
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)

/assets/images/5673658/original/767e046d-422d-44e3-ac17-74af4a96146e?1709547072)
Wantedly, Inc.では一緒に働く仲間を募集しています
- バックエンド
- PdM
- フロントエンドエンジニア
- 他23件の職種
- 開発
- ビジネス
こんにちは。エンジニアの 白鳥 (@irotoris) です。 普段はインフラチーム(Infrastructure Squad)で、Wantedly の全サービスが稼働する AWS / Kubernetes をベースとしたインフラの開発運用やSREをやっています。
Wantedly Visit を始めとする Wantedly のサービスにおいて、ほぼすべてのバックエンドシステムは Kubernetes クラスタの上で動いています。 この基盤は本番サービスが稼働するシステム基盤でありつつ、Wantedly のすべての開発者がアプリケーションの開発運用で使うことになる開発者のためのプラットフォームでもあります。
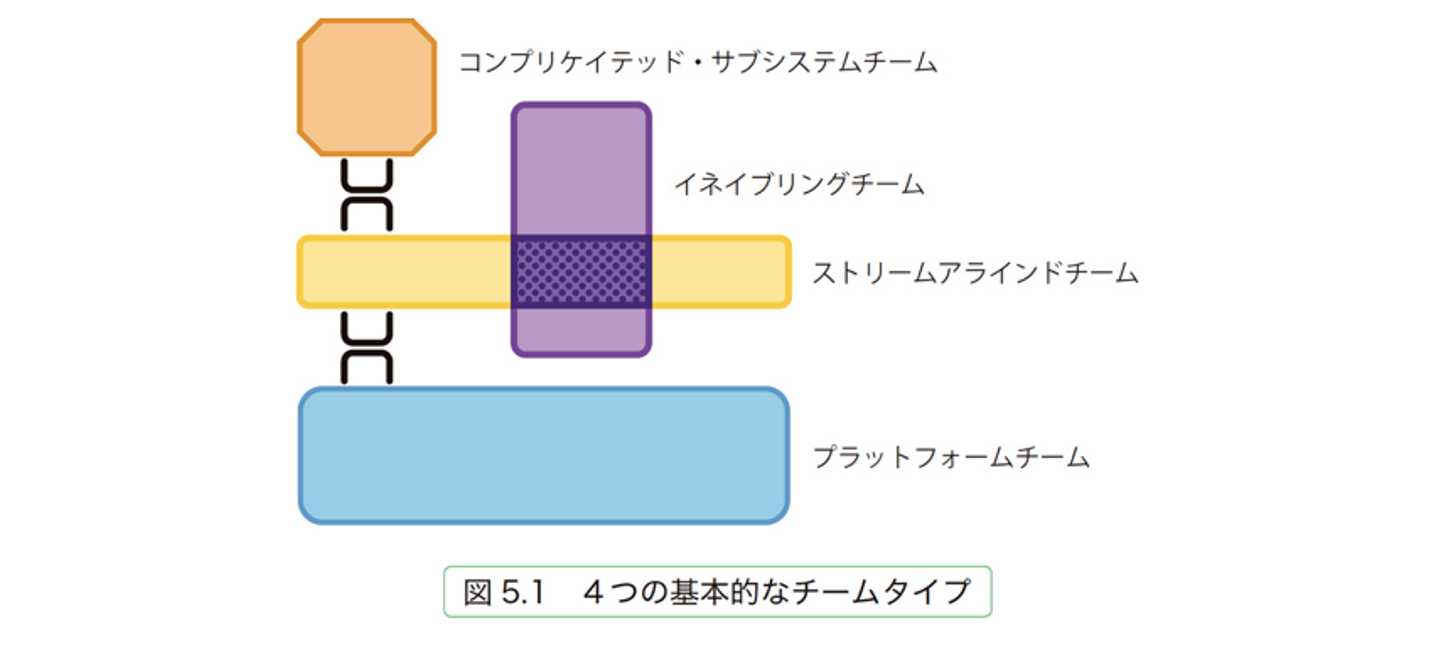
Wantedly のインフラチームは Team Topology でいう「4つの基本的なチームタイプ」のうちプラットフォームチーム (※1) としての動き方に近いのですが、本章では Wantedly のインフラチーム、システム基盤/プラットフォームの歴史を振り返るとともに、 この基盤のマネジメントをやろうと思ったきっかけとどうやったかについて記したいと思います。
チームトポロジー(※1)から引用
Wantedly のインフラは Platform as a Service(PaaS) である Heroku から始まりました。 Heroku 時代はインフラチームなんてものはなく、アプリケーションエンジニアがコマンド一発でデプロイしていました。
