/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

Wantedly, Inc.では一緒に働く仲間を募集しています
こんにちは!
インフラチームの早坂(@takemioIO|@takehaya)です。三週間インターン生として勤務させていただきました。
今回インターンでは Kubernetes クラスタ上でSegmentation Faultなどのメモリ管理とリソース保護の観点でクラッシュしたアプリケーションの検知を行うということを行いました。本記事ではその成果を得られた知見などと共に簡単に報告します。
最終的な成果としてKubernetes クラスタ上で動くContainer仮想化された全てのアプリケーションのSIGNALをキャッチし、それをDatadogにEventとMetricとして送信するリアルタイムに検知を行う監視デーモンを自作しました。
また、その監視デーモン自身のdeploy自体もkubernetesのmanifest を書くことで簡単に利用可能にしました。
またこれらは Signal-Watcherというツールとして公開予定となっております!
モチベーション
Kubernetes はオーケストレーションツールとしてデファクトに近い地位を築いているのではないかと思います。
しかしながらエラー情報のキャッチというのは世の中でディファクトどころか作り込まれておらず、多くの会社が悩んでいるトピックの一つでは無いでしょうか?
Wantedly でも同様で、ほぼ全てのサービスが Kubernetes に管理されており監視やエラーハンドリングは継続して取り組むべき課題と考えています。
我々が特に課題として感じていた例として 「利用していたライブラリが Ruby の実装のバグを踏んでSegmentation Fault が急増してサービスに影響が出ていた」というのがありました。
Wantedly では Rails 上で起きていたエラーを honeybadger という外部サービスにエラーを投げてハンドリングしているのですが Rails より下のレイアーで起きたエラーをキャッチする機構というものがありませんでした。
それによってハンドリングすることができていないということがあり、約一ヶ月ほど気がつくのに時間がかかってしまいました。もちろん現在では対策済みです。
世の中から見た例
実際にすでに行ってるところはあるのでは無いのだろうかと考え、調べてみました。
しかし、私が調べた限り Kubernetes 上にエラーハンドリングをする仕組みを用意しているところは存在しておらず、という感じでした。。。もしご存知の方がいたらぜひ教えてください👀
ですが公開はしていないがそれぽいものを作っているという会社はあるようで、
