こんにちは!Wantedly の DX Squad で3週間のサマーインターンをしていた羽原です!
エンジニアの生産性の向上させるタスクに取り組んだので、その成果をまとめます!
インターンの目標
Wantedly では Kubernetes 前提
Wantedly はマイクロサービスでプロダクトを開発しています。また、そのうちの99%のサービスを Kubernetes で運用しています。
Kubernetes は学習コストの高いツールです。そこで Wantedly では、 kubectl のラッパーである kube という社内ツールを用意しています。Kubernetes に詳しくない開発者でも、気軽にデプロイや開発環境の準備ができるようになっています。
Kubefork で仮想的なクラスタを作れる
Wantedly は 140個のマイクロサービスからなる巨大なサービスです。このため、たった1つのマイクロサービスを変更したときでも、デプロイしてその挙動を確認することは本来難しいことです。
そこで Wantedly では、kube で提供されている kube fork という機能を使っています。
kube fork は
- 必要なマイクロサービスだけを複製し、
- 適切にマイクロサービスを繋ぎかえる
ことで、リクエストごとに「仮想的なクラスタ」が存在しているように見せることができます。
詳しい解説はこちらでされているので、興味のある方はぜひご覧ください。
Kubefork ではデータベースを複製できない
現状の kube fork は、データベースを複製できません。とはいえ、運用上ほとんど問題はありません。なぜなら、ほとんどの変更はアプリケーション内で完結するものだからです。
しかし、どうしてもデータベースを破壊的に変更して挙動を確認したい場合があります。
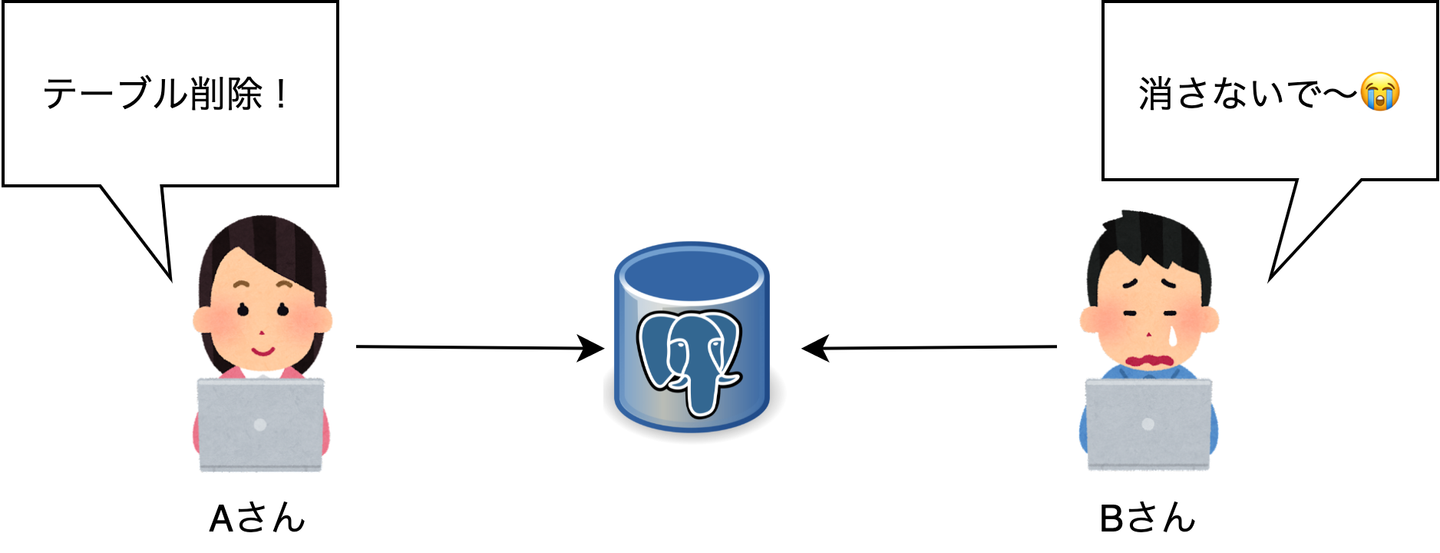
例えばAさんが自分の「仮想的なクラスタ」でデータベースのあるテーブルを削除したとします。このとき、Bさんも同じタイミングで開発をしていました。すると、Bさんが見ている「仮想的なクラスタ」のデータベースのテーブルも削除されてしまいます。
![]()
そこで、このインターンでは「データベースの検証環境を高速に作る」ことを目標に設定しました。
何が達成できれば良いのか?