その後、サービス規模の拡大により AWS への移行が行われました。そのときに AWS インフラを管理するチームであるインフラチームが誕生しました。 サービスはこの後も拡大し、開発は加速度的に増していきます。2014-2015年頃の話です。
AWS 利用初期では、EC2 インスタンスや Docker on EC2 の構成でアプリケーションを動かしていました。 そうなってくると、Heroku にあったようなコマンド一発でアプリケーションをデプロイする体験は自分たちで作る必要があります。 Heroku でてきていた開発速度を落とさない、またはさらに加速させていくための取り組みが始まります。
このときインフラチームが目指した姿は以下のようなものです。
何を実現するか
Code wins Arguments を可能にするインフラ
既存のアプリでも新規アプリでもどんどんデプロイできる変化に強いインフラ
変化を避けるインフラではなく、むしろ変更を前提としたインフラ
議論や権力ではなく、まず出してみて結果を見る文化を可能にする
どう実現するのか
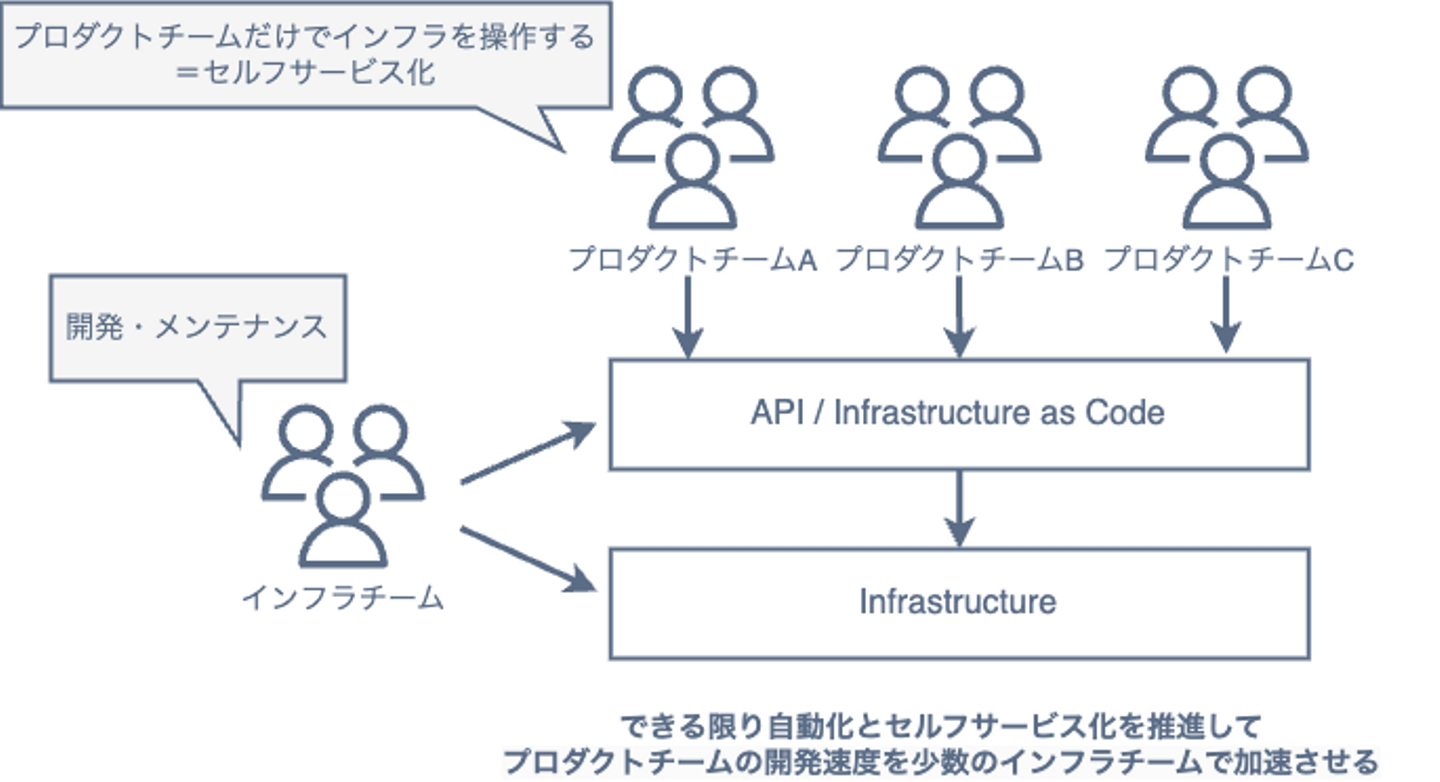
インフラチームが目指していること = 自動化 / セルフサービス化
大前提としてサイトの信頼性を維持・向上していくという話はありつつも、この運用の自動化/セルフサービス化を積極的に進めてきました。 その具体は Infrastructure as Code やデプロイ作業の抽象化、自動化でした。
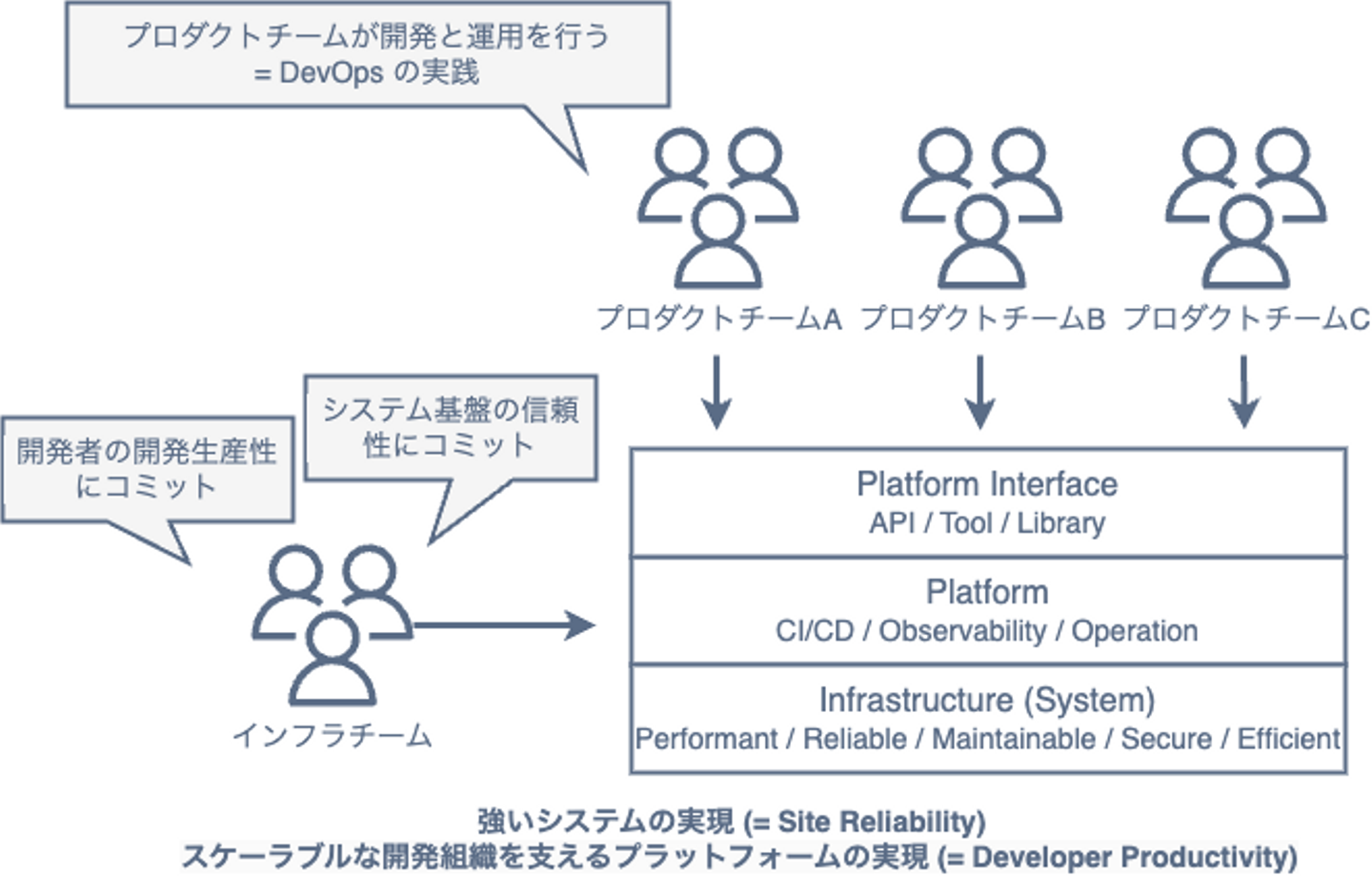
運用の自動化/セルフサービス化といった活動を続けてきた結果、「サービスが稼働するシステム基盤であり開発者向けのプラットフォーム」という基盤がなんとなく形成されました。 実態としては AWS や Kubernetes などクラウドネイティブの技術要素で構成されたインフラです。その上で DevOps や SRE のプラクティスを行えるようになりました。 そしてインフラチームの方向性は以下のように更新されました。2020年ごろの話です。
何を実現するか
強いシステムの実現(= Site Reliability)
- Performant / Reliable / Maintainable / Secure / Efficient"
