ウォンテッドリーのデータサイエンティストの合田です. 弊社のデータ系メンバーによる RecSys 2020 の参加報告連載のトリを努めさせて頂きます. カバー画像は四万十川の佐田沈下橋です.
これまでの参加記事は以下をご参照ください.
本記事では私が現在関心を持っている推薦システムのオフライン評価について, RecSys 2020 のプレゼンのうち, オフライン評価に関連していてかつ個人的に興味のあった内容を抜き出して紹介します.
0. 何故オフライン評価に関心があるのか 論文紹介の前に, 私がオフライン評価を重要視している理由を説明します. ウォンテッドリーでは推薦システムによって良いユーザ体験を提供することに重点を置いています. 元々は少数のメンバーによって推薦システムの運用が行われていましたが, 去年から私含めて複数人のデータサイエンティストが加わり, 推薦による効果が特に大きい箇所への, より賢い推薦の導入・改善に力を入れてきました. そして今後も良い推薦を提供し続けていくために重要となるのはオフライン評価だと考えています.
こう考える理由は2つあります. 1つ目は, 継続的な改善の結果として昔に比べて改善の幅が小さくなっており, ベースラインからのモデルの改善度合いを正しくかつ高分解能で測定する必要が増しているからです. オフライン評価はモデルをより良いものにしていくための方向を示す羅針盤であり, この設計が誤っていると取り組んだことが無駄になってしまう恐れがあります.
2つ目は, これまでチームとして培ってきた技術資産・経験によって新しいことにチャレンジできるようになっているので, 今までプロダクトになかった新しい体験(推薦)の形をユーザに届けたいと考えているからです. そのためにはユーザに提供したい理想的な推薦を定義し, その定義を満たすようにランキングが作成されているか確認する必要がありますが, 中には測定することが難しいケースもあります. このような場合は定性的にチェックしますが, 定性評価にも限界があります. 少ないサンプルしか見れないので全体的な規模感がわからない上, その観点での性能劣化を逃さないためのモニタリングがいずれにしろ必要となるため, ちゃんと見たい指標を定義して定量評価できるようになることが必要です.
