技術屋の宿命として、英文ドキュメントの読解がありますが、和文があればそれに越したことはありません。
最近は英文を機械翻訳で和文提供しているサイトもありますので、機械翻訳を使ってPDF化されている英文文書を翻訳することにチャレンジしてみました。
■契機
2010から2016のオフィスに切り替わった時に、wordがPDFファイルを結構賢くword文書に変換できることを知りました。
また、wordには名前を付けて保存するときに、様々な形式の文書に変換することができ、その中にhtmlも含まれていることから、その結果をgoogle翻訳で和訳すればうまくいくのではないかと考えました。
■懸念点
やるにあたっては色々心配な点がありました。
・PDFからWordが取り込んだ結果は使える品質か
・Wordが保存したhtmlは使い物になのか
・Google翻訳がローカルに保存されているhtmlファイルに適用できるのか
などなど
■結果
最終的にはPDF(英文)をhtml(和文 or 英文+翻訳)という形が実現できました。
■手順
作業は次の手順となります。
1. PDFをWordで開く
2. html形式で保存する
3. 英文htmlの内容を和訳する
4. 生成された結果の補正
ほぼWordに任せておけるのですが、一部のWordの不可解な振る舞いのため、手順4が必要になりました。
■例
仕事柄UMLとの付き合いが多いので、今回はUML2.5の最新ドキュメントを和訳してみましたので、その時の作業を例として示します。
UMLのドキュメントはOMGのサイトから入手します。
□手順1 PDFをWordで開く
PDFドキュメントformal-15-03-01.pdfをWordの「開く」機能で開きます。開くときには次のような確認が表示されます。。

確かに読み込みには結構時間がかかります。自分の環境では1分15秒ほどかかりました。
今回自分が欲しかったのは15 Activitiesだったので、この後の作業時間の短縮のために、必要なページだけを新しいPDFファイル"UML2.5-15 Activities.pdf"として切り出しました。これだと開くのに7秒でした。
読み込んだ結果を見ると、かなり良く内容が解析されていることがわかります。
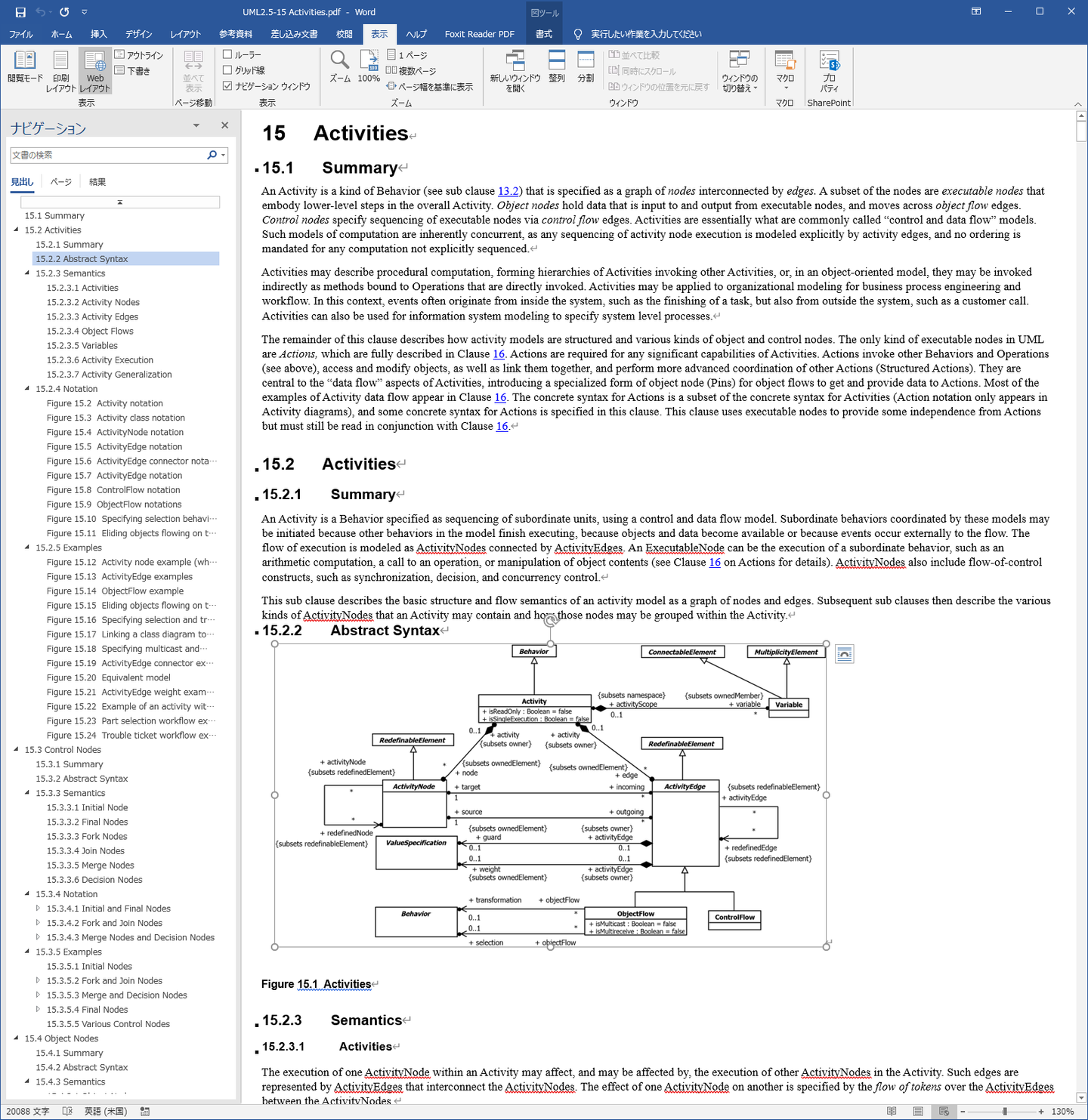