例えばGithub社がKubeConで発表をしていたエラーを吸い上げて通知をするfailbot
https://kccncna17.sched.com/event/CUFK/keynote-kubernetes-at-github-jesse-newland-principal-site-reliability-engineer-github
などがありました。どのような仕組みで行なっていてどのようなレベルで監視してるのでしょうか・・・気になりますね🤔
さて、無いなら作ってしまえとDIY精神(?)で考えた結果私は例外検知の仕組み作りに取り組みました。
Signal-Watcher
今回自作した Signal-Watcher というツールのフローを説明します。
前提として、1ノード、1Signal-Watcherという形で deploy されていることを前提とします。
大きく分けて4つのフローとなります。
- kube-apiserver から同一 Node の Pod 情報を得る
- 取得した Pod 情報より DockerAPI で PID を得る
- docker 内の任意のプロセスに対して ptrace を Attach する
- SIGNAL or ExitCodeを得たら死んだと見なし Datadog に通知
言葉で言ってもわかんないのでイメージとしては以下のような形です。
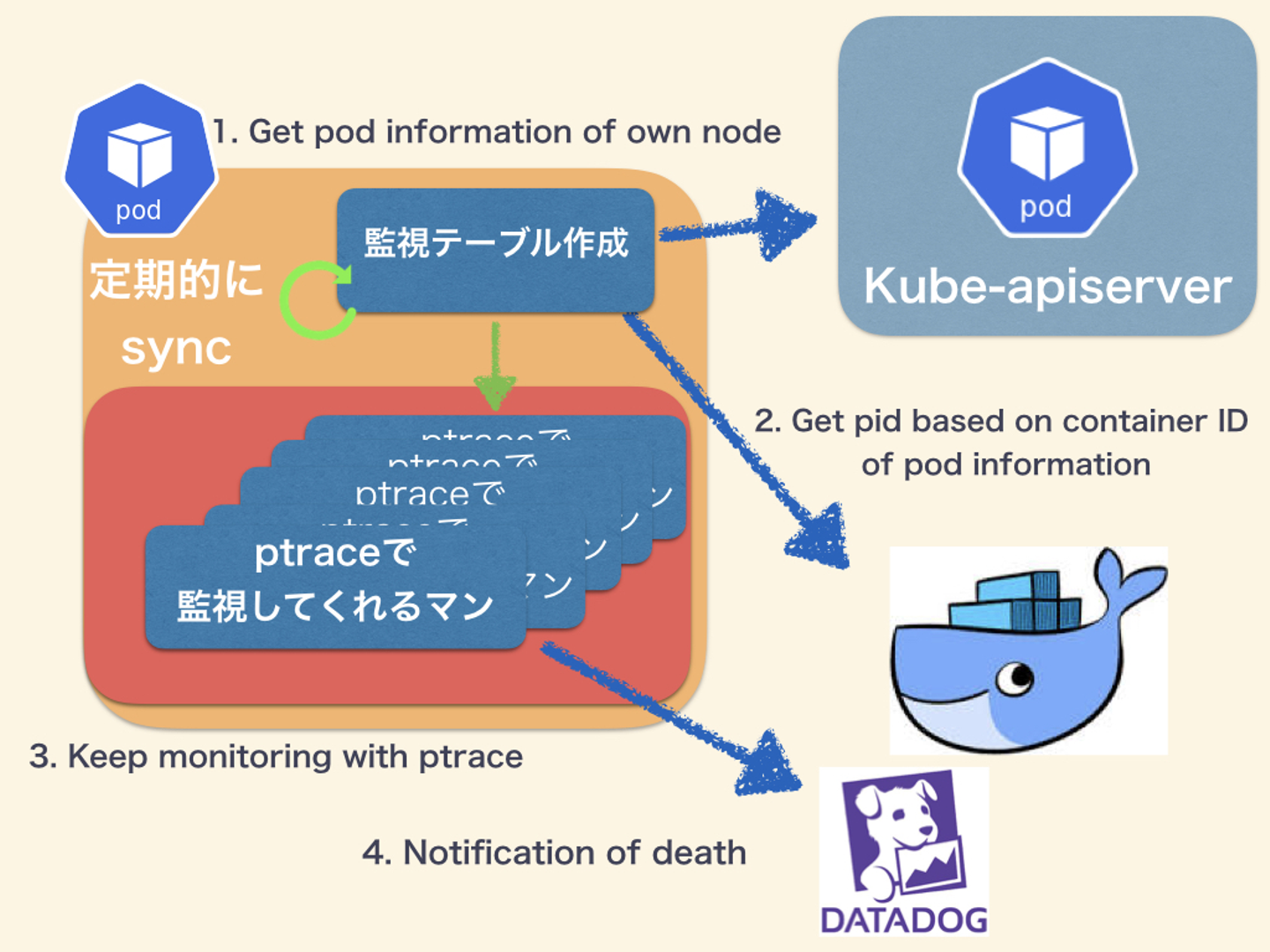
このように非常に仕組みとしてはシンプルな構成になっています。プロセスを監視をしてプロセスが死んだ時に発生するSIGNALとExitCodeと呼ばれる情報を取得して送信します。
しかしこれだけで書かれてもよくわからないと思いますので理解に必要になりそうな説明を簡単に織り交ぜた上で改めてどのような仕組みかを書いていきたいと思います。
kube-apiserver から同一 Node の Pod 情報を得る
ここでは監視対象になる情報を取得しています。
kube-apiserver とは Kubernetes を制御するためのコンポーネントの一つです。kubectlが接続しに行く先というとイメージがしやすいと思います。
今回の実装ではその時に Kubernetes で管理している情報を正として、任意の deltatime で Node 内のPod情報を取得しています。
この時に取得できる情報としては、
- Node名
- Pod名
- Namespace
- Container ID
- Container name
- ExitCode
- ......etc
この辺の情報を取得することが可能です。
実は ExitCode を利用することでSignalを求めることができます。具体的には ExitCode - 128