以上から, 正しい評価設計を行える技術を身につけ効果的な推薦の最短で継続的にユーザに提供し続けたいと思い, オフライン評価に対する関心が高くなっています.
1. 何故オフライン評価が重要なのか 今回の RecSys 2020 のいくつかの発表では, オフライン評価の重要性について語られています.
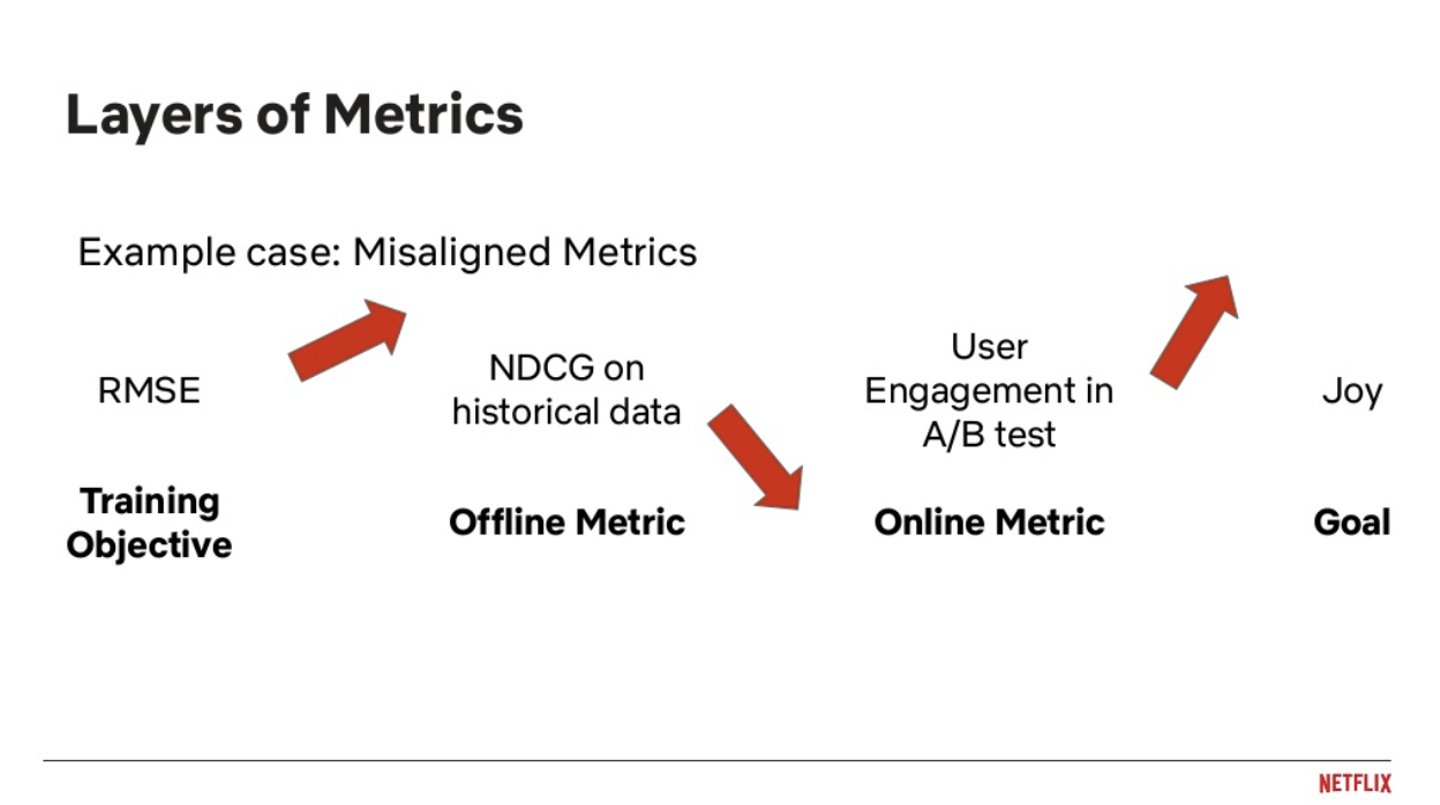
Netflixによるスポンサーセッションでは, Personalizationに関連する要素のうち近年話題になっているものをピックアップして, 要素ごとに概要と課題について紹介しています. このトレンドの一つである「Objectives」では, 推薦システムをプロダクションに出すまでに通過しないといけない「モデルの学習」, 「オフライン評価」, 「オンライン評価」というフェイズごとに適切な指標を置くことの難しさを話しています.
理想的には推薦システムをリリースして達成したいことをそのまま指標として置けば済む話なのですが, 現実的には難しい問題です. 例えば, User Engagementの促進を目的とした取り組みの場合, モデルの学習時の目的変数としてRMSE, オフライン評価には過去のログデータを使ったNDCG, オンライン評価ではA/BテストでのUser Engagementを測定することになります.
私たちは自身が設定したメトリクスでしか, システムの良さを測ることができません. このObjectiveの課題の1つとして紹介されている「 Ways of measuring improvements offline before going to A/B test ? 」という言葉の通り, A/Bテストをプロダクション環境で実施する前にモデルの性能をより近似的に評価できるような手段を模索していく必要があります.
2. オフライン評価に関連する要素とは オフライン評価を正しくするといっても, オフライン評価に関連しているものを把握しなければ改善のアプローチが見えません. あくまで私個人の意見になりますが, オフライン評価をするに到るまでの全ての要素がオフライン評価に紐づいていて, それらに関する課題を抽出した上での改善をしていかなければいけないと考えています. 網羅的に把握して紹介するのは無理なので, ここでは関連要素の一例を紹介したいと思います.
