こんにちは! プログリットでエンジニア・マネージャーをしている島本(@diskshima、@diskshima@mastodon.cloud)です。
プログリットでは、日々お客様に英語学習の満足度を高められるかを日々考えて、様々な取り組みを行っています。その1つとして先日「プログリットスピーチチェッカー」というサービスを受講していただいているお客様に提供を開始させていただきました。
今回は、このサービスを作るまでの経緯をお話ししたいと思います。
背景ときっかけ
まず、今回作ったサービスの背景のトレーニングについて紹介させてください。
プログリットの英語学習サービスは、お客様に様々なトレーニングをパーソナライズして提供していますが、その一環で、お客様のスピーキング力を向上させるために、 スピーキングの練習をしていただくことがあります。その際、指標の1つとして、WPM/SPM(※1) を計測して、お客様にフィードバックをしています。
※1 WPM:Word Per Minute(1分間に何単語言えるか)、SPM:Sentence Per Minute(1分間に何文言えるか)
こちらのトレーニングをお客様に日々行っていただいているのですが、ある日、副社長のしゅんたさん(@ShuntaYamazaki)が会議中に
Whisper AI※2、メチャ精度良さそうですよね。なんかこれを使って、WPM/SPMを自動で計測するLINEボットとか作れないですかね?お客様が気軽に測れると良いですよね。
ということをふと話したことがきっかけです。
※2 OpenAIが提供する文字起こしAPI。詳しくはこちら。
どうせならChatGPT
雑談に近い話だったので最初は話半分ぐらいで聞いていましたが、仕組みを考えると
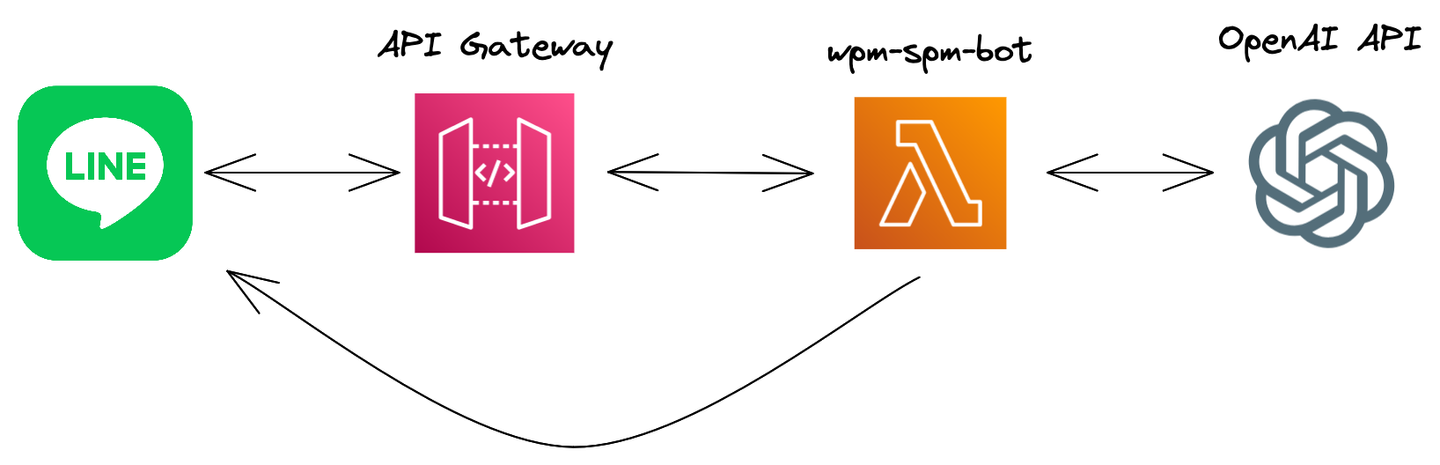
- LINE API:LINEボットのリクエストを処理するためのAPI
- AWS Lambda:リクエストを処理するためのAPI
- AWS API Gateway:上記、AWS Lambdaを外部より呼び出せるようにするためのサービス
- Whisper API:前述
を組み合わせて
![]()
というシンプルな構造になりそうですし、実質自分たちで書かないといけないコードはAWS Lambdaの部分だけですので、そこまで大変でもないかな、と思いました(弊社ではインフラはAWSをメインで使っています)。
更に「シンプルな構造だし、OpenAIつながりでChatGPTで書けるのでは?」と思い、早速試してみることにしました。
ChatGPTとの対話
とりあえず聞いてみる
悩んだりしても仕方がないので、とりあえず聞いてみることにしました。
ChatGPTはプロンプトが大事とよく言われます。また、主として英語の文章で学習したモデルですし、プログリットは英語コーチングを提供しておりますので、英語で聞いてみることにしました。
Can you create a LINE bot that accepts audio files, sends them to Whisper API and counts the sentences/words in the response text?
