス計測などを含めた検証を行うことにました。
step 3. PoC 実装
PoC 実装としては、それぞれの方針ごとに「実現可能性を検証できる最小限の実装」を行うようにしました。この時点では「package の切り方、interface の設計、testable な設計」などは気にせず、あくまで「それぞれの方針にどういった実装が必要になるかの実験、および latency や memory 使用量が要件を満たすかの確認」に注力するようにしています。それぞれ branch を切って数日程度で実装して、計測を行いました。
PoC の結果、予想に反して以下のことが分かりました。
- 方針 A は latency の overhead が予想以上に大きいと判明
- protobuf binary の encode/decode の latency が予想以上に大きかった。具体的には、「int64,float64の2つを field として持つ message」を用意して、さらに「それを 10 万件 repeated で持つ message」を response として利用したところ、encode/decode に 44ms かかる事が判明。gRPC interceptor が挟まる状況ではこの encode/decode が何度も行われるためか、RPC 全体の latency は 数100ms まで増加した。
- 逆に、全ての gRPC interceptor を無効にした上で「repeated fixed64 と repeated floa64 を field として持つ protobuf message」を利用した場合には、encode/decode は 1ms 以内で終わり、RPC 全体の latency も 24ms 程度に収まることも判明。これは、前述した理論限界とも近い値で、「これ以上高速化は難しい」と思われる。ただし、この状態で「Wantedly が Observability などの観点から最低限利用したい gRPC interceptor」を適用した場合には、再び 180ms まで latency が増えてしまった。
- Redis の Sorted Set へのデータ保存も約 300ms かかると分かり、予想以上に大きな latency だと判明した。
- 方針 B は逆にほとんど overhead 無く動作すると判明
- Redis には Sorted Set ではなく「repeated fixed64 と repeated floa64 を field として持つ protobuf message の binary format」を保存するようにした。1.6MB 程度のデータのやり取りであっても、Redis とのやり取りは 10ms 前後という小さな latency で行えると確かめられた。なお、実は方針 B においても当初は Redis の Sorted Set を利用して保存・取得を行っていたが、それでは Redis からのデータ取得 latency が 60ms ほどとなっていたことから、「protobuf binary を利用した保存・取得」に切り替えた。それによって、データ取得の latency が 10ms 前後まで高速化した。
- データの保存形式を protobuf binary に変えたことで「Score データによる Redis の memory 使用量」を 3 分の 1 以下まで削減できた。memory 使用量が抑えられたことで、100倍の Score データを1つの Redis instance に保存する事ができるようになり、sharding を検討せずに済んだ。実際に 100 倍の Score データを保存して検証した際も、latency 劣化は 15-20ms 程度で収まると確かめられた。具体的には、Score データの memory 使用量は Sorted Set では 11GB 程度で、それが 3GB 弱まで減少した。そのため、100 倍に増やしても memory 使用量は 300GB 程度であり、1つの Redis instance に収まるサイズになった。
- この PoC 実装によって、「方針 B を選んだ際にコードの書き換えとして何が必要になるか」の見通しを立てる事が可能となり、現実的な開発量で済むことも確かめられた。
上記の結果は、方針 A は「Redis の Sorted Set へのデータ保存の latency」が大きくて「latency 増加を 100ms に抑える」という制約を破ってしまうこと、逆に方針 B は latency の問題が無いことを意味します。上記の結果を踏まえて、「方針B」を本実装として採用する事にしました。
step 4. 本実装
PoC のおかげで「最終形」は見えています。また、「現状」も分かっています。そのため、考えるべきことは「最終形に向けてどのように段階的に移行するか」ということだけでした。
この部分については、実はネックとなるのは「Score データの保存型式の変更」くらいだったので、以下のような手順で進めました。
- 「Score データを Redis に保存する処理」に手を入れて、「旧バージョンのデータ」と「新バージョンのデータ」の両方を保存する実装に変える。ただし、「新バージョンのデータ」は「Score データ専用に新しく用意した Redis instance」に保存するようにする。
- しばらく時間をおき、Redis へのデータ保存が hourly や daily の batch 処理によって行われるのを待つ
- 「新バージョンのデータ」を利用する実装をデプロイしてリリース
- 「旧バージョンのデータ」が使われなくなったことを確認したら、そのデータを削除
なお、これらの過程では実際にはリスクを抑えるためにフラグを利用した段階的デプロイなどを行っています。しかしながら、大筋の流れはこのような形です。フラグでリスクを上手くコントロールしつつ、素早く開発してリリースする事ができました。
振り返ってみてのまとめ
「社内の推論スコアデプロイ基盤の扱えるデータ量を 100 倍以上に増やし、スケーラブルな設計に変える Project」について、取り組みを紹介しました。
振り返ってみると、PoC 実装が以下の観点からとても役立ったと考えています。
- PoC 実装を行う事で、「選択したアーキテクチャの限界」を素早く見極めて、それによって適切なアーキテクチャを素早く判断する事が出来た
- 理論限界だけでは見えない情報を集める事ができた。具体的には、実際に PoC 実装を作成して試してみる事で、「protobuf binary の encode/decode の latency」や「gRPC interceptor による latency」、「Redis の Sorted Set へ大量にデータを保存する処理の latency」など当初予想していなかった形で大きな latency が生まれる事が分かった。
- PoC 実装という形をとることで、数日程度で素早くアイディアを試す事が出来た。最初から「適切な interface 設計や package 分割、testable な構成」などを考えながら実装するとその分だけ時間がかかり、さらに「時間をかけて作ったものが要件を満たさないと後々判明する」などが起こり得る。そういった事態を避けて、素早く「実現可能性の検証」ができた。
- アーキテクチャの選択を「現実の数字」を元に行えたので、「推測に基づいて発言して議論が紛糾する」こともなかった
- PoC 実装が「最終形」として念頭にあるので、設計の議論や実装、レビューを効率的に行う事ができた
- 「適切な interface 設計や package 分割、testable な構成」について考える際に、具体的なレベルで目線を合わせて議論が出来た
- コードレビューの際も、「最終形の振る舞いやそのために必要な各部品の振る舞いがちゃんと実現できているか」という観点でチェックすることが出来た。
- 最終的に「推論スコアデプロイ基盤」自体のクオリティ向上にも寄与した
- 「本実装を始めてから予想外の事が判明して路線変更する」という事がなかったので、無理のない設計およびコードになった
- PoC 段階で、パフォーマンス向上のための変更をいくつか行う事ができた。
- 「求められた要件」と「将来の拡張性」を兼ね備える良いものになった
このように、今回の Project は PoC 実装を上手く活用出来た好例だと考えています。あくまで一例ではありますが、ケーススタディとして参考になりましたら幸いです。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

Wantedly, Inc.からお誘い
この話題に共感したら、メンバーと話してみませんか?
PoC 活用のすすめ - 社内の推論スコアデプロイ基盤を100倍以上スケーラブルにした話

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)