・見出しが識別されてスタイル設定されている
・図がイメージとして取り込まれている
この結果をみると、WordでPDFを取り込むことで、翻訳だけではなくPDF文書のデータ解析もかなりできそうな気がしてきます。
□手順2 html形式で保存する
「ファイル」「名前を付けて保存」を実行します。
「名前を付けて保存」ダイアログの「ファイルの種類(T)」で「Webページ(.htm;.html)」を選択します。
後はファイルの名前を入力して実行します。
うまくいくと、指定した名前のファイルとファイル名と同じ名前のサブフォルダが作成されます。
サブフォルダの中身を見ると、文書に含まれていたイメージファイルが保存されていることがわかります。
□手順3 英文htmlの内容を和訳する
これはとてもあっけないものでした。Chromeを使って生成されたhtmファイルを開くと次のように翻訳の問い合わせが登場します。
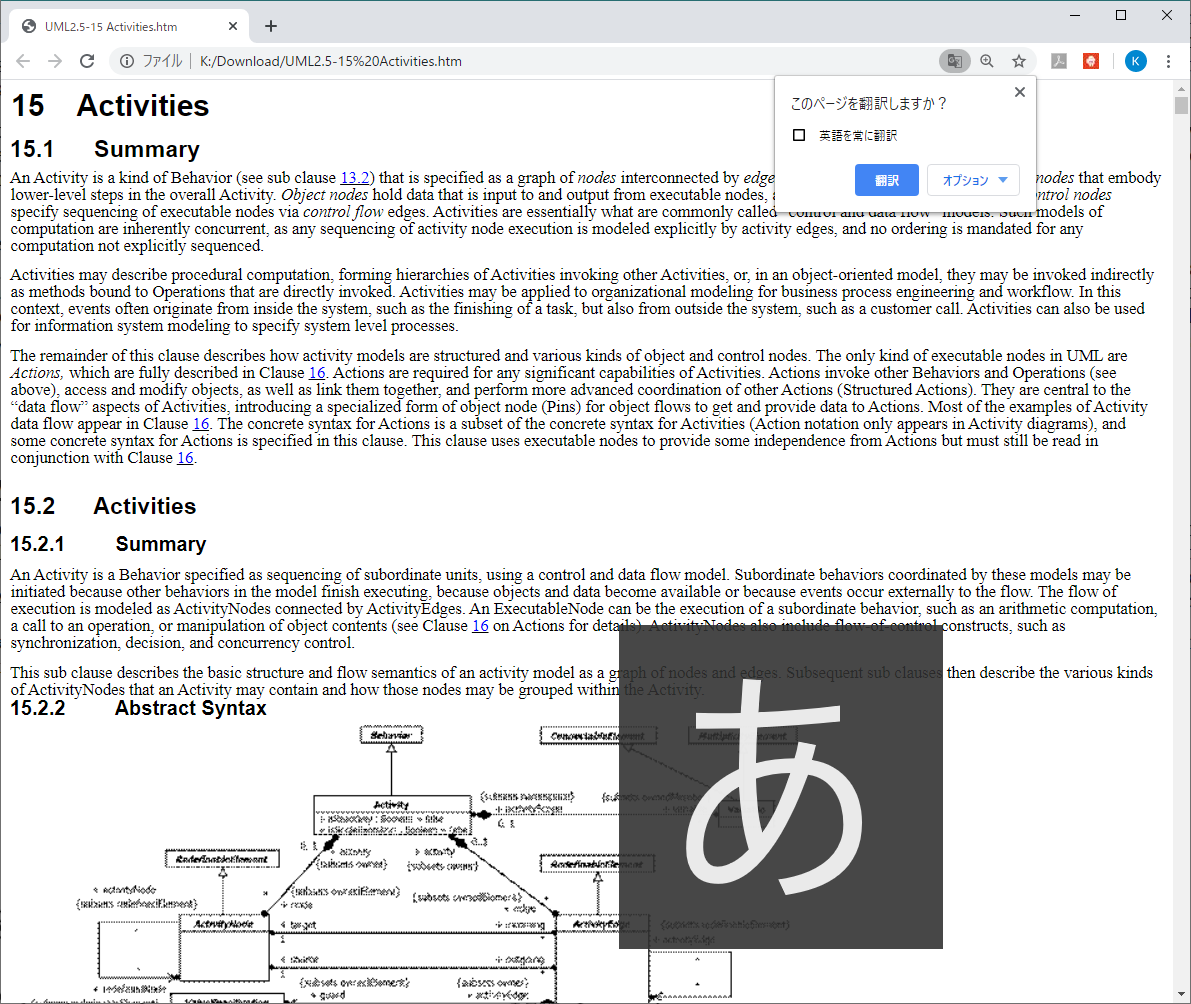
「翻訳」を選択すると、表示されている英文が和文に変換されます。
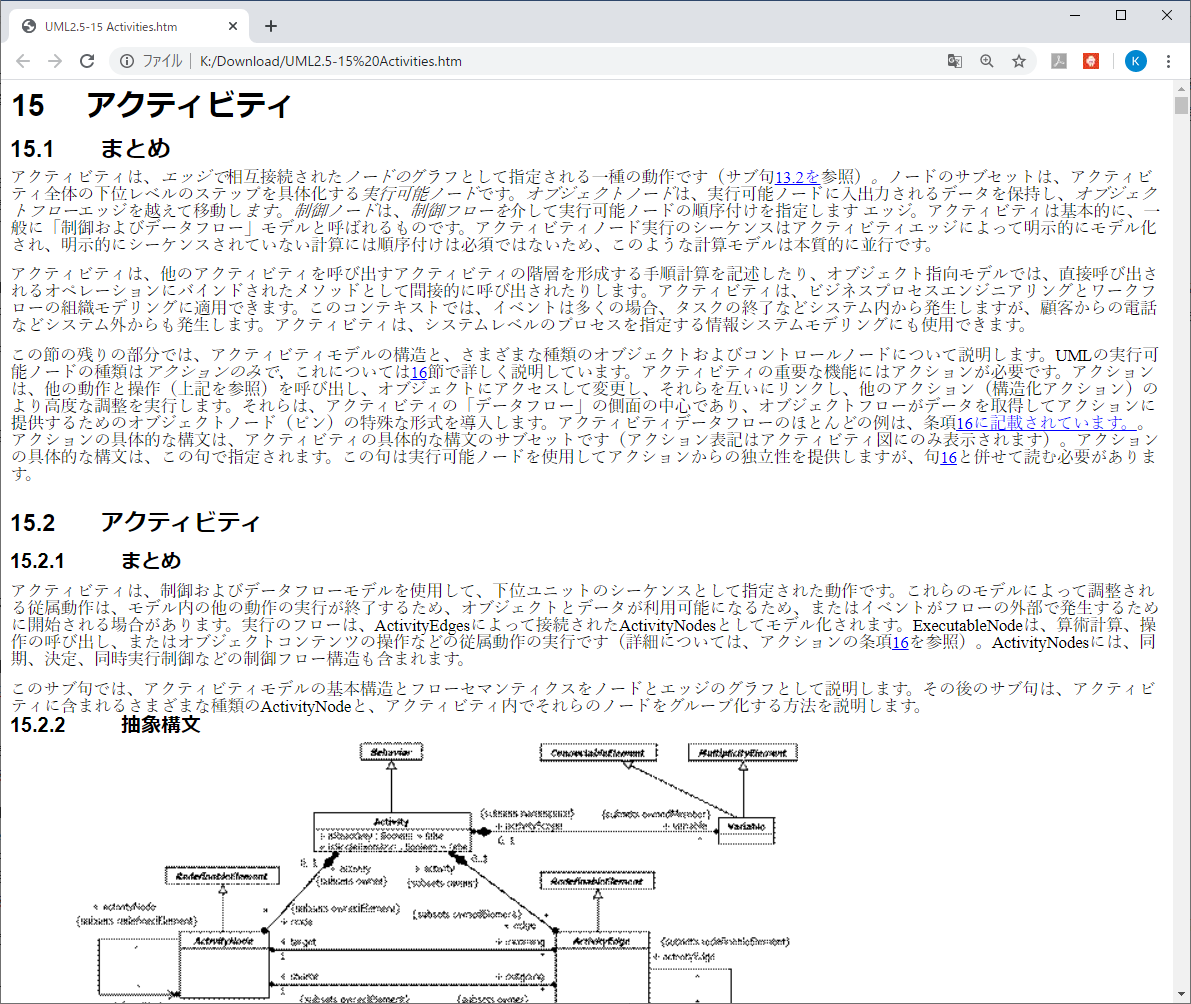