すると、それっぽい説明とコードサンプルが返ってきました。
![]()
もう少し続くのですが、最終的に以下のコードが返ってきました。
import os
from flask import Flask, request, abort
from linebot import LineBotApi, WebhookHandler
from linebot.exceptions import InvalidSignatureError
from linebot.models import MessageEvent, AudioMessage, TextSendMessage
import openai
app = Flask(__name__)
line_bot_api = LineBotApi(os.getenv("CHANNEL_ACCESS_TOKEN"))
handler = WebhookHandler(os.getenv("CHANNEL_SECRET"))
openai.api_key = os.getenv("OPENAI_API_KEY")
@app.route("/webhook", methods=["POST"])
def callback():
signature = request.headers["X-Line-Signature"]
body = request.get_data(as_text=True)
:
なんか雰囲気、動きそうですね 😄
AWS Lambda向けに
先程も書いたように自分としてはAWS Lambdaの利用を想定していたのでFlaskのようなフレームワークは不要ですね(動かせるかもしれませんが)。 ただ、自分も「AWS Lambda」とはどこにも記載していなかったので、この返答でもおかしくはないな、と思います。
ということで、次は単刀直入に
Would this work on AWS Lambda?
と聞いてみたところ、
![]()
という文章で始まり、
import os
import json
from linebot import LineBotApi, WebhookHandler
from linebot.exceptions import InvalidSignatureError
from linebot.models import MessageEvent, AudioMessage, TextSendMessage
import openai
line_bot_api = LineBotApi(os.getenv("CHANNEL_ACCESS_TOKEN"))
handler = WebhookHandler(os.getenv("CHANNEL_SECRET"))
openai.api_key = os.getenv("OPENAI_API_KEY")
def lambda_handler(event, context):
signature = event["headers"]["X-Line-Signature"]
body = event["body"]
try:
handler.handle(body, signature)
except InvalidSignatureError:
return {
"statusCode": 400,
"body": "Invalid signature"
}
return {
"statusCode": 200,
"body": "OK"
}
:
とAWS Lambda向けに書き換わったコードサンプルが返ってきました。
しかも、AWS Lambda上での操作方法なども書いてくれていました。
![]()
改めてChatGPT凄いですね。もうそのままでも動くのでは、と一瞬思いました。
課題
ここまでChatGPTは凄いという印象になりますが、ここから、いくつか課題が出てきました(ChatGPT起因のものとそうでないものがあります)。
課題1:パラメータ名を間違える
まず、LINEからメッセージが来た際にメッセージの署名を検証する必要がありますが、その際にLINEから送られてくるパラメータ名をChatGPTの生成したコードでは
signature = event["headers"]["X-Line-Signature"]
と読み出そうとしていましたが、実際の名前はx-line-signatureとすべて小文字です(参考)。
まあ、ヘッダーはX-と大文字を使うことも多いので、こうなってしまうのも理解できます。僕も大文字小文字を指定されていなかったら、ChatGPTと同じことをしていた気がします。
課題2:LINEの1秒制限