このKeynote では, 検索・推薦システムに関わるバイアスの種類とその影響について話されています. 詳細は 石崎のレポート にまとめられているので, ここではざっくり紹介するだけに留めます.
このKeynoteではバイアスを以下の3つに分類しています. 正しいオフライン評価をするためには文化的バイアスや認知バイアスを把握することは勿論のこと, よりテクニカルなものとして統計的バイアスを考慮する必要があります. 学習データや検証データの収集過程・サンプリングから, ラベリングの正確性, spamなどの除外するべきログの把握, 推薦されたアイテムの位置によって生じるバイアス(position bias), ログに残るのはユーザがインタラクションしたアイテムだけというバイアス(interaction bias) などがオフライン評価の正しさに依存します. オフライン評価はすでに存在するログデータを使って評価することなので, ログに含まれているバイアスをうまく取り除く必要があります.
Cultural Biases: Gender, Racial, Sexual, Age, Religious, Social, Linguistic, Geographic, Political Educational, Economic, Technological Statistical Biases: Gathering process, Sampling process, Validity, Completeness, Noise, Spam Cognitive Biases: Self-selection
また正しい指標を設計することも重要です. 例えば推薦したアイテムリストの多様性を重視する場合にはその多様性を定量的に測れる指標を置いておく必要があります. ナイーブにはアイテムの類似度のバラつきを評価することが考えられますが, 類似度といってもサービスの推薦する場所によってユーザの期待する類似性が変わるという話 もあるので, ユーザにとって本当に好ましい/好ましくない多様性というものを考慮した上でそれらを測れるように指標を設計することが, より高度な推薦を行うために必要だと考えます.
3. オフライン評価における課題 ここでは発表の中でオフライン評価の問題提起をしている内容について簡単に紹介します.
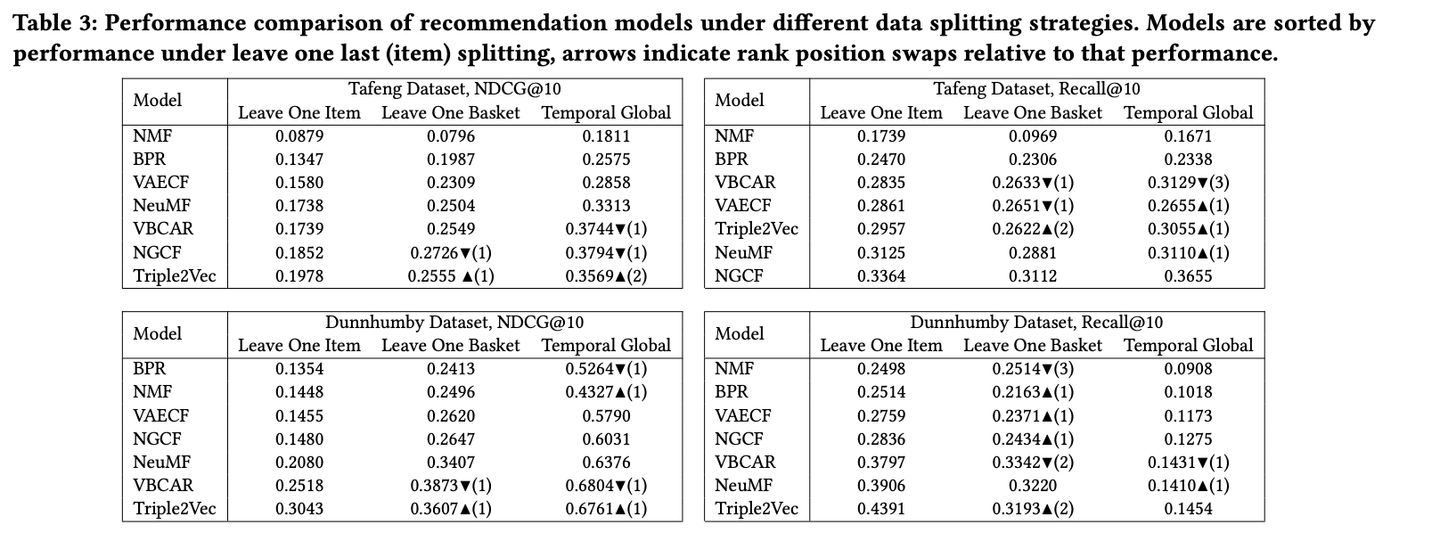
学習データと検証データの分割方法がオフライン評価に強い影響を与えることを調査した論文です. 実験でよく使用されている複数の分割戦略 (Leave One Last, Temporal Split) について7つの代表的な推薦モデルの比較を行った結果, 同じデータセット・メトリックでも分割戦略によって最適なモデルが入れ替わることを実験で示しています.
