Wantedly, Inc.では一緒に働く仲間を募集しています
Under the Hood of Wantedly’s Recommender System - 推薦システムの評価の裏側

on 2019/02/15
こんにちは!
Wantedly Visitで開発チームのリーダをしている久保長です。
去年の4月からRecommendationチームを発足し、推薦や検索の改善を行なってきました。その中で、推薦システムの評価を整備してきたので、そのお話をします。
現在、Wantedlyでは機械学習を使った推薦を色々な場面で利用していますが、評価を整備したことで、性能は大きく改善し、開発スピードも向上させることができました。
推薦システムの評価は、オフラインのテストとオンラインのテストがあります。また、オフラインのテストでは定量的な評価と定性的な評価があります。
これらを組み合わせることで、オンラインで使うアルゴリズムや特徴量の選択の質が上がり、効果的なアルゴリズムをオンラインでテストすることができます。
特にオフラインのテストは、新しいアルゴリズムで表示するアイテムは過去は表示していないことへの懸念や、データの整備が進んでおらず過去の表示した順番が分からないという問題からなかなか進んでいませんでした。整備することで、アルゴリズム自体の性能改善が進み、去年はオンラインテストとしてリリースした推薦6個全てが以前のアルゴリズムと比較して良い結果になりました。
オフラインテスト
オフラインテストとは、実際に推薦を適用する前に、過去のデータを用いてテストを行なったり、推薦した結果に対してInterviewやSurveyを実施して、リリースする前に問題を把握することです。
定量評価について
定量評価は、過去のデータに用いて、MRR/AUC/Precisionなどの指標で評価を行うことです。定量評価を行う際には、目的の定義、評価指標の選定、評価するデータの期間を決める必要があります。