スケーラブルな開発組織を支える Platform の実現(= Developer Productivity)
- Tool / Library / System / CI/CD / Observability / Operation
どう実現するのか
「プラットフォーム化」というアプローチを取る。プロダクトチームがオーナーシップを持って開発と運用を行い、我々はそのための Tool/Library/System/Infra を用意する。また考え方やベストプラクティスの啓蒙、組織構造の改善など、開発組織の文化・組織的な改善の取り組みも行う。
これまでに実践してきたものには以下のようなものがあります。
このようにプラットフォームに対して機能追加をして開発者ができることを増やし、ソフトウェアデリバリーとサービスの信頼性を向上させる営みを続けてきました。 しかしプラットフォーム開発を続けてきたことでその機能や基盤も大きくなった結果、プラットフォームの全体像が見えにくくなってきました。 また、プラットフォーム開発をして価値を増やすということは、その分だけ運用も増えることになります。 その結果プラットフォームの開発と運用において「なんかやることが多くて大変…」「いまプラットフォームはなんの価値を提供できているんだっけ」と感じることが多くなりました。
そこでまず「我々インフラチームはプラットフォームとしてどんな機能を提供していて、その機能が解決している課題領域はなんだっけ?」という問いに答えられるようにすることにしました。 この課題領域の整理の目的は、プラットフォームが解決する課題領域の特定と共通認識の醸成です。そしてその共通認識と現実現場で困っている具体的な課題を突き合わせると、計測すべき価値の姿や次に集中するべきことが見えてくるのではないかという仮説がありました。 この営みを社内では「プラットフォームマネジメント」と呼称して進めていきました。2022年頃の話です。
まずチームが持っている動いている持ち物(コンポーネントやプロセス)の整理からはじめました。 Kubernetes をベースとした基盤といっても、その上で動いているものが解決する課題は様々です。 粒度はバラバラですが、チームとして「これは我々が提供・メンテナンスしている」と認識しているものを洗い出してみました。