をすると Signal を取得することができます。しかしながらそれだとワーカープロセスなどにはリーチすることができません。つまり現状だと Container 内の PID: 1 に関する情報までは得ることができました。しかしながら他のプロセス情報をは取ることが出来てないということ示しています。
では Container 内の PID: n の場合に関する情報どのように取るかを見ていきましょう。
取得した Pod 情報より DockerAPI で PID を得る
ここでは DockerAPI を利用して PID を取得します。
これも普段叩いてる docker コマンドが接続しにいく先だと思うと良さそうな気がします。
具体的には Container ID をキーに
docker top コマンドと同一のことを行い、Container 内のPIDを得ることができます。
また、この時叩かれたコマンドも取得することもできたりします。
このように特に難しいことではないですが、強いて挙げるすると、開発中にあった引っかかりポイントが2つ挙げると、
- docker sockをマウントする必要がある
- 実装の際に利用したdockerのライブラリが歴史的経緯でimportが失敗した
ということがありました。
1つ目については
よくよく考えれば自明なのですが、コンテナ内からは DockerAPI にはアクセスすることができません。何故ならば DockerAPI への接続は unix domain socket を通じて行われているのでそこへの接続を持つ必要があります。
具体的には以下のように manifest に書いてあげる必要があります。(もちろんですが DockerAPI の listen をTCPで行ってしまえばこの方法を考えなくても良くなります。)
apiVersion: apps/v1
kind: Deployment
〜〜〜
spec:
〜〜〜
template:
spec:
containers:
- volumeMounts:
- mountPath: /var/run/docker.sock
name: docker-sock-volume
〜〜〜
volumes:
- name: docker-sock-volume
hostPath:
path: /var/run/docker.sock
type: File2つ目については
以下の issue コメントそのままが解法なんですが、
https://github.com/moby/moby/issues/39302#issuecomment-504146736
歴史的経緯でdockerイメージの置いてある場所が変わってしまったというのがあり、その影響を受けてただということがあり、ただ単に
import "github.com/docker/docker/client" をするだけではgolang上でpackageが持ってこれないという話がありました。
