はじめに
新卒3年目に突入しましたnorth_mkyです。
エンジニアをしていると一度はコンピュータでの文字の扱いについて考えることがあるのではないでしょうか。 今回は、かなりの国の文字をカバーしている符号化文字集合、unicodeの特徴について書きます。
※今回はわかりやすさのために厳密性は求めない書き方をしている箇所があります。ご容赦くださいませ。
符号化文字集合のひとつです。
...と書くと頭にはてなが浮かぶかもしれません。
文字というのは世界規模だとかなりの数が存在します。 ただ文字を集めただけではまとまり(ひらがな、漢字、ラテンなど)を表現することが難しかったり形や使われ方の違う文字の統一的に管理することが難しいため、「この位置にこの文字をおいておく」というように文字を系統的に定義し、管理しやすくしています。この位置のことを符号位置(コードポイント)といい、字に対して必ず一意の数値で表される符号位置が存在する、つまり字を数値に表せる「符号化」を行っているため、”符号化文字集合”といいます。
unicodeの他にも符号化文字集合は世界の各地域で存在しています。 こと日本でいいますと文字として、「ひらがな・カタカナ・漢字・アルファベット」を使うため、それらの符号化文字集合の定義が必然となります。国内でこれらの文字に特化した有名な符号化文字集合はJIS X 0208
があります。
この符号化文字集合は単に字を符号位置という位置づけを付与し文字を定義し集めているだけなので、コンピュータで扱いやすい・処理されやすいよう更に特定のアルゴリズムで符号化をしていることが多いです。この符号化の種類のことを符号化方式といい、具体的には下記のように符号化文字集合を表現する複数の符号化方式が存在します。
符号化文字集合 符号化方式
unicode UTF-16, UTF-8...
JIS X 0208 Shift_jis, EUC-JP, ISO-2022-JP
と、少し長くなりました、話を元に戻しますとunicodeとは符号化文字集合の一つです。 webではデファクトスタンダードの符号化方式(文字コード)、UTF-8の文字はこのunicodeを符号化したものです。冒頭で述べた通り、unicodeは多くの国の文字をカバーしているのですが、それゆえに文字集合の表し方や字の定義の仕方に特徴があります。以下にその特徴を述べたいと思います。
unicodeには大きな特徴が4つあります。
- 特徴1. 4次元で一つの文字を表す
- 特徴2. 他の文字と組み合わせて使う合成用文字が存在する(結合文字)
- 特徴3. 同じ文字だが字体が異なる場合一つの字体に統合されている(統合文字)
- 特徴4. 他の符号化方式との互換性のため追加した文字が存在する(互換文字)
特徴1. 4次元で一つの文字を表す
unicodeでは符号位置は4次元で表しています。 擬似的に表現すると下記のようになります。
![]()
nicodeでは各々の次元をおおよそ1バイト(0x00~0xFF)の範囲で表現しており、1文字を4バイトの符号位置で表現しています。 かなりの符号空間を用意しているわけですが、全世界で現在利用している文字のほとんどはgroup:0x00,plain:0x00の範囲に収まっています。 この範囲だけ特別にBMP(Basic Multiligual plane:基本多言語面)というように呼ばれています。
unicodeエスケープ表記で表されている文字で「u\3042」というように2バイト表記されているものは、BMPに属しています。
- 「
u\3042
」=「group0x00/plane0x00の面にある、row0x30のcell0x42の符号位置」
ちなみにBMPにのれず、別のplaneにある文字として日本で使われている一部の漢字があります。 このplaneの文字を実装していないシステムだと文字がただしく表示されない事象が発生します。
- 文字があるはずの場所が空白
- □の中に×が表示されている文字になる
特徴2. 他の文字と組み合わせて使う合成用文字が存在する(結合文字)
unicodeでは複数の合成用文字(結合文字)を合成して1文字を表す、というのを実現可能にしています。 たとえば日本語の「ぱ」などの半濁音は合成用の半濁点がunicodeに存在するので、「は」+「 半濁点」で表現できます。(※他の符号化文字集合との変換性を考慮して合成用でない半濁点、そもそも「ぱ」だけで符号位置もあります、むずかしいですね...) ですので、たとえば「あ」に半濁点をつけるなど、文字として認識されていない文字を合成して1文字のすることがunicodeを用いれば可能になります。
特徴3. 同じ文字だが字体が異なる場合一つの字体に統合されている(統合文字)
漢字を用いる民族、として日本の他に中国・韓国・台湾がなどがありますが、同じ漢字の形で少し書き方が違うものが数多く存在します。(ex. 海|海) このような漢字はunicodeでは一つの字体に統合しています(統合文字)。
特徴4. 他の符号化方式との互換性のため追加した文字が存在する(互換文字)
特徴3で字体を統合している、といったものの、厄介な問題があります。 別の符号化方式では区別している文字らをunicodeに変換すると、その字体の違いが吸収され、もとの符号化方式での字体を再現することができない事象がおこります。 このような事象を解消するために他の符号化方式との互換性を目的として文字が追加されることがあります。追加したそれらは別途互換文字と呼ばれます。
3. unicodeは進化し続けている ~タイトル回収~
ざっくりunicodeについて特徴を述べたのですが、やはり「すべての文字を網羅する」のは非常に難しく、既存の符号化文字集合との互換性の対応は不可欠となっているようです。ですので、unicodeも進化していっています。最近は文字だけでなく、絵文字の追加も盛んに行われています。それに対してシステムが使っているunicodeのバージョンが異なると文字が表示されない現象がおこります。
タイトルに書いた顔文字ですが、まさしく特徴でお話した結合文字を駆使して作られています。 私の環境ですと、chromeでは一部文字が表示できませんでしたが、safariではきちんと文字が表示されました。
![]()
![]()
4. 終わりに
unicodeのざっくりした特徴を述べました。 何気なく単語として聞いているunicodeがどんなものなのか、掴めるようになりましたら幸いです。
5. 参考文献
今回の記事はこちらをとても参考にさせていただきました。
「第三水準漢字」「サロゲートペア」などの単語がどのカテゴリのどこに位置する話なのか、などがわかるかと思います。
/assets/images/13591618/original/8ae0fb88-7dbe-4a0e-8a4c-8bae31320ae2?1686812597)