上記が実験結果となっていて, 行はLeave One Last(item) のスコアでソートされています. 上下の矢印は相対的な順位の入れ替えを示し, 括弧内の数字は移動した順位の数を示しています. どのデータセット・メトリックの組み合わせでも, 分割戦略を変えることで順位に変動が生じていて, 特にRecall@10が顕著になっていることが分かります. データの分割方法は検証項目に依存していると私は考えていて, 検証したいこととズレている設定を取ることで全く違う結果を導いてしまうことが懸念される内容となっています.
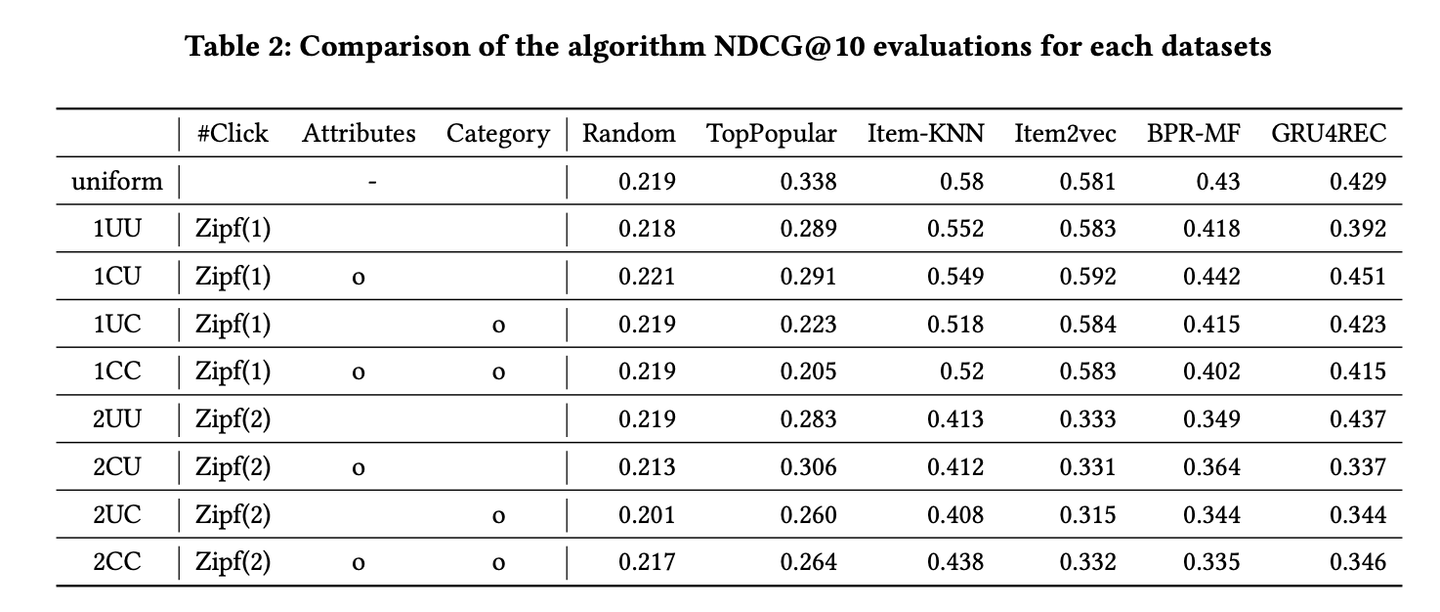
商用サービスの公開用データセットを作成する際の課題を整理し, その課題を解決するための手法を提案した論文です. 公開用データセットを作る上でビジネスメトリクスの隠蔽やfairnessなどのバイアスを考慮できるような手法を提案していて, 検証として異なるサンプリング方法でデータセットを複数生成して複数の推薦モデルでオフラインテストを行なった結果, データセットによってアルゴリズムの性能の優劣が変化していることを明らかにしています.