表示されていない範囲は翻訳されないので、翻訳応答はとても早いです。
隠れている文書を表示させると、順次翻訳されていきます。
ここで気になる点が2つあります。
1. 画像イメージがWordに表示されていた時の内容よりも粗い
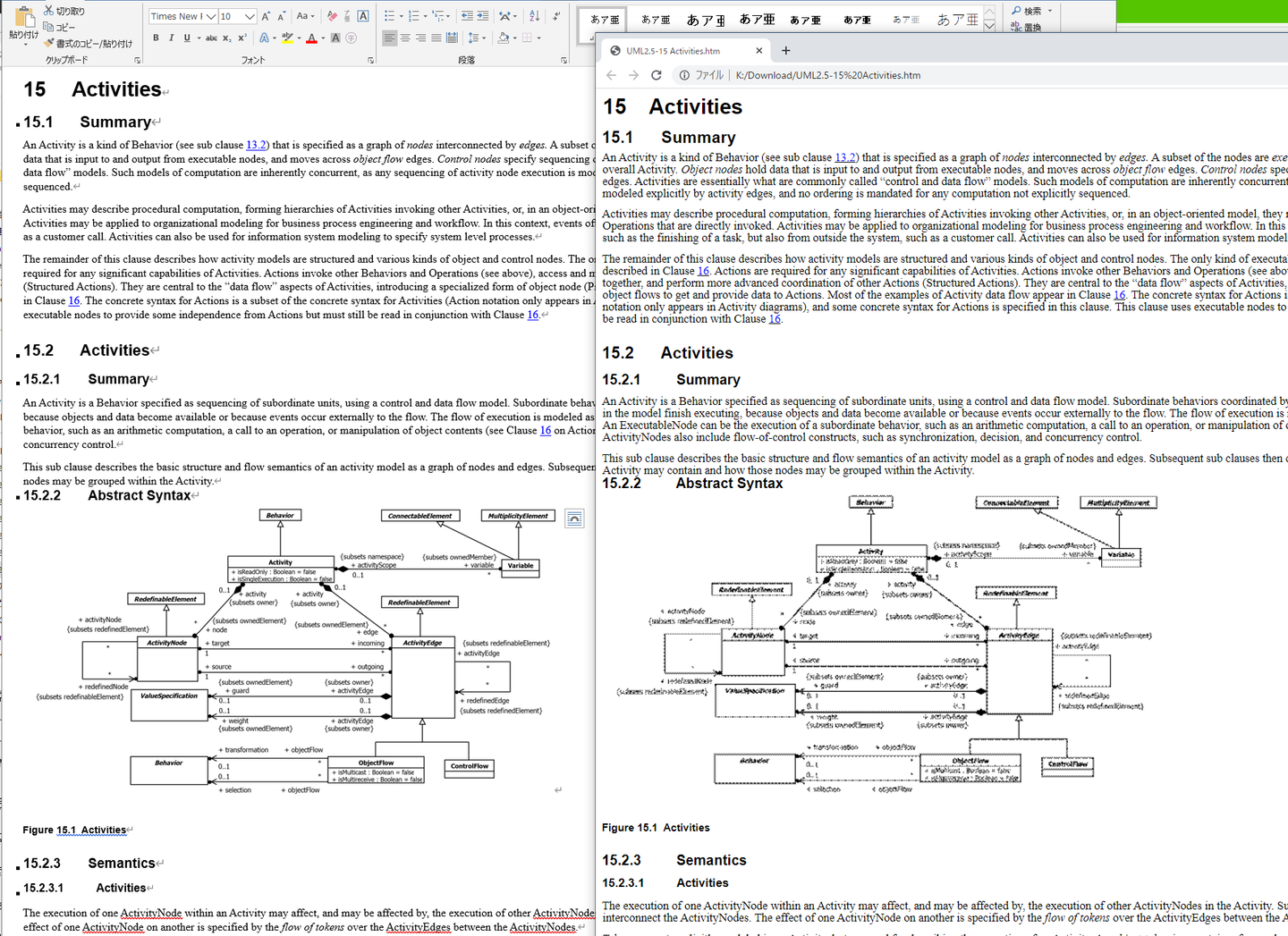
2. 翻訳前の原文を、文書単位に表示できない
2は今回の目的とは直接関係ないので、追うのはまたの機会にするとして、1についてはこのままでは翻訳ができても読むのに品質が不適切なので何とかしたいところです。
□手順4 生成された結果の補正
手順3で発見された問題点の対策をするため、生成されたファイルを調べてみたところ、次のことがわかりました。
1. htm保存時に作成されたサブフォルダには、画質の良いものと粗い物が存在する。
2. 1のファイルはhtmの中からどちらも参照するタグが存在しているが、なぜか良い画質の画像を使うタグがコメントアウトされている
※image001.pngが良い画質の画像で、image002.gifが粗い画像