上記は一例ですが、大小合わせて100個程度のコンポーネントやプロセスがありました。 これらをラベリングしていくと、チームで特に対面している課題領域の枠組みが見えてきました。 また、過去は有用だったけど現在は別の方法に取って代わった、価値が低くなったコンポーネントも発見できました。
整理した持ち物をベースに、それらが解決している課題領域を分類すると以下のようなものがでてきました。
これらは世の中一般的な技術領域ではありますが、Wantedly のインフラチームが特に対面しているものなので、網羅されているわけではありません。 おそらく事業や組織規模によって異なるでしょう。 Wantedly の事業や組織が変化していくにつれ、この領域のどこにも当てはまらない新しい課題が出現することもあります。 それはチームに求められるケイパビリティが変化した証であり、これを常に考えることでその変化の起点を捉えられるのではないかと考えています。
そしてプロダクトチームがオーナーシップを持って開発と運用 (=DevOps) を行うためには、プロダクトチームが課題領域に応じてそのインフラストラクチャやツールを適切に選択・組み合わせて上手く扱う必要があります。 しかし DevOps を実現するためのツールやプロセスは数多くあり、そもそも適切な選択ができない、扱うための認知負荷が非常に高いというのが現状です。 そこでプラットフォームとして機能を抽象化し、プロダクトチームにとって扱いやすいインターフェースを提供することはとても重要です。
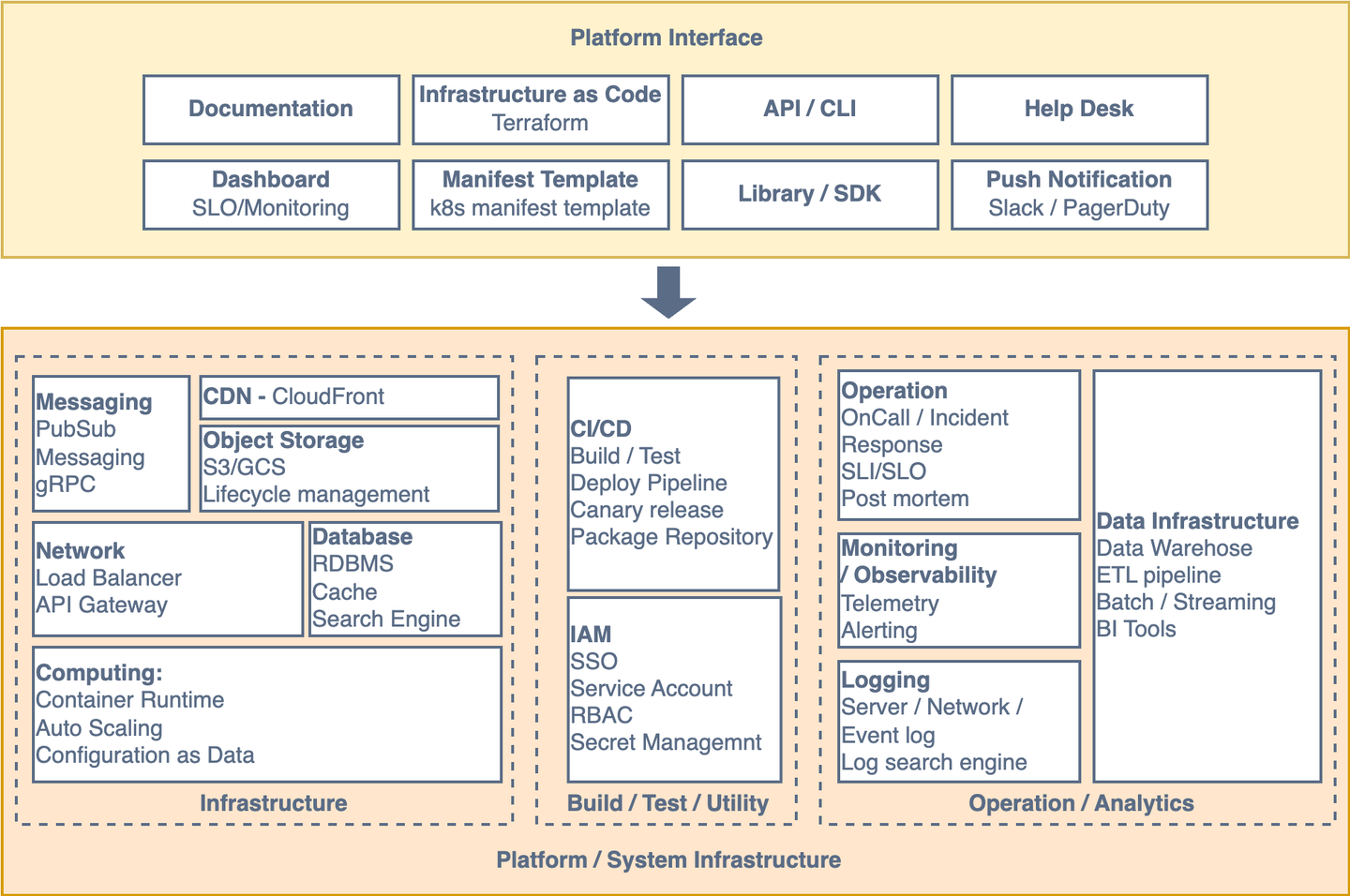
全体としてそれぞれの責務と実装、インターフェース整理すると以下のような図になりました。