解決方法としては go.mod に
replace github.com/docker/docker => github.com/docker/engineを追加することで利用ができるようになります。
さて、以上の方法を経て、監視をするための情報を集めることができました。これらは内部でmapテーブルとして持っており、定期的に、1,2を行ってsyncをしています。
Docker内の任意のプロセスに対してptrace をAttach する
ここからは実際に監視を行います。
具体的な方法は他のプロセスに対して Ptrace と呼ばれる Syscall を利用して、 Attach し、対象のプロセスに対して Wait して続け止まった時に SIGNAL をキャッチします。
kernel内部的な話としては Attach されるプロセスを管理してるtask_struct 構造体の
struct task_struct *parentに対してポインタを入れることで SIGCHILD を受けることができるようになり、Attachできるようになるわけなのですが、今回はユーザーランド側からの制御でそれを対象とする全てのアプリケーションに行います。
説明するのが難しいかと思うので、実際のコードを以下に示します。
// SignalTrace singal catch when process die to error throw
func SignalTrace(pid int) (ResultSignal, error) {
if err := syscall.PtraceAttach(pid); err != nil {
log.Printf("PtraceAttach Retry .... pid: %+v", pid)
return ResultSignal{}, errors.WithStack(err)
}
log.Printf("PtraceAttached pid: %+v", pid)
proc, err := ps.FindProcess(pid)
if err != nil {
return ResultSignal{}, errors.WithStack(err)
}
log.Printf("PtraceAttached ppid: %+v", proc.PPid())
for {
var status syscall.WaitStatus
_, err = syscall.Wait4(pid, &status, 0, nil)
log.Printf("WaitStatus status: %+v", status)
if err != nil {
return ResultSignal{}, errors.WithStack(err)
}