良質の画像と粗い画像は条件によって使い分けるような記述がしてあるのですが、良質の画像を使うタグはコメントになっているので、このファイルを直接修正しない限り、画質の改善はできません。
一通り調べてみると、良質の画像と粗い画像は
<良質の画像を表示するタグ>
<粗い画質の画像を表示するタグ>
というパターンになっているようでした。
試しに粗い画質の画像ファイル名を良い画質のファイル名に置換してみたところ、問題なく表示されました。
そこで、<粗い画像の画像を表示するタグ>のファイル名を<良質の画像を表示するタグ>に記載されているファイル名で置換することにします。
作業はPythonあたりでコードを書くのもありかもしれませんが、最近のテキストエディタは正規表現置換も完備されているので、フリーで使えるテキストエディタの正規表現置換機能を使って作業しようと思います。
いつも使っているサクラエディタをにも正規表現置換機能があるので、それで・・・と思ったのですが、一つ罠がありました。
今回置換しようとしているテキストは複数行にわたっているため、検索パターンを複数行に適用する必要があるのですが、サクラエディタではそれができませんでした。
そこで急遽希望に合う機能を持つフリーのテキストエディタを探した結果、Sublime Textにたどり着きました。英語版のソフトですが日本語にも対応可能なようです。しかし、今回はテキスト置換機能が欲しいだけなので、その点には触れません。
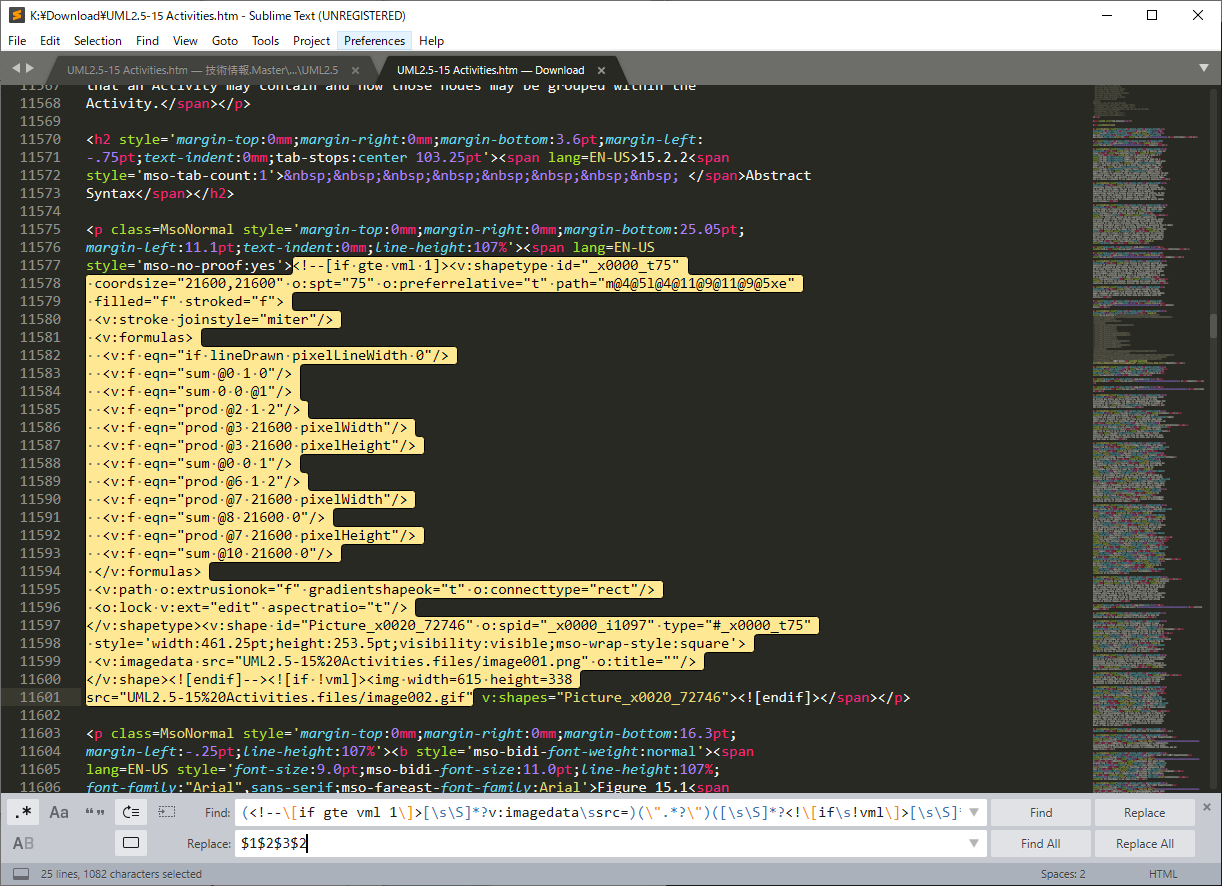
次の置換パターンを使って実施します。
【検索】(<!--[if gte vml 1]>[\s\S]*?v:imagedata\ssrc=)(\".*?\")([\s\S]*?<![if\s!vml]>[\s\S]*?<img\s[\s\S]*?src=)(\".*?\")
【置換】$1$2$3$2
これで完了!と思いきや、変換結果を見ていたら、次のようなとんでもない画像があることに気づきました。
これはいったい何だろうとみてみると、
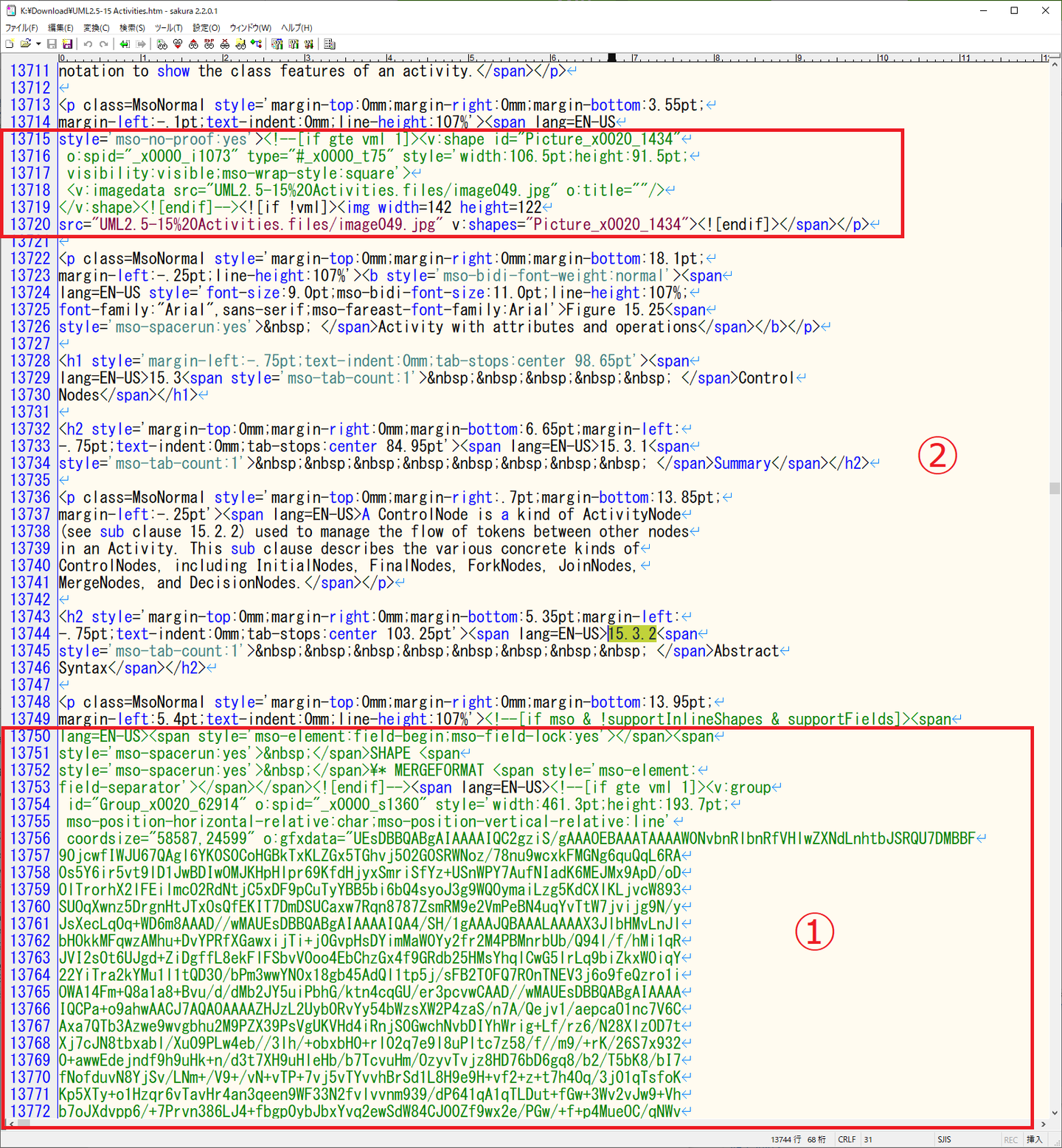
①のようになってました。これまでの記述は②になるのですが、比べてみると参照ではなく埋め込まれていることがわかります。
これはもうhtmファイルを修正する次元の問題ではないので、ひとつまえのWordに取り込んだ結果を確認見る必要があります。