サンプリング方法が変わることでデータセットの性質が変化しうるため, 検証したい目的に応じてサンプリング方法を選択する必要があり, 様々な設定の公開用データセットを作成することが重要だと著者は主張しています.
オフライン評価と実際期待されるオンライン環境上での成果の乖離を問題視していて, 最適化したい指標の対象が多いことと, 使っている指標ではオンライン環境上における報酬を厳密に拾えないことを課題としています. (具体的には, ユーザがクリックした, もしくは購入したアイテムと全く同じアイテムを予測した場合でしか報酬を与えることができていないが, 実際は識別子の異なる同じようなアイテムが複数個存在しているので, それらを購入した場合も同様の報酬を与えたい)
複数のsession-basedの推薦モデルを複数のデータセット・複数の指標を用いてオフラインで評価したところ全ての評価基準において明確に良いモデルを定めきれなかったため, オフライン評価で良かった上位のモデル群を対象に人間の専門家による評価のフェイズを追加しています. ここでは「主観的に関連している」と「客観的に関連している」, 「関連していない」の3つのラベル付けによる評価を行なっています.
その結果として, 専門家による結果とオフライン評価の結果が異なっていることと, 専門家の評価が特に良かったモデルを採用したA/Bテストでのコンバージョン率の向上を確認しています. A/Bテストではビジネス上の理由から今回のオフライン評価の対象になっていないモデルをベースラインとして採用していて, オフライン評価したモデル同士のA/BテストはFuture Workとなっています.
4. オフライン評価を改善するためのアプローチ 次に, オフライン評価における課題を解決するために提案された手法についていくつか紹介します.
オフライン評価におけるターゲットセットのサンプリング方法の選択によって評価にどのような影響を与えるのかを調査し, unbiasedに近い評価になるようなサンプリング方法を提案しています.
オフライン評価では過去のデータを扱うので, 過去のインタラクションしたユーザとアイテムのペアに対する評価しか行うことができません. そのため, 過去のログにないユーザとアイテムのペアを推論したとして, それに対する評価を厳密に行うことはできず(これを以降unratedと呼びます), その代わりとしてunratedなペアは暗黙的に評価値0として含めるようになっています.
そこで問題となってくるのが, このunratedなペアをどこまで評価に含めるべきかという点です. 極端な設定を2つ考えてみます. まずはunratedなペアを全て含めるケースです. 「following a general principle of using as much information as is available」という話があるのですが, 実際のところは色々と課題が生じてきます. ユーザ数 × アイテム数 分の推論を行わないといけない為に計算コストが非常に高くなってしまいます. また全てのアイテムのうち実際にユーザと関連するアイテムは一握りである為, 山のように存在するアイテム群の中から少数の関連度の高いアイテムをtop-nに配置する必要になり評価が難しくなってしまいます(ほとんどのランキングが評価値0みたいなこともあり得る). 逆にunratedなペアを含めないケースでは, unratedのペアを全て含めるケースでの課題が解消されますが, アルゴリズムごとのランキングのtop-nの中身がほとんど変わらず, アルゴリズムの優劣の差が「順位」であり「選択」ではなくなってしまう懸念が存在します.
