/assets/images/6899879/original/2fcf17aa-4638-4b0f-bc0f-f2f8122b147d?1622699171)
第3回:ドメインシフトと機械学習の性能低下
AI技術チームによる技術発信 AI技術チームの藤堂です。今回は、機械学習システムの本番運用において課題として生じるドメインシフトに関し、その概要と原因、対策についてご紹介します。 ...
https://www.mamezou.com/techinfo/ai_machinelearning_rpa/ai_tech_team/3
AI技術チームの藤堂です。今回は、機械学習システムの本番運用において課題として生じるドメインシフトに関し、その概要と原因、対策についてご紹介します。
ドメインシフトは学習データとテストデータの分布が一致しない状況を指し、それにより機械学習の性能低下に繋がることがあります。また機械学習システムの実験・開発から運用における特有の課題を解決するための取り組みであるMLOpsが注目される中で、ドメインシフトは取り組むべきテーマの一つとされています。さらにドメインシフトに関連する考え方や技術は、機械学習システムの本番運用時のみならず、「少数のラベル付けされたデータしか利用できない状況」において対策とされる転移学習やドメイン適応といった分野とも深く関連します。データの種類(テーブルデータ、画像データ、自然言語データ)にもよらないため、幅広い業界における機械学習システムの実験・開発・運用に関連する話題です。
機械学習では、アルゴリズムが過去の大量の学習データから統計的な特徴を学習し、新規のテストデータに対する未知の結果を予測します。このような仕組みの背景には、テストデータが、学習データと同一の分布に従うことを前提としています。しかし、実データは様々な要因でこの前提を崩し、とくに機械学習システムの実運用時に深刻な問題として表面化します。このことを理解するために、以下のようなシナリオを考えてみましょう。
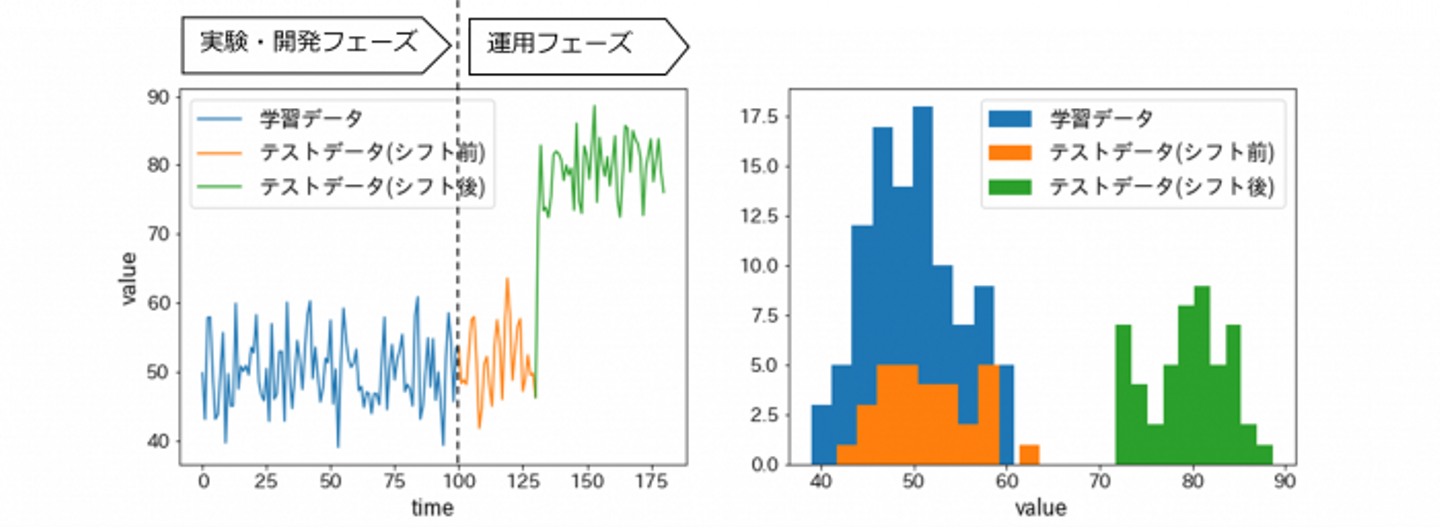
Figure 1. (左)ある説明変数valueの経時的変化. (右)説明変数valueの分布.