log.Printf("checkerr ok pid: %+v", pid)
if status.Stopped() {
break
}
log.Printf("stop trap pid: %+v", pid)
}
err = syscall.PtraceCont(pid, 0)
if err != nil {
return ResultSignal{}, errors.WithStack(err)
}
for {
var status syscall.WaitStatus
_, err = syscall.Wait4(pid, &status, 0, nil)
log.Printf("wait watch loop: %+v", pid)
switch {
case status.Stopped():
sig := status.StopSignal()
log.Printf("stoped and get sig: %+v", int(sig))
if sig != 19 {
err = syscall.PtraceCont(pid, int(sig))
log.Println("load PtraceCont")
}
if err != nil {
return ResultSignal{}, errors.WithStack(err)
}
continue
case status.Exited():
log.Printf("pid %v exited with code: %+v \n", pid, status.ExitStatus())
exit := strconv.Itoa(status.ExitStatus())
res := ProcInfo{Exitcode: exit}
return ResultSignal{Result: res}, nil
case status.Signaled():
sig := status.Signal()
log.Printf("pid %v was terminated by sig %+v \n", pid, int(sig))
res := ProcInfo{Signal: sig}
return ResultSignal{Result: res, IsSignal: true}, nil
default:
log.Printf("pid %v did something weird \n", pid)
return ResultSignal{}, fmt.Errorf("pid %v did something weird", pid)
}
}
}
このように先ほどの説明通りシンプルな仕組みなのですが...注意する点としては、まずptrace Attach をすると子プロセスが一度停止します。その時をキャッチして