目標を設定したので、次に具体的な問題に落とし込んでいきます。
前述の通り、kube fork によってリクエストごとに「仮想的なクラスタ」を提供する仕組みは実現されています。これはつまり、どのような仮想的なクラスタを作るべきかの判断に必要な情報は、全てリクエストに含まれているということです。ということは、特定の仮想的なクラスタでデータベースを切り替えたい場合、リクエストによってデータベースを指定する必要があるのです。
この結論は、問題を単純化することに繋がります。すなわち、アプリケーション内で「リクエストによってデータベースを指定する」ことができれば良いことがわかります。
また、データベースを高速に複製できる必要があります。
AWS Aurora エンジンではデータベースの Copy on Write が提供されています。https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.Managing.Clone.html
Wantedly で使われている Aurora データベースの複製にかかる時間を計測したところ、およそ5分ほどで複製ができることを確認しました。
5分とはいえ無視できない時間です。運用していくには、あらかじめいくつか複製したものを用意しておいて、開発者が使いたいときにすぐに渡せるようにする等の工夫が必要です。
ただし、これらは今考えるべき問題ではありません。いま真っ先に検証すべきなのは、リクエストによってデータベースを指定することができるか、ということです。
リクエストによってデータベースを指定する
Wantedly のアプリケーションは Rails で書かれているので、Rails 上でデータベースの切り替えができるかどうかを調査しました。
Rails の挙動と、実現したいこととのギャップ
調べていくと、Rails は設定ファイルに記述されたデータベースとの接続を「アプリケーション起動時に」確立していることがわかりました。
これはとても重大な問題です。なぜならば、リクエストによって指定された(複製した)データベースは、アプリケーション起動時には存在しない可能性があるからです。
いま実現したいことは「リクエストが来たときに」適切なデータベースへ接続することなので、ここには大きなギャップがあります。
そこで、Rails 上でデータベースの接続がどのように管理されているかを知る必要がありました。
Rails におけるデータベースの接続管理
※ これは執筆時点での最新 v6.1系 での解説になります。v6.0系だと違うので気をつけてください。
Rails では、複数のデータベース(ホストレベルで異なってもOK)を使うための仕組みが提供されています。
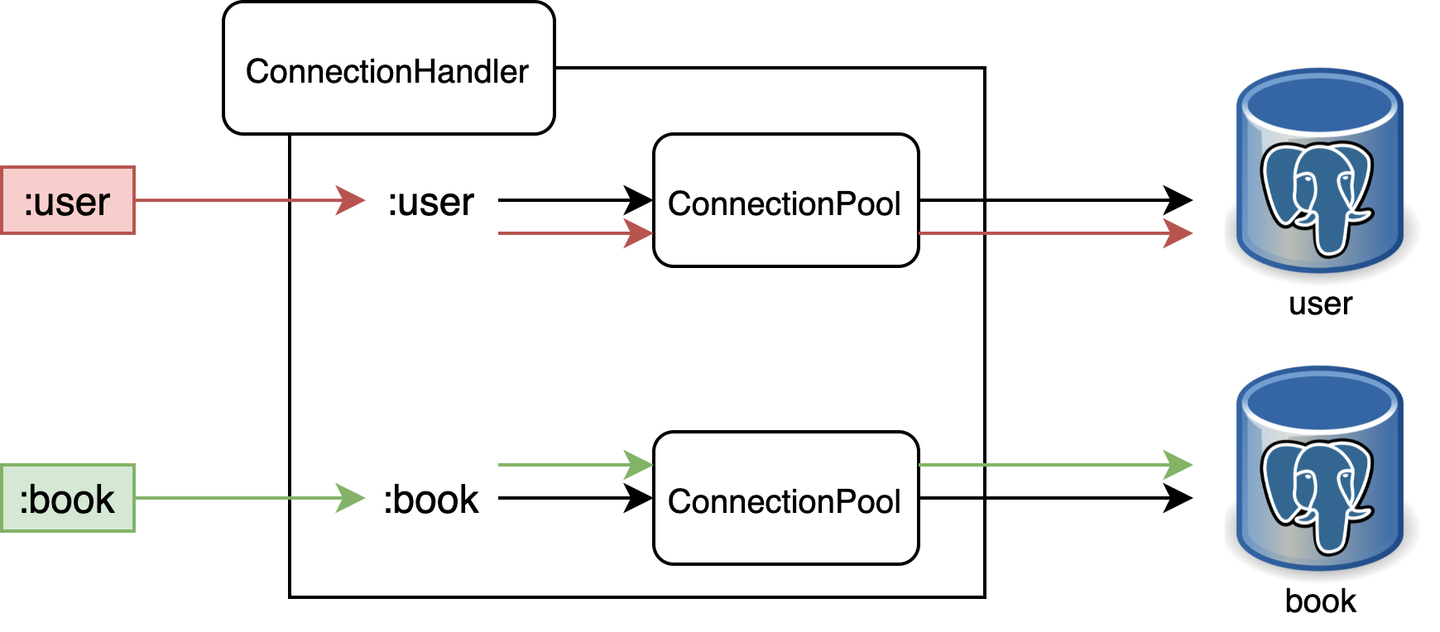
Rails において、データベースの接続は次のように管理されています。
ConnectionPool というオブジェクトがデータベースとの接続を保持しているConnectionHandler という共有変数がこれらを辞書のように管理している- アプリ起動時に接続されたデータベースにはキーが与えられており、そのキーを指定することで