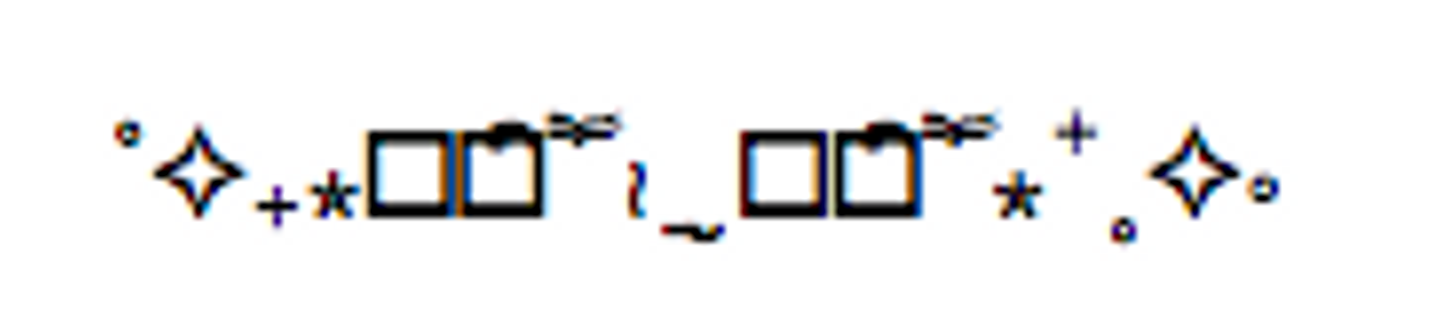

/assets/images/13591618/original/8ae0fb88-7dbe-4a0e-8a4c-8bae31320ae2?1686812597)


/assets/images/13591618/original/8ae0fb88-7dbe-4a0e-8a4c-8bae31320ae2?1686812597)
/assets/images/3039984/original/a0a33bf9-4e97-45f6-b2c6-9591063a1269.gif?1534903761)