LINEのボットでは、LINEのサーバよりメッセージが送られてきた際には1秒以内に何かしらレスポンスを返さないといけません(注意:LINEで表示される返信ではありません)。
しかし、上記ChatGPTの出力したコードを使うと、同期的にOpenAIのAPIを呼び出して、そちらからのレスポンスを待ってしまうため、LINEへ1秒以内にレスポンスを返せる保証はありません。実際、そのまま使うと、LINEの公式ドキュメントに書いてあるようなエラーが発生し、LINEのチャット画面にもエラーが起きた旨が表示されてしまいます。
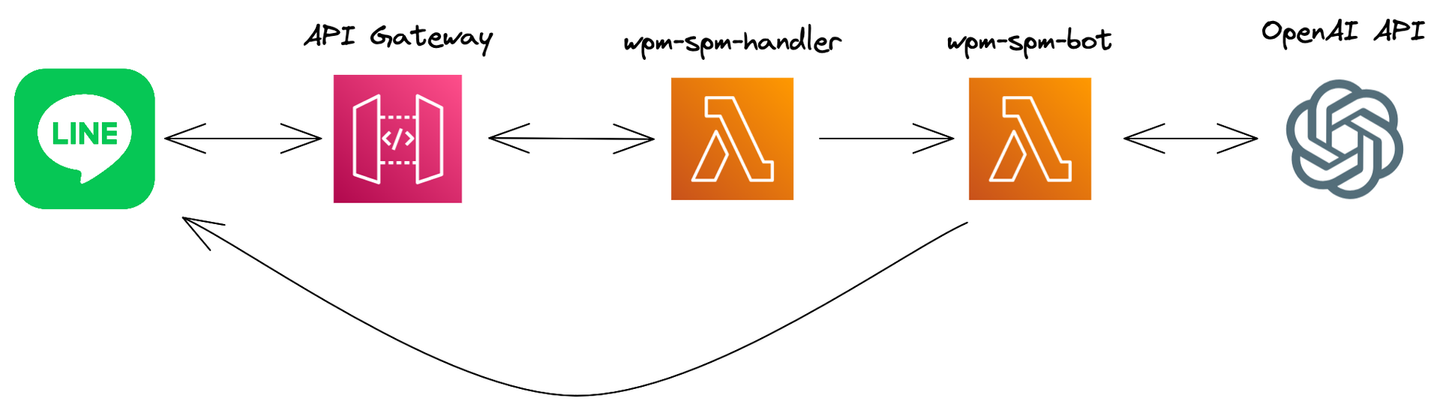
解決策としてはLINEからのメッセージを受け取るAWS Lambdaから、実際にOpenAIのAPIを呼び出す別のAWS Lambdaを呼び出し、1つ目のLambdaはすぐにLINEにレスポンスを返す、という方法を取りました。2つ目のLambdaでOpenAIのAPIを呼び出し、その内容をLINEのAPIを呼び出すことによりLINEのユーザに返事する、という流れになります。
つまりAWS Lambdaを2つ重ねるような形で、図で示すと以下のようになります。
![]()
1秒以内のレスポンスはLINEの細かい仕様ですし、LINEのドキュメントにも「レスポンスは1秒以内に返してください」と明言されているわけではないため、ChatGPTが反映させるのは難しいかもしれません。
課題3:ffmpeg/ffprobeのサイズ制限
3つ目に発生した問題として、利用するプログラムをLayerに入れる必要があったことです。
プログリットスピーチチェッカーではSPM/WPMの計測のために、Pythonのpydubというライブラリを利用しています。pydubは内部的に、音声ファイルの読み込みにffmpegというツールを使っています。そのため、Lambdaで利用するにはffmpeg(および同梱のffprobe)も一緒にデプロイする必要があります。 ただし、Lambdaではコードの容量は50MBまで、というサイズ制限があり、ffmpegとffprobeの両方を含めると50MBを超えてしまうため一緒にデプロイできません。
解決策としてはLambdaのLayer機能を利用しました。 Layerにffmpegとffprobeを入れたzipファイルをアップロードしておくと、Lambdaの実行時に自動的に展開されて、Lambdaコードより利用できるようになります。
ChatGPTとしては前提条件になる「Lambdaを利用していること」「ffmpeg/ffprobeが必要になること」はプロンプトの内容から把握はできると思いますが、返答の中にはLayerを利用することについては書かれていませんでした。さすがに自分が入れたプロンプトをすべて把握しつつ、Lambdaの制限についても把握しており、かつ、その制限に引っかかる可能性があることを関連付けないといけないので、さすがに難しかったようです。「ffmpeg/ffprobeを入れると容量が大きくなりすぎます」ということをプロンプトで送っていたら、おそらくLayerを利用することを提案できたかも知れません。
まとめ
今回は、Whisper APIを利用したプログリットスピーチチェッカーの開発をChatGPTを利用して開発した経緯やその課題について紹介しました。
ChatGPTは総じて、コードの補完や、いずれにせよ書かないといけないようなボイラープレートなコードを生成してくれる利便性は、とても高いな、と感じる反面、実際にその内容を実用化するまでには、細かい部分でのミスや、把握されていない部分での課題が出てきました。
また、最後に触れておきたいのですが、上記ボットはあくまでプロトタイプに近い形で僕が実装したもので、実際にデプロイされてお客様に利用していただいているものはチームの他のエンジニアがサービスとして利用できるようなクオリティまで引き上げた上で、提供しています。この部分をすべて生成AIで実現する、というのはまだまだ先かな、と思います。

/assets/images/4144660/original/d4876e94-48c0-405c-8b29-4aaa0f7128d9?1569914911)


/assets/images/4144660/original/d4876e94-48c0-405c-8b29-4aaa0f7128d9?1569914911)



/assets/images/6571325/original/d4876e94-48c0-405c-8b29-4aaa0f7128d9?1618570231)