ConnectionHandler から所望の ConnectionPool を得ることができる。
データベースキーは、例えば Wantedly では :primary, :primary_replica, :mail, :notification 等を使用しています。以下では、簡単のために :user と :book というキーに対応した 2つのデータベースを使うアプリケーションを例に説明していきます。
![]()
実装はこちらから確認することができます。
ConnectionHandler を wrap する
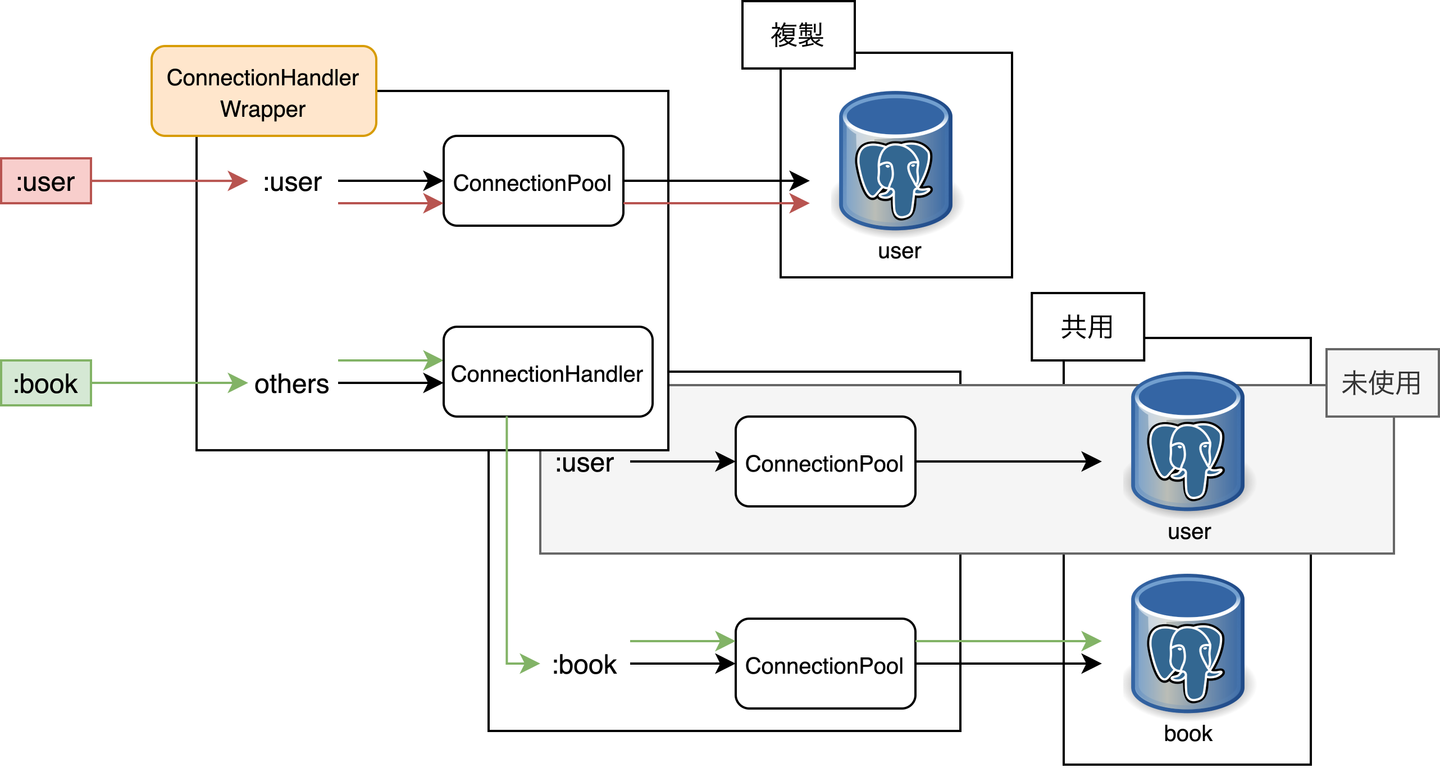
:user データベースに対してのみ破壊的な変更ができるような仮想的なクラスタを作りたい、という場合を考えます。このとき、:book データベースまで複製するのは効率的ではありません。
ここで実現したいことは、特定のデータベースキー(:user)に対応して、適切なデータベースに接続された ConnectionPool を取得できるようにすることです。ただし、接続先を変更する必要のないデータベースキー(:book)に対しては、今まで通りの ConnectionPool を返す必要があります。
そこで、元々の ConnectionHandler を wrap した ConnectionHandlerWrapper を作りました。
:user に対してだけは、複製したデータベースに繋がる ConnectionPool を返して、その他のキー(:book )に対しては元々の ConnectionPool を返すような仕組みになっています。
![]()
実装は次のようになりました。データベースのユーザー名、パスワード、データベース名をリクエストに流すのはセキュリティ上危険だという判断で、ホスト名だけを変更できる仕様となっています。
class ConnectionHandlerWrapper
def initialize(original, options)
@original = original
@options = options
@url_to_pool_config = {}
end
def method_missing(sym, *args)
@original.send(sym, *args)
end
def retrieve_connection(spec_name,
role: ActiveRecord::Base.current_role,
shard: ActiveRecord::Base.current_shard)
db_cfg = @original.retrieve_connection_pool(spec_name, role: role, shard: shard).db_config
if (database_url = replaced_url(db_cfg))
replaced_pool_config(database_url).pool.connection
else
@original.retrieve_connection(spec_name, role: role, shard: shard)
end
end
def disconnect!