この課題領域はあくまで「領域」であり、開発現場で解決したい具体的な課題とは異なります。開発現場の課題は、この課題領域のいくつかで構成されています。 たとえば「障害対応におけるロールバックを5分以内に完了させたい」という課題を解決したいとしましょう。 そうするとこれに対応する課題領域は CI/CD ですが、それを可能にするには CDN の invalidate 操作だったり、ロールバックイメージを高速に展開するためにコンピューティングにおけるスケーリング速度が必要になってくることが考えられます。
そしてこれらを抽象化してチームで認識できるように、課題領域について以下のようなフォーマットでその具体を定義していきます。
本質的な課題
その必要性を一言で
責務
インフラ/プラットフォームとして担っている責務
提供機能
インフラ/プラットフォームとして提供している機能
提供インターフェース
インフラ/プラットフォームとして提供しているインターフェース
いくつか例を見てみましょう。まずはプラットフォームの中でも一番基本となるコンピューティングについてです。
コンピューティング
本質的な課題
システムの中核的な動作は計算によって駆動されている。その計算資源の効率的な確保と柔軟な利用を実現する。
責務
可用性、拡張性、弾力性を兼ね備えたマイクロサービスを実行する基盤
マイクロサービスのランタイム技術に依存しない、抽象化された実行基盤
インフラレイヤ(可用性、拡張性、弾力性)を抽象化してリソース設定をサービス開発者でもできるようにインターフェースを提供する
デプロイの一連の流れを抽象化してサービス開発者でもデプロイできるインターフェースを提供する
提供機能
コンテナランタイム
ポータビリティ
オーケストレーション
オートスケーリング
スケジューリング
リソースの宣言的管理
上記機能を実現する Kubernetes クラスタの運用
提供インターフェース
kube (内製 CLI ツール)
Kubernetes manifest template / generator
new-app/getting-started (ドキュメント)
実態としては Kubernetes (とそれを取り巻くエコシステム) なのですが、このように一般的な課題領域として言語化・意識することで、インフラが提供している(普段動いていることが当たり前で見えにくい)価値を認識することができます。 また責務と具体的な機能、提供インターフェースを書き出すことで、今実現していること・まだできていないこと(これからやりたいこと)が可視化されます。