ある機械学習プロジェクトの実験フェーズにおいて、ある説明変数がFigure1右の青の分布に従う学習データに対し、機械学習モデルを学習させたとします。その学習済みモデルは十分な精度を出したことで、推論サーバに搭載し、実運用する運びとなりました。運用当初、テストデータ(注1)の分布(オレンジの分布)は実験時のものと変わらず、モデルのパフォーマンスは実験の結果を再現していました。しかしある日、データ前処理方法の一部変更に伴い、テストデータが以前とは明らかに異なる分布(緑の分布)に従うようになりました。その結果、目的変数の予測結果が大きく外れるようになり、その日を境にモデルのパフォーマンスが急激に下がってしまいました。
ここまで学習データとテストデータとして説明してきましたが、より一般に、それぞれソースドメインとターゲットドメインと呼ぶこともあります(注2)。ソースドメインとターゲットドメインの間で発生する分布のシフトのことを、ここではドメインシフト(domain shift)と呼びます(注3)。
ドメインシフトは先述のシナリオ以外にも様々な原因で発生します。ここでは2つの原因に分けて紹介します。
原因1学習データがテストデータを代表していない
(例)学習データに対する選択バイアス、交差検証時のリーク、実運用では使えない特徴量の実験時の使用、等々原因2データの非定常性
(例)コロナのような重大な出来事によるユーザー行動変化、装置・センサーの経年劣化、オペレーションの変更、敵対的シナリオ、等々
原因1は運用に移行した直後にドメインシフトが現れるのが特徴です。原因2は運用後しばらくしてドメインシフトが現れることが特徴です。その観点で、上記シナリオにおける「運用中のデータ前処理の変更」は、原因2に含まれます。また原因2に含まれる敵対的シナリオとは、既存システムが学習した概念を回避しようとする敵対者の存在により、データの非定常性が生じる状況を指します。古くから知られる例として迷惑メールフィルタリングやネットワーク侵入検知があり、近年では深層学習モデルを騙そうとする画像 (adversarial example) が注目されています[1]。
原因1は実験フェーズで対策をとることである程度回避できますが、原因2はデータ本来の性質を反映することもあり、回避困難です。このような背景から、運用フェーズにおいてドメインシフトは起こるものとして、予め策を講じておく必要があります。
注1)この場面でのテストデータは、運用中に推論に使用されるデータのことを指します。注2)ドメイン適応の分野においてドメインとは、説明変数X、目的変数Y、(X, Y)の確率分布の組み合わせを指します[2]。注3)ドメインシフト以外にも、データセットシフト(dataset shift)という用語も使用されます[3]。
機械学習システムを開発・導入・運用するためには、従来のシステムとは異なる知見が必要になります。そうした機械学習システム特有の課題に対するアプローチとして、MLOpsというキーワードが聞かれるようになりました。MLOpsにおいて、前述のドメインシフトへの対策として、継続的トレーニング(Continuous Training; CT)というアイデアが提案されています[4]。これは運用中に取得される新規のデータに対し継続的に再学習し、本番運用中の機械学習システムを更新していくことです。
一方で、下記のような理由でCTでは対応しきれないケースもあります。
このような課題への対策とされるのが、ドメイン適応や転移学習と呼ばれる分野となります。ドメイン適応・転移学習の目的は、ソースドメイン(学習データ)で使用したデータや学習済みモデルを、ターゲットドメイン(テストデータ)の学習・推論に活かすことで、ドメイン間の違いを克服することです。例えば、CTが提案されている論文において、Warm Startと呼ばれる手法が提案されています[4]。これは以前の機械学習モデル(ニューラルネットワーク)のパラメータの一部を新たな機械学習モデルの初期値として与え、新規データを学習する手法です。この手法により学習が早く収束し、モデルの性能も期待できます。
ドメイン適応は古くから研究されており、これまでに数多くの手法が提案されていますが、いわゆる万能な手法は存在しません[2]。データ・機械学習アルゴリズム・ドメインシフトの種類(注4)に依存して、有効な手法が異なることがあります。最悪の場合シフトに適応したはずが、逆に著しくパフォーマンスを落とす結果に繋がる可能性もあります。いくつかの有力な手法について、統計的なテストをはじめとした知見を確立することが必要となるでしょう。
機械学習が社会にもたらす恩恵が認知され、社会実装が進むにつれ、今後ドメインシフトの問題はより顕在化していくことが予想されます。一方で、実務家がこの問題に対しどのように取り組めばよいのか、プラクティスは確立されたとは言えないのが現状です。今後この問題に対する認知が広がり、分野にさらなる発展があることを期待しております。
次回の技術記事は10月を予定しております。
注4)ドメインシフトの種類として、説明変数の分布の変化を意味する共変量シフト(covariate shift)、目的変数の分布の変化を意味する事前確率シフト(prior probability shift)、説明変数と目的変数の間の条件付確率の変化を意味するコンセプトシフト(concept shift)に分類されます[3]。
[1]Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. "Explaining and harnessing adversarial examples." arXiv preprint arXiv:1412.6572 (2014).[2]Kouw, Wouter M., and Marco Loog. "A review of domain adaptation without target labels." IEEE transactions on pattern analysis and machine intelligence 43.3 (2019): 766-785.[3]Moreno-Torres, Jose G., et al. "A unifying view on dataset shift in classification." Pattern recognition 45.1 (2012): 521-530.[4]Baylor, Denis, et al. "Tfx: A tensorflow-based production-scale machine learning platform." Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2017.
※転載元の情報は上記執筆時点の情報です。
上記執筆後に転載元の情報が修正されることがあります。
/assets/images/6899879/original/2fcf17aa-4638-4b0f-bc0f-f2f8122b147d?1622699171)
![]()
/assets/images/6756250/original/4bfb75e2-33cb-4789-8c8d-2648546016b4?1621923439)