@url_to_pool_config.values.each {|cfg|
cfg.disconnect!
}
end
private
def replaced_url(db_cfg)
key = db_cfg.name.to_sym
db_cfg_hash = db_cfg.configuration_hash
if (replaced_host = @options[key])
adapter = db_cfg_hash[:adapter]
user = db_cfg_hash[:username]
pass = db_cfg_hash[:password]
database = db_cfg_hash[:database]
"#{adapter}://#{user}:#{pass}@#{replaced_host}/#{database}"
end
end
def replaced_pool_config(database_url)
@url_to_pool_config[database_url] ||=
ActiveRecord::ConnectionAdapters::PoolConfig.new(
ActiveRecord::Base, ActiveRecord::Base.configurations.resolve(database_url)
)
end
end
ミドルウェアで ConnectionHandler を差し替える
リクエストごとに ConnectionHandler を ConnectionHandlerWrapper に変更することができれば完成です。これはミドルウェアを用いることで実現できます。
- リクエストが来たらヘッダを解析して、どのデータベースキーをどのホストに切り替えるのかを取得する
- その情報から
ConnectionHandlerWrapper を作成し、元の ConnectionHandler と入れ替える - リクエストの終わりには元の
ConnectionHandler に戻してあげる
という処理を書いたのが次の実装です。
Servicex::FeatureFlag::Interceptor というのは Wantedly の社内ライブラリで、ヘッダ情報を伝播させる際に必要な仕組みです。
また、ConnectionHandler を入れ替える処理は、こちらの swap_connection_handler の実装を参考にしました。 https://github.com/rails/rails/blob/246bac42a090524e5386912a4b955c327c6a4ba9/activerecord/lib/active_record/connection_handling.rb#L378
class ReplaceDbHostMiddleware
def initialize(app)
@app = app
end
def call(env)
options = parse_header
return @app.call(env) if options.nil?
with_connection_handler_wrapper(options) do
@app.call(env)
end
end
private
def parse_header
json_str = Servicex::FeatureFlag::Interceptor.intercept("replace_db_host") do nil end
return nil if json_str.nil?
JSON.parse(json_str, :symbolize_names => true)
rescue => e
nil
end
def with_connection_handler_wrapper(options, &blk)
old_handler = ActiveRecord::Base.connection_handler
ActiveRecord::Base.connection_handler =
ConnectionHandlerWrapper.new(old_handler, options)
return_value = yield
return_value.load if return_value.is_a? ActiveRecord::Relation
return_value
ensure
ActiveRecord::Base.connection_handler.disconnect!
ActiveRecord::Base.connection_handler = old_handler
end
end
こちらのPullRequestにもコードを載せています。https://github.com/wantedly/wantedly/pull/61006 (internal)
まとめ
このインターンで「データベースの検証環境を高速に作る」ことを目標に設定し、最終的に「Rails でリクエストごとに繋ぐデータベースを変える ConnectionHandler」を作りました。
Wantedly は現在 Rails v6.0 を使用しています。このインターンで作成したツールを使いたい!という思いが、Rails v6.1 への移行を後押ししてくれることを祈っています!
本当はこれらの機能を使いやすい形でパッケージ化するところまでしたかったのですが、3週間のインターンでは時間が足りませんでした!
メンターをしていただいた大坪さんには、技術的なサポートの他にも、仕事を進める上での思考の仕方を教えていただきました。大変勉強になりました!こちらの記事も参考にさせていただきました!
リモート参加ではありましたが、こまめにMTGの時間を取っていただいたこと、シャッフルランチ等でいろんな社員さんとお話しできたこともあり、孤独を感じずに作業することができました!本当にありがとうございました!

/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)





/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)