目的の定義とは、評価する上での正解の定義です。例えば、ウォンテッドリーの募集推薦の評価をする際には、募集のクリックとするか、募集を長く見るか、募集への応募をするか、企業からの返信があるか、採用されるか、採用された上で活躍するか、応募が少ない企業に応募をしてもらうか、広告商品を購入している企業に応募をしてもらうかなど、複数あります。ユーザと企業双方の満足度を最大化させるための定義を決める必要があります。
評価指標の選定でもたくさんの種類があります。下の図は RecSys 2017 Conferenceでの各企業が使っている評価指標ですが、使う指標は様々です。ウォンテッドリーでは、AUC,Precision,Recall,F1-score,Efficient Catalog Sizeを確認しています。具体的には、実際に表示した順番を新しいアルゴリズムで並び替えてAUCのスコアで評価することや、推薦で表示した上位20件のうち実際に目的を果たしたもの(Precision)、目的を果たしたもののうち推薦で表示した上位20件に含まれてる割合(Recall)を行なっています。
例えば、3年前のkaggleのexpediaのホテルの推薦では、推薦した上位5件に対してのPrecisionが使われ、去年のSpotifyのデータを使ったRecSys Challengeでは、PrecisionとNDCGなどを使い目的もclickと指標を組み合わせた複数の指標を使ったもので行われていました。
各指標に関しての説明は、「レコメンドつれづれ ~第3回 レコメンド精度の評価方法を学ぶ~」こちらのブログが参考になります。
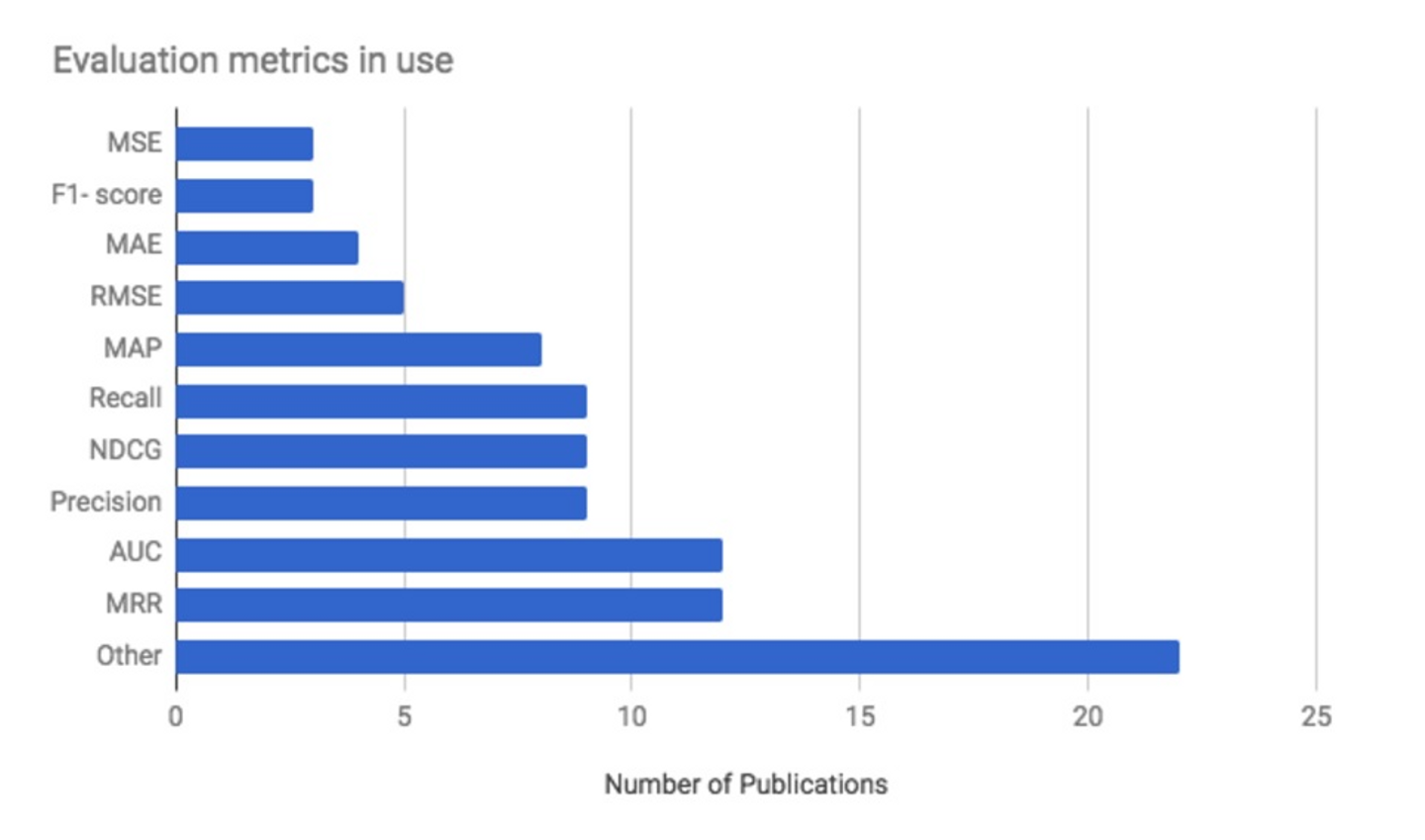
評価するデータの期間に関しては、ウォンテッドリーの場合トレンド性が強いため、時間を区切ってtrain期間とtest期間を設定しています。test期間は、ユーザが毎日利用するサービスではないので、2週間から1ヶ月のデータで行なっています。また、test期間は複数選択することで、トレンドごとの性能の違いを吸収できるように進めています。