次にデータベースの課題領域を見てみましょう。
データベース
本質的な課題
価値の増え続けるサービスを提供するためにはデータの永続化とトランザクション管理が必要になる。
責務
RDBMS / KVS / 検索エンジンのデータストアサービスおよび設定プラクティスの提供
RDBMS / KVS / 検索エンジンの統合的なモニタリング設定の提供
提供機能
RDS / Aurora PostgreSQL とデフォルト設定の提供
ElastiCache for Redis とデフォルト設定の提供
Redis Pod k8s manifest の提供
DynamoDB / Cloud Datastore とデフォルト設定の提供
Elasticsearch on k8s のデフォルト設定の提供
各種モニタリングアラート設定の提供
バックアップ / リストア機能の抽象化、提供
開発環境向けデータベースの提供(本番DBとの同期、データマスキング)
キャパシティプランニング コスト最適化 (RI, OnDemand Capacity, etc.)
(社内では「データベース」と定義しましたが、「データ永続化」の方が正しい気がしてきました。)
Wantedly ではインフラチームがデータベース関連の管理機能を抽象化して提供していますが、 セルフサービス化の方針的には実際に使うのはプロダクトチームのエンジニアであることが望ましいです。 しかし現在、データベース管理をすべてをプロダクトチームが行っているわけではありません。開発組織規模や全体最適を考えると、 キャパシティプランニングやパッチ適用など、いくつかはインフラチームが横断的に(または協働的に)役割を持ったほうが良い場合もあります。 プラットフォームとしては各プロダクトチームに任せるほうが正しいように思いますが、事業や組織の状況からそうしないと選択することもあります。 このように課題領域に対してプラットフォームとして今現在どういう選択をしているかと認識することは、今後の変化に対応するために必要な判断材料になります。
ネットワークはどうでしょうか?