syscall.PtraceCont(pid, int(sig))
で子プロセスをContuineをしてあげる必要があります。そしてこの後に実際の監視のためWaitするループに入ります。この部分が初めに理解することが出来なくて苦労しました....😭
ちなみですが、 PTRACE_SEIZE を利用すると初めの子プロセスが停止しないバージョンの ptrace Attach が使えるそうです。今回は今後何かしらのパラメータを渡す可能性を考慮した結果この方法で実装しませんでした。
さて、このようにしてプロセスをキャッチする仕組みが完成しました。
しかしながら、この仕組みは通常の方法では仮想化されている故にまだ使うことが出来ません。
具体的には他のPIDにアクセスすることが出来ないということがあり、なおかつptraceを有効にすることが出来ません。
なので今から挙げる2点に注意することをしなくてはいけません。
まずは、階層的仮想化のうち PID に対する仮装化が行われています。よって SignalWatcher の PID名前空間 を host 側に寄せる必要があります。
これはどういうことかというと一般的に PID名前空間 というモノがあり、そこの中で俗にいう Namespace を切ると呼ばれることをしてコンテナから他のコンテナやホストのプロセスを見ることが出来なくしています。
なので今回は以下の画像のようにPID名前空間をhost側と同じにすることで解決させます。
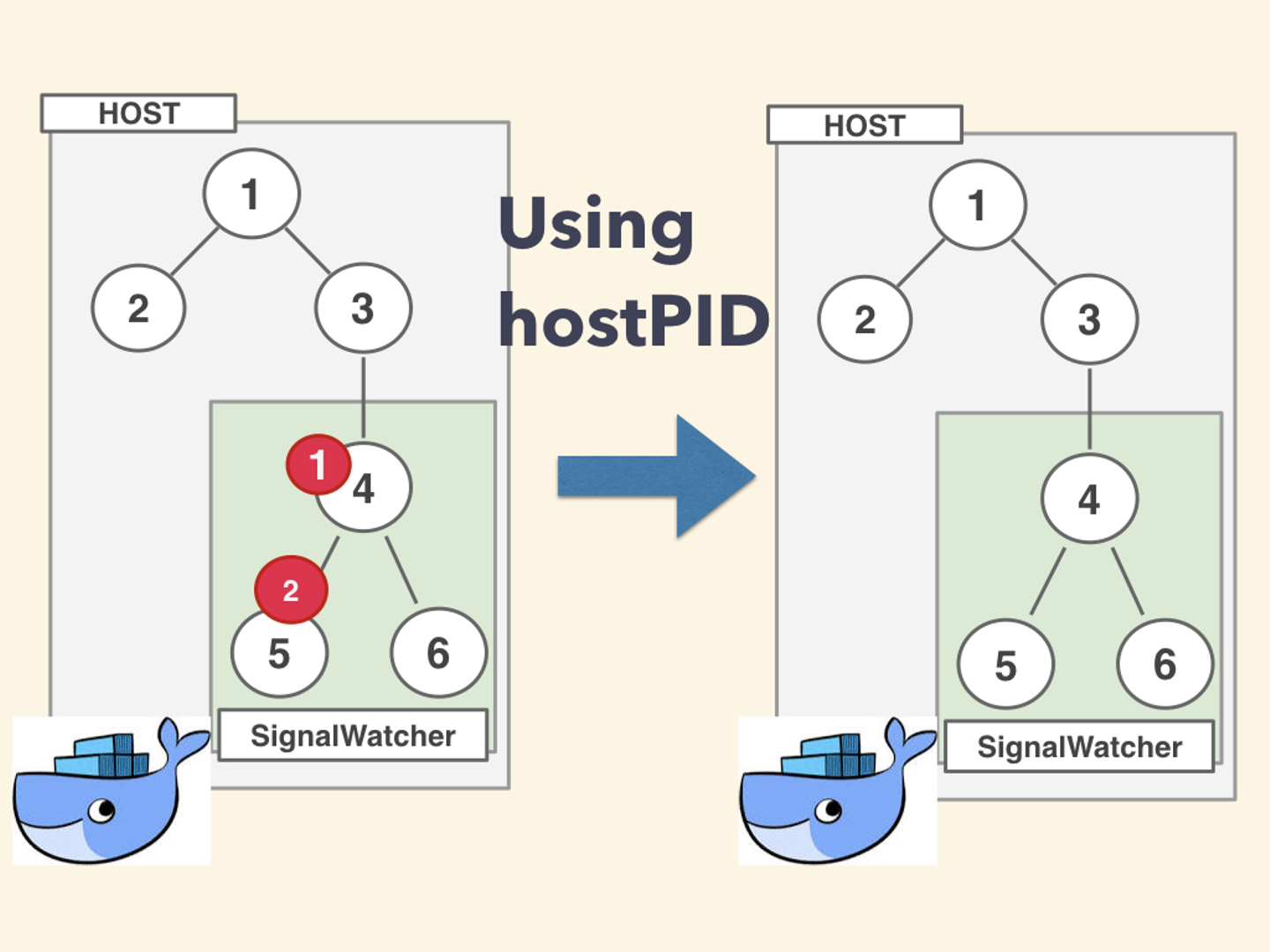
具体的には以下のように
hostPID: trueというパラメータを有効にします。これを利用することで host(Node内) と同一の PID名前空間 に入れることが出来ます。
apiVersion: apps/v1
kind: Deployment
〜〜〜
spec:
〜〜〜
spec:
hostPID: true
〜〜〜これを行った時のアクセスレベルとしては以下の画像のようなイメージになります。 SignalWatcher 側からアクセスできますが、他の Container内プロセス からアクセスができません。
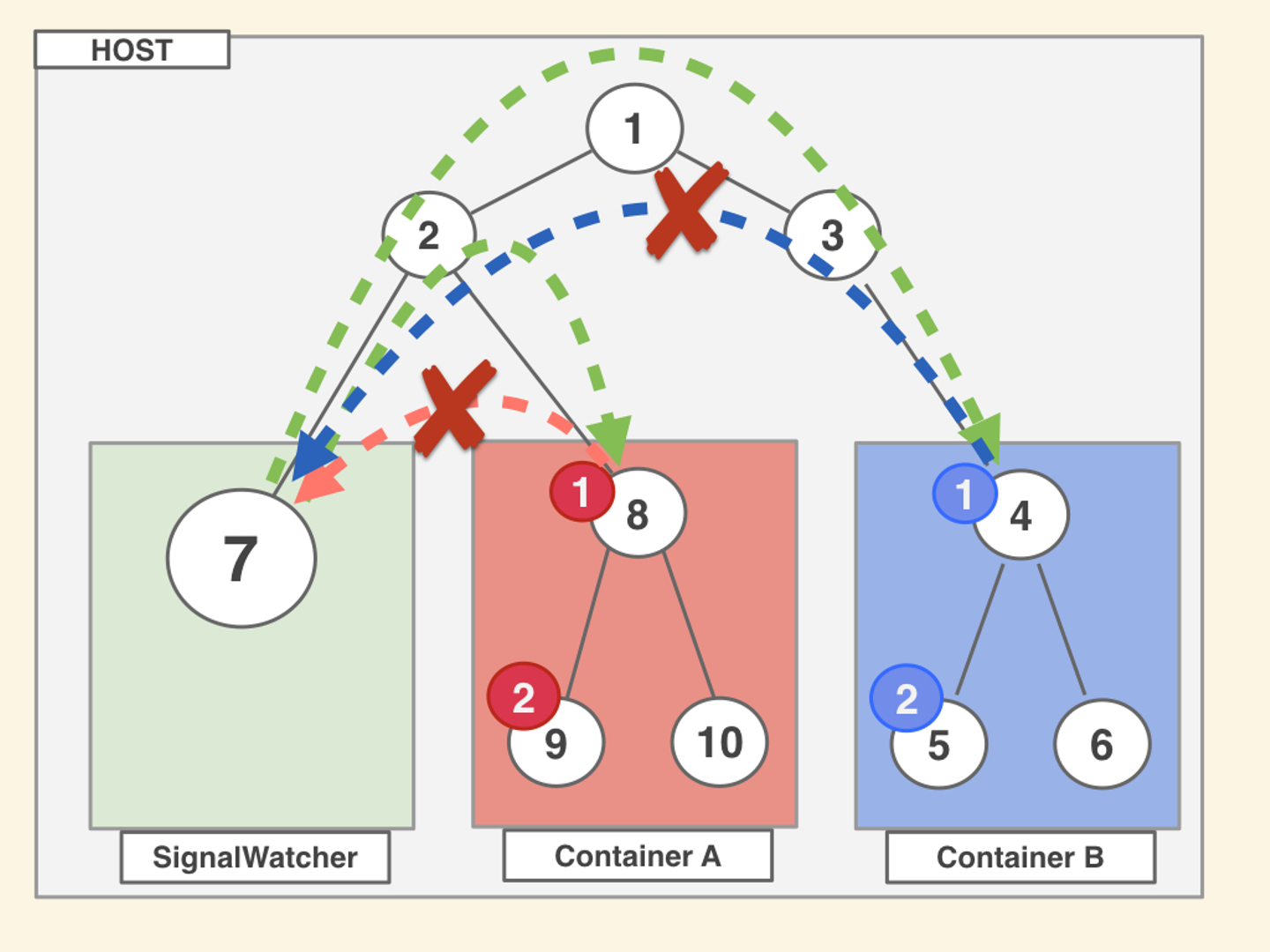
また、ptrace の実行を許可することをしなくてはいけなく、今回は雑に以下のような設定を入れています。
apiVersion: apps/v1
kind: Deployment
〜〜〜
spec:
〜〜〜
spec:
containers:
〜〜〜〜
securityContext:
capabilities:
add:
- SYS_PTRACE
- SYS_ADMIN
privileged: trueさて、ここまでで名実ともに ptrace で SIGNAL を取得をすることが出来ました!