ユーザ単位で分割して学習する場合、将来応募されるトレンドのものを過去のユーザのデータで学習することになります。ウォンテッドリーの推薦では、ランキング自体にトレンドがあるため、時間を区切って評価を行うことが重要でした。
定性評価について
定性評価とは、Interviewによって利用しているユーザに質問し理解を深めたり、Surveyによって利用しているユーザの気持ちの定量的なデータを集めることです。
定性評価も定量評価と同じように重要で、それぞれの得意なこと苦手なことを理解し、使い分けることが大切です。定性評価では、特にInterviewではサンプルサイズが限られるため参加してくれた人の声が強調されすぎます。また、意見に対しての解釈や質問の方法によっても結果が変わります。定量評価では行動以外のユーザの気持ちが分からず、例えば同じ募集を見るという行動を3回行なったユーザであっても印象は異なるかもしれないです。また、大多数のユーザに最適化されるので、少数の人の行動は見えなくなります。

定性評価と定量評価は合わせて分析を行うことが大切です。定性評価で得られた知見を定量的に確かめることや、定量評価で得られた結果の説明を定性評価によって得ます。またInterviewによって得られた仮説をSurveyによって定量的に確かめることも効果的です。
Spotifyでは、User Perception of Differences in Recommender Algorithms(2014)の資料によると、複数のアルゴリズムを以下のようなSuveryをとった上で比較していました。
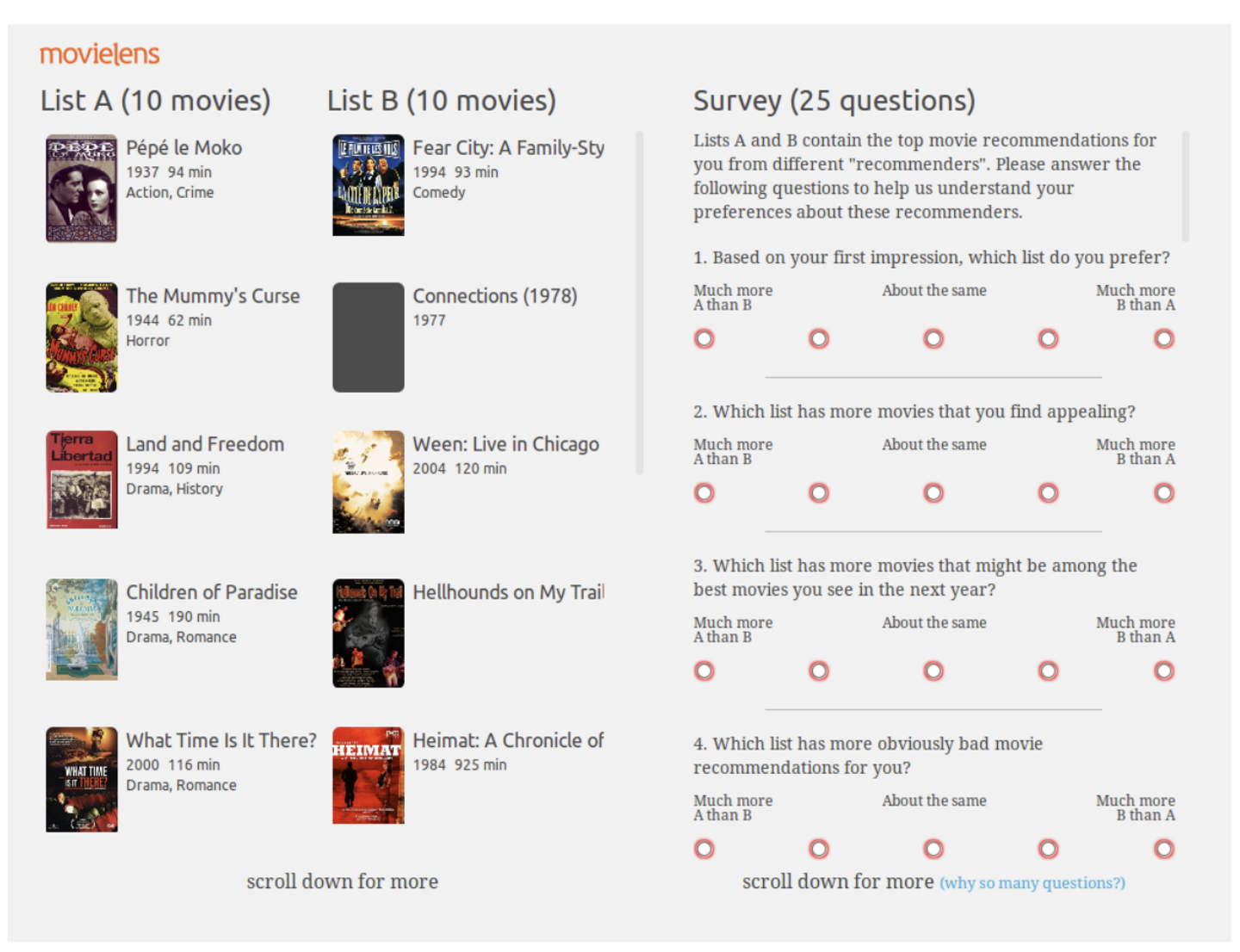
アルゴリズムごとにユーザが与える印象がどのように異なるかが、アルゴリズムごとに差が出ていることが分かります。

2018年のrecsys2018では、SpotifyがEvaluationについてのtutorialを公開しており、非常に勉強になります。
オンラインテスト
オンラインテストとは、実際にユーザに推薦内容を表示させて、ユーザの行動を確認することです。
interleavingについて