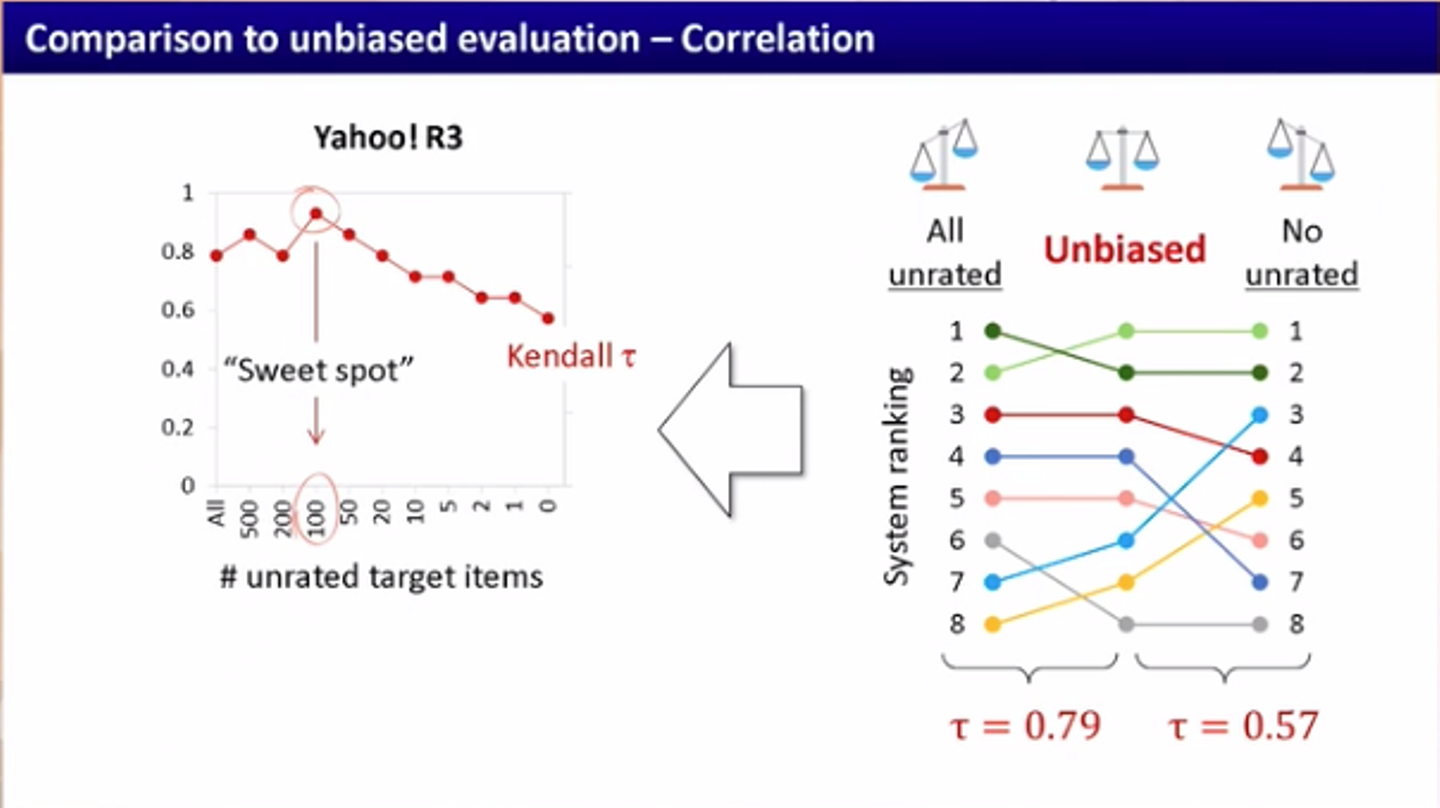
この論文では, 上記のトレードオフを把握した上で, ターゲットセットにunratedなペアをどこまで含めるべきかを実験しています. ユーザの行動ログ特有の観測バイアスの性質を考慮して, unratedのペアがMNARの場合の評価とunratedのペアがMARの場合の評価を比較しています. 後者の方はunbiased evaluationとして, 前者のランキングが後者に近づくほど良いとしています.
unratedのアイテムのサイズを変えて評価してみると, 両端で低くなり, その真ん中あたりで良くなっていることが確認されます. 著者はここが"Sweet spot"であり, このサイズでサンプリングするのがよいだろうと主張しています (ここでは書きませんが, 順位相関係数では厳密な議論ができないので, 統計的検定で最適なsweet spotを見つけるという試みも行なっています).