Wordの該当箇所を見ると、次のようになってました。
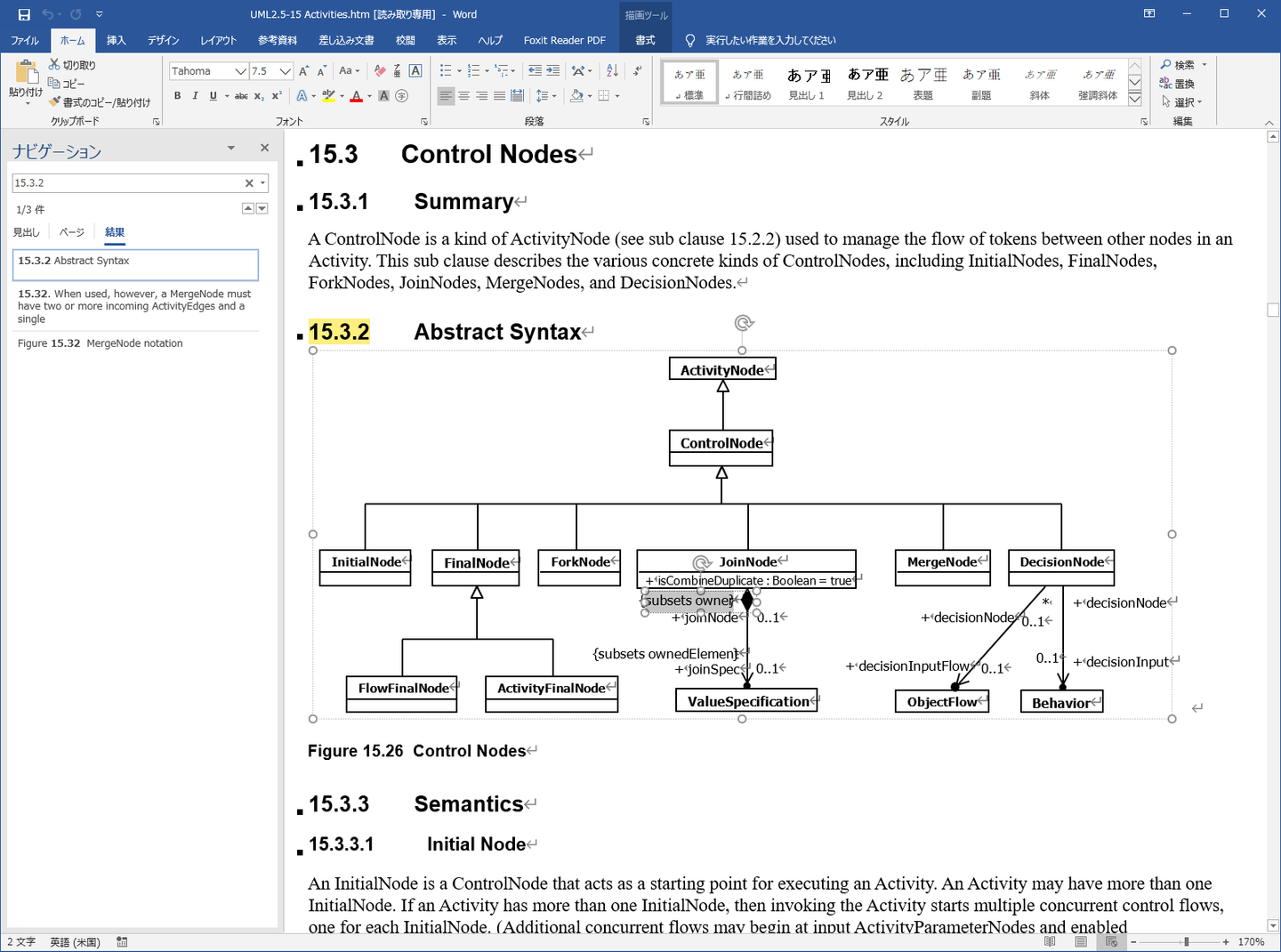
画像イメージに加えてテキストが一部文字として認識されていました。結果、画面は複数の要素から構成される合成図形のようになっています。
これをほかの画像のように出力する方法は見当たらないので、すっぱりとこのような状態の画像はPDFから画像をコピーして貼り替えることにします。今ある図形を削除し、その場所にAcrobat DCである画像のスナップショットでコピーした画像を貼り付けます。そして、その結果をhtml形式で保存します。
まとめると、補正作業は次の2点となります。
1. 低解像度の画像ファイルの代わりに高解像度の画像ファイルを指定するように
2. htmlファイルに埋め込まれているイメージの貼り替え
■さいごに
和訳といってもそこは機械翻訳、変な結果もあります。
うまい具合に、英文htmlをGoogle翻訳した結果は、Choromeの「名前を付けて保存」機能で保存すると、翻訳した結果のhtmlファイルになります。その結果を使って気になる翻訳ミスを修正したファイルを作ることで、より読みやすい内容に仕上げていくことができます。