SIGNAL or ExitCodeを得たら死んだと見なし Datadog に通知
Wantedly では Datadog を使って監視をしているのですが、今回はそこにおんぶに抱っこをしようと思います。これを利用することでよしなな通知やアラート、メトリックを見るボードなどが自作せずに済みます。
今回は直接 DatadogAPI を使って情報を送ることにしました。具体的には SIGNAL と ExitCode を Event と Metric として送ることをしました。
結果としては以下のように情報を取得することが出来ました。
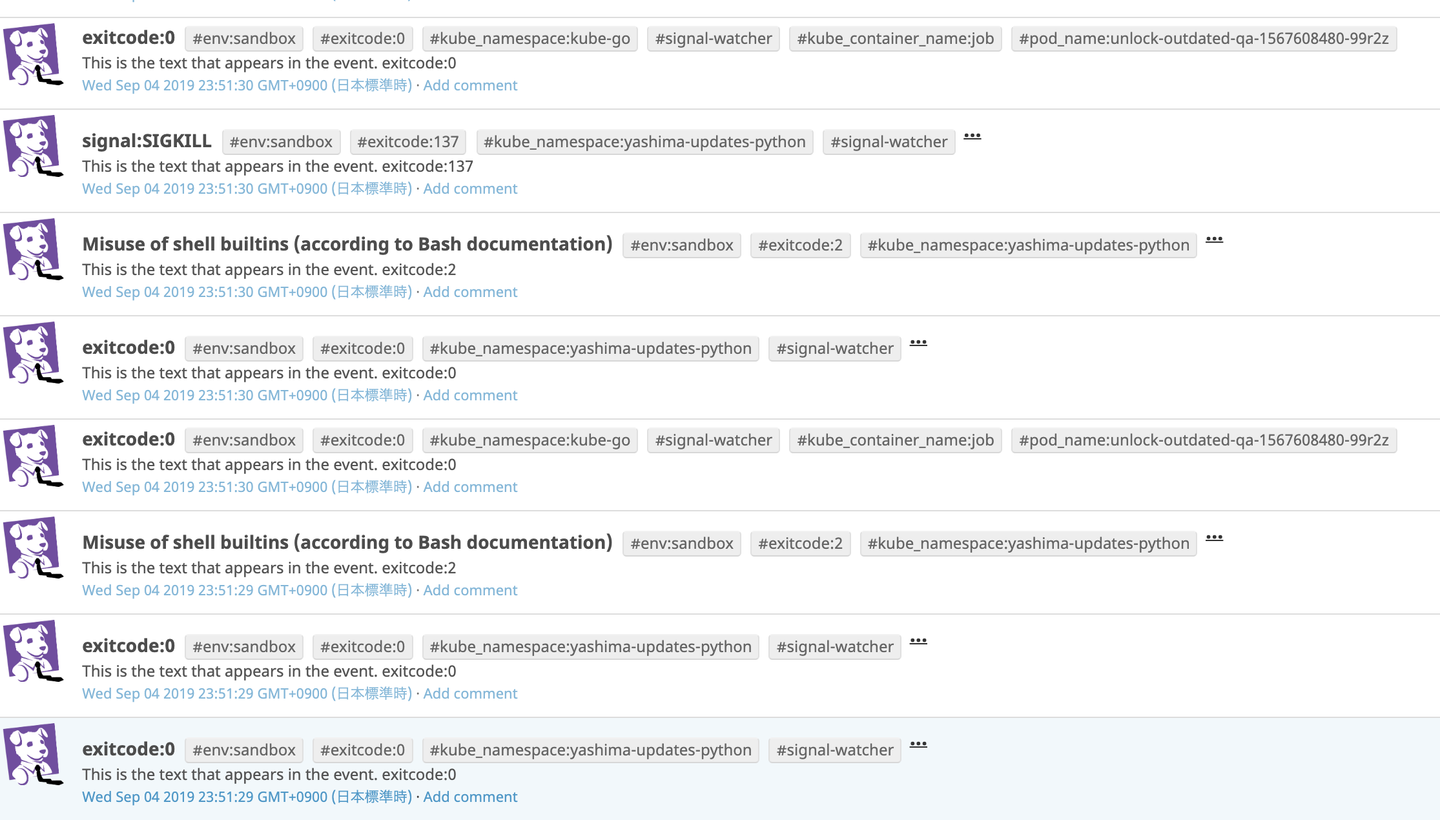
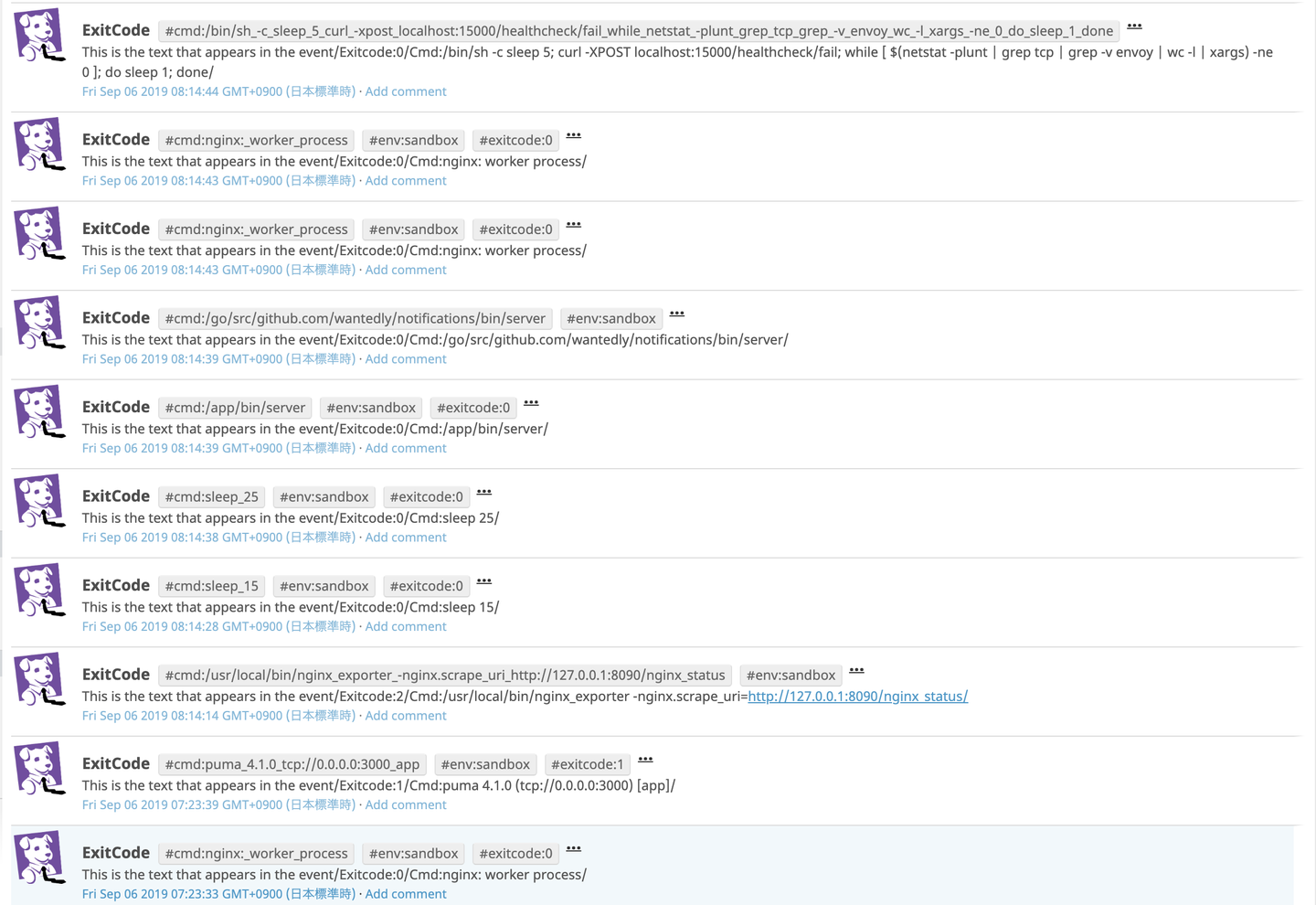
いい感じに取れてそうですね!!
まとめ
改めてまとめると、 「Kubernetes 上にdeployされたアプリケーションが死亡した時をハンドルしてエラーを通知するデーモン」を自作しました。
これが三週間の成果です! もちろんまだまだ機能として足りないところや検証したいことはあります。例えばDatadog以外への監視基盤対応や実際に動かしてみてのデバッグなど・・・
しかし、これによって解決されるインパクトはかなり大きいものなのではないかと自負しております。
短い期間でしたが、エンジニアとして集中して一つのタスクに取り組むことは大変でもありましたが、しかし、一から考えて実行していくのはSREらしい業務で非常にワクワクする良い体験となりました。
まだまだ運用面などでは検証することがあり今回実装出来たモノはPOCの域は出ず課題は多いですが、より「シゴトでココロオドル」を最短距離で届けていくためにエンジニアリングで引きづつき問題を解決していきます。
最後にですが、時に厳しく時に優しく指導してくださったメンターの田中さんをはじめ、受け入れてくださったinfra squadのみなさんに感謝します。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

Wantedly, Inc.からお誘い
この話題に共感したら、メンバーと話してみませんか?
Kubernetesクラスタ上のエラー検知

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)