interleavingとは、新しいアルゴリズムと古いアルゴリズムを同時に交互に出し、どちらが良い反応するかを評価することです。
推薦システムを評価する上で、interleavingは非常に有効な手法になります。
私は、Netflixのブログで手法を知り、ウォンテッドリーに導入したところ、非常に効果があり、現在は全ての推薦の一次評価で利用するようになっています。導入したアルゴリズムは、Team draft interleavingです。およそA/Bテストよりも10倍早く評価することができます。
実際に以下の図は、Wantedly Visitの中でInterleavingでリリースした時と、A/Bテストでリリースした時を比較したものです。アルゴリズムの差があると判断できるまでの時間が10倍以上違うことが分かりました。
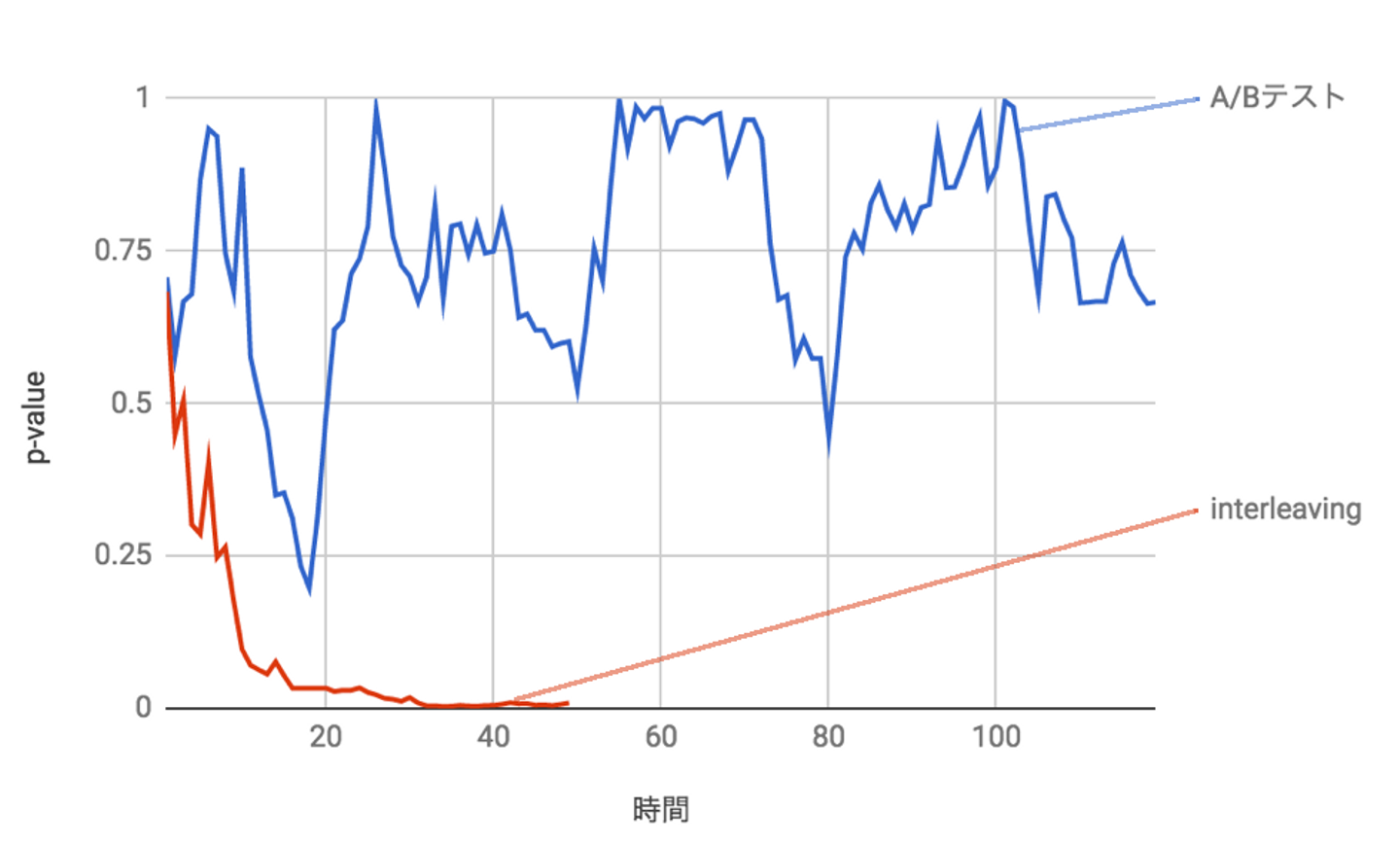
詳しい説明はWantedlyのtechbook 4でも書いています。またこちらのqiitaの記事は日本語でまとまっており、参考になります。
A/B testingについて
interleavingでは、ユーザはどちらの推薦に対してより多くの反応をしたかは分かりますが、変更によって他の機能にどのような影響があるか、ユーザのリテンションなどの遅行指数に影響があるかは正確には分かりません。影響が大きいために丁寧に進めたい機能の場合はA/B testingを行い評価するようにしています。
最後に
Wantedlyでは、オフラインとオンラインの評価を整備することで推薦システムの改善が進みました。それぞれの評価の特徴を知り、導入することは効果的です!!
Wantedlyの推薦の仕組みについてもっと知りたい、知見を交換したいという人がいましたら、こちらから気軽に話を聞きに来てください!


Wantedly, Inc.からお誘い
この話題に共感したら、メンバーと話してみませんか?
Under the Hood of Wantedly’s Recommender System - 推薦システムの評価の裏側