こちらはSpotifyによる論文です. ユーザにとって「多様な, 驚きのある, 目新しい」コンテンツを推薦することの重要性と, そのような推薦に対する受容性(receptivity) がユーザによって異なるという仮説を持っていて, ユーザの受容性によって推薦内容の出し分けを行いたいというモチベーションの元で, ユーザの受容性推定モデルを作成し評価しています.
diversityやunexpectednessなどのセレンディピティに通じる指標はオンライン評価とオフライン評価の乖離が非常に激しいものです. 「ユーザに対して多様性のある推薦を出すこと」が目的ではなく, 「ユーザに対して多様性のある推薦を出すことでユーザの体験を向上させる(コンバージョンしてもらう)」ことが目的であり, これを実際にオフラインで検証することが難しいからです.
例えば div2vec: Diversity-Emphasized Node Embedding では, DeepWalkやnode2vecのようなランダムウォークベースのグラフの表現学習だと頻度の高いノードに重点を置いてしまうことを問題視して, 出来るだけノードの登場が均等になるようにサンプリングする手法を提案しています. これによって推薦モデルのdiversityの向上が確認され, A/Bテストでは驚異的な成果を出していて見事成功しています. ただこれは実際にはユーザにとっての多様性がユーザ体験を向上させるという仮定を置いているものであって, diversityを許容しないユーザにとっては逆に体験が悪化してしまう可能性があり, オフラインとオンラインのギャップは残っていると考えます.
Spotify は WWW2020 で推薦の多様性について分析した結果を報告しています( Algorithmic Effects on the Diversity of Consumption on Spotify ). 日本語で丁寧にまとめた資料が こちら にあるので詳細はそれを見てもらうとして, Spotifyで消費した曲に関するユーザの多様性は大きく二分されている結果が出ています (同じような曲を聞いているユーザ群と多様な曲を聞いているユーザ群) .
Spotifyのように, プラットフォームにおける多様性をちゃんと調査した上でユーザごとに性質が異なることを確認し, 多様性に対する寛容度を推定して寛容度の高いユーザに対しては多様性のある推薦を行うという, オンラインとオフラインのギャップを埋めようとする取り組みがとても面白かったです.
pointwiseはラベルノイズに強いがclass imbalanceに弱く, 逆にpairwiseは(相対的に)ラベルノイズに弱いがclass imbalanceに強いという特徴があるので, ラベルノイズをうまく緩和する為にランク学習で使われているpointwiseとpairwiseをいい感じに組み合わせることを提案した論文です.
こちらは推薦モデルの精度だけではなく効率性(運用コスト)を踏まえてオフライン評価することを提案しています. 精度に合わせて, CPU時間やメモリフットプリント, disk I/Oなどの指標で評価する枠組みの検討とベンチマーク作成について述べられています.
5. 終わりに RecSysには今回初めて参加しましたが, 実サービスでの応用を意識した発表が多くて非常に刺激的であり, 我々のサービス内の推薦をもっと良くしていこうというモチベーションが更に高まりました. また, 今回は私と松村, 縣で併設のワークショップ RecSys Challenge 2020で発表する機会を得ることができましたが, 来年はぜひ本会議の方でも発表したいという気持ちも高まりました. 実現可能かどうかは全く分からないですが, 今後もサービスの改善と発信の両方を頑張っていきたいと思います!
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)




/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)