また、読みやすいという点では、Wordが作ったhtmlファイルの行間が狭いことや、フォントの種類で少し好みとはずれている点がありました。正しい修正かどうかは自信ありませんが、次の個所を修正することで、全体の基本的な表示スタイルを調整することができました。
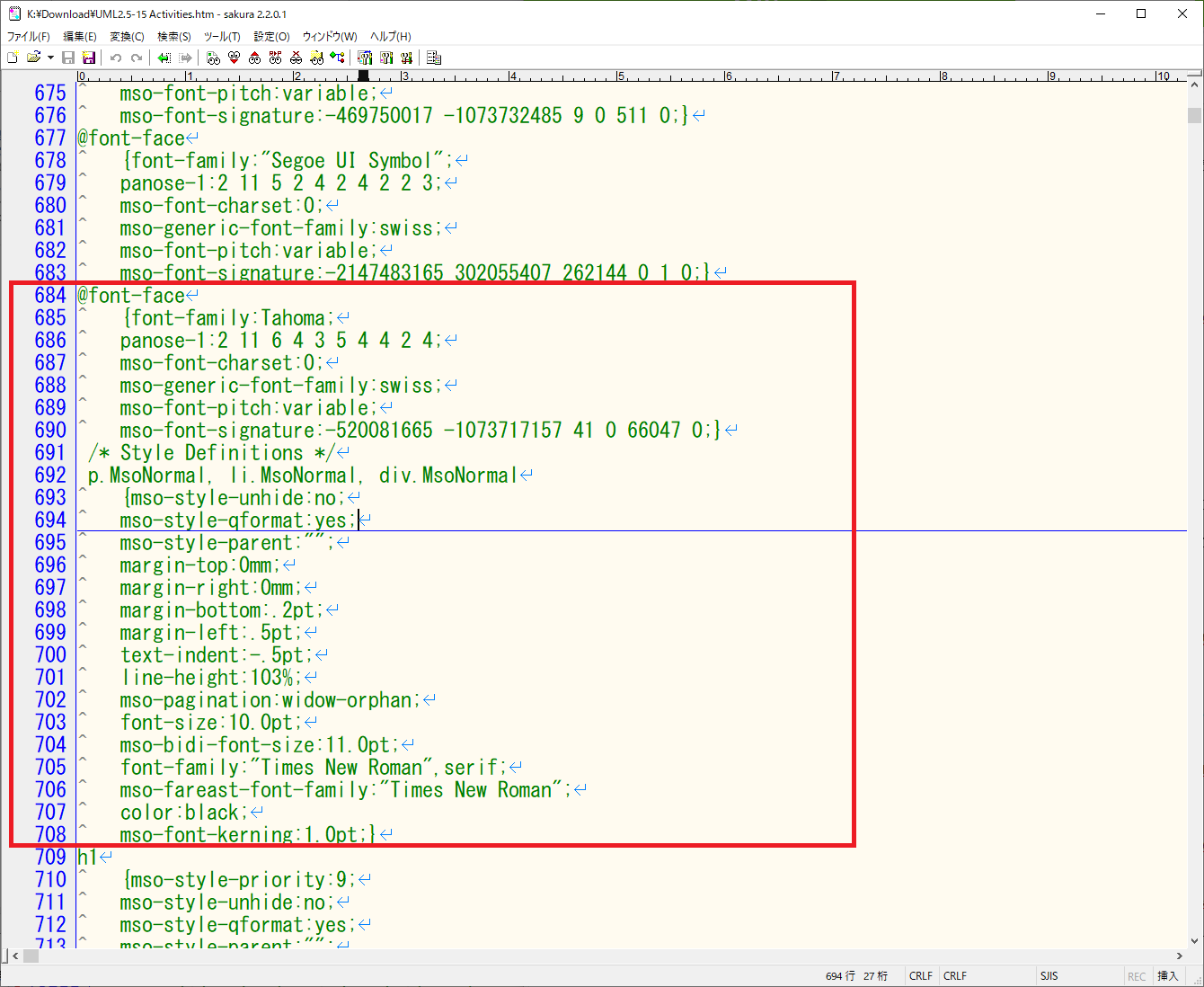
この後に続く部分も、修正すると見出しなどの表現を調整できそうな気がしますが、ここは本題ではないのでここまでとします。
他の方の英文ドキュメントとの付き合い方のご参考になれば幸いです。
※転載元の情報は上記執筆時点の情報です。
上記執筆後に転載元の情報が修正されることがあります。
執筆者のページはこちら
/assets/images/6899879/original/2fcf17aa-4638-4b0f-bc0f-f2f8122b147d?1622699171)


/assets/images/6899879/original/2fcf17aa-4638-4b0f-bc0f-f2f8122b147d?1622699171)