ネットワーク
本質的な課題
ユーザーの要求にシステムが応えたり、システム内部で協調動作をするためには通信ができる必要がある。
責務
アプリとシステム、システム間の通信を実現、担保する設計とプロトコルの提供
- 担保するべきもの:レイテンシの基礎数値、エラーレート
開発や基盤メンテナンスのためのネットワークレイヤの抽象化レイヤの提供
- コンピューティング (Kubernetes) やモニタリングと統合されているものも多い
提供機能
インターネットアクセス
マイクロサービス間通信
マイクロサービス-クラウドサービス間通信
HTTP/S
名前解決(Public/Private)
Load Balancer
API Gateway
提供インターフェース
Terraform
Kubernetes yaml
普段当たり前のように実現できている通信もその提供機能は多岐に渡ります。 またネットワークもコンピューティング上で動作するコンポーネントが多く、いくつかの課題領域が絡み合って構成されていることがわかります。 ネットワークの上にはさらにメッセージング(システム間通信)の課題領域が存在します。
メッセージング(システム間通信)
本質的な課題
システムのパフォーマンスや開発生産性を上げるためには、システム間の協調パターンを規定してフレームワークによってそれが実践できることが重要である。
責務
大きく2つの方式をシステム間通信として提供する。リクエスト・レスポンス非同期メッセージング(パブリッシャー/サブスクライバー)
提供機能
gRPC (Ruby, Go, JavaScript)
Cloud PubSub (Ruby, Go)
提供インターフェース
subee (Client Library/OSS)
servicex (Client Library/Private)
Terraform
ここまででインフラチームが向き合っている課題領域の言語化をいくつか解説してきました。 これを普段のプラットフォーム開発、仕事では具体的にどう使うのでしょうか。 今チームで試していることは以下のようなものです。
プラットフォームの課題やアイディア、バグを発見した際にどの課題領域に属するものかを GitHub ラベルで分類する
プラットフォームの開発または運用を行うときは「どの課題領域に紐づく取り組みか」を明確に意識することで、 プラットフォームとして果たすべき責務に向き合っているかを考える一助になります。 思いついたアイディアはすでにプラットフォームに実装済みかも知れませんし、微妙に責務が違うかも知れません。 そしてその課題解決にはどんなインターフェースで実現されるべきか、いまあるものなのか新しいものなのか、そういったことを考える際にこの課題領域の整理はとても役に立ちます。 アイディアにラベルをつける運用はその思考をトリガーできます。GitHub のラベルなので、GitHub Projects でラベルごと数や推移が可視化できるのもの嬉しいところです。
この課題領域を共通言語としてチーム間で対話する
インフラチームが提供しているものはとても多く、他のチームからその全容は見えません。実際にプラットフォームを作っていくには、そのユーザーであるプロダクトチームに問題やボトルネックをヒアリングしたり、実際にプロダクトを作って体験する必要があります。そこで得られた問題やボトルネックをこの課題領域を使って分解・分類し、プラットフォームの機能や開発アイテムに落とす取り組みを行っています。
また、同じような課題領域を扱っている別のチームも存在します。 例えば Wantedly には Developer eXperience (DX Squad) というチームがありますが、このチームも CI/CDツールの管理、リリースエンジニアリング、開発環境の整備などを行っています。 この DX チームはインフラチームが提供するプラットフォームの利用者でもありますが、同時に同じような課題領域を解く協働者です。 彼らとうまく協働して開発組織全体でソフトウェアデリバリーのパフォーマンスを向上させるには、お互いに何をやっているかを理解し、定期的に対話することが必要です。 今回 DX チームの課題領域も整理してもらいお互いの課題領域を突き合わせてみることで「同じ課題領域でもアプローチが異なる」「チームの得意・苦手な領域が見えてくる」といった発見がありました。
今回は Wantedly のインフラチームが開発するプラットフォームについて、自分たちが向き合っている課題(提供している価値)の本質を認識し、 プラットフォームの価値の増幅や新たな課題発見、変化の必要性を見極めるために行った課題領域の整理方法を紹介しました。 ここからさらに「価値の計測」や「Lean にプラットフォーム開発を進める手法」など、 プラットフォーム開発のプロセスを実践し、その価値を高めていくことを継続的に行っていきます。続きはまた今度ブログにしたいと思います。

![]()



/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)