
東京
中途
ストックマーク株式会社のメンバー
取締役CTO
東京大学大学院情報理工学系研究科修士課程卒業(2010年)
新日鉄住金ソリューションズ(2010〜16年) 2000人月規模の会計業務システム開発等にてチームマネージャとして従事し、若手優秀コンサルタントに選出される。
大学院時代の研究に基づく総合的なプログラミング力が強み。専門は超データ並列計算の実装。ビッグデータ解析分野に精通し、自動分類、レコメンドアルゴリズムは専門分野。さらにPHP・java・Swift等幅広く一人でこなすスーパーエンジニア。
システム企画~実装までを20名以上のチームを率いて行う実行力も兼ね備えている。グローバル開発も対応可能。
なにをやっているのか
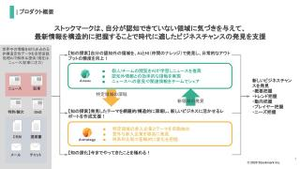
ストックマークは、自分が認知できていない領域に気づきを与えて、最新情報を構造的に把握することで時代に適したビジネスチャンスの発見を支援

Anewsは、有償サービス利用/累計250社へ。Astrategyは、有償サービス利用/累計50社へ
ストックマークが解決する社会課題は、日本の海外との競争力の低下です。
国内GDPの20%を占める最大産業である『製造業を中心に国内エンタープライズ企業』は、イノベーションのジレンマを抱えています。
イノベーションを作り出す最前線で働かれている、商品開発・技術開発・事業開発・R&Dの担当者は、イノベーションを生み出すために、自社の技術を活かす用途探索&技術分析、マートケット理解を進めるために市場調査を行われていますが、情報のスピードが速く膨大にある現代において、人間の力や、既存のツールでは、対応しきれない実態があります。
弊社は、社内外にある世の中にある膨大なテキストデータを自然言語処理AIで解析し、次世代のアイデア創出ができる仕組みを、自社のSaasプラットフォームを通じて提供しています。
是非、次世代のビジネスパーソンのプラットフォームを生み出し、人類にとってイノベーションの絶えない豊かな社会を実現していきましょう!
▼サービス紹介
ストックマークのサービスは、日英中の3.5万サイトもの膨大な情報網から、自然言語処理を活用して、ニュース/ IR / 特許 / 論文 / 社内資料を解析し、最適な形で情報をお届けし、次世代のイノベーション創出&アイデア創出の仕組みを提供し、新しくビジネスチャンスを発掘する支援を行っております。
▼Anews(エーニュース)
情報収集SaaS
業務に直結する情報をAIとヒトのナレッジから、個人/チーム/組織単位で収集が可能
組織全体の「暗黙知」を「形式知」に変えて、組織全体の情報感度を高め、
事業アイディアの着想と組織内での発展を促します
▼Astrategy(エーストラテジー)
市場分析SaaS
AIが技術や事例/リスク&チャンスなど該当情報の意味を理解した情報を、市場分析から将来予測が可能なデータにしご提供することで、様々な分析が可能
▼お客様紹介
日経225を中心とした日本の大手企業が利用
パナソニック様、日立製作所様、味の素様、みずほ銀行様、帝人様、セブン銀行様、三菱商事様、サントリー様、JTB様、リクルートホールディングス様、リクルートキャリア様、ソフトバンク様
など
【関連資料】
▼【超オススメ】いま注目のAI!自然言語処理の実社会活用と未来構想 〜アカデミック、ベンチャーキャピタル、海外動向、スタートアップから見た実態〜
https://youtu.be/YzSa9aUTk8o
▼CEO林 インタビュー動画
https://youtu.be/nNAG1uByRbY
▼CTO有馬 インタビュー動画
https://youtu.be/yFsB0GfwaFU
▼Technology Fast50 2022 Japan
https://stockmark.co.jp/news/20230519
▼Stockmark オープン社内報(Youtube)
https://youtube.com/playlist?list=PLrZHMFQXt_asWdFjymZAIc1h6WrE4kKBa
▼coevo 当社運営のオウンドメディア
https://stockmark.co.jp/coevo
なぜやるのか
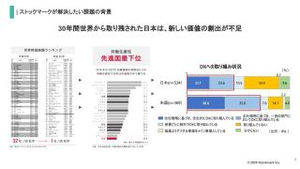
30年間世界から取り残された日本は、新しい価値の創出が不足
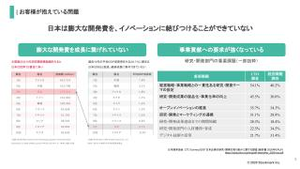
日本は膨大な開発費を、イノベーションに結びつけることができていない
イノベーションを生み出すための、「効率化」の課題は、様々なサービスがリリースされ、解くべき課題ではなく、やることが当たり前の社会となりました。
だからこそ、スタートアップの次なる課題は、「効率化」の先にある、イノベーションを生み出し、日本から競争力を生み出す最前線に立つことであると考えます。
どうやっているのか

左からCEO林、CTO有馬

社内の忘年会の様子です!
「カスタマーサクセスセントリックに意思決定をする自律分散型組織へ」
当社は、お客様のサクセスを中心に意思決定をすることを重視しています。
そうすることによって、現場でスピーディに意思決定が可能になり、より自律したチームとなっていくことができ、お客様から必要とされる提供価値を作り続けていくことができます。
また、カオスな状態でも、お客様を中心にできる方法を考え自律的に動くことができるからこそ、仕事を楽しく、自分ごとにしながら、高いパフォーマンスが出せるチームになっていきます。
こんなことやります
【業務内容】
Research部門では、自然言語処理や機械学習の研究開発を行うとともに、プロダクトチームと密接に連携しながら、プロダクトの自然言語処理や機械学習機能の開発を行なっております。また、東北大学乾研究室との知識グラフに関する共同研究や「BERTによる自然言語処理入門(オーム社)」の出版なども行っています。
当ポジションはResearch部門における自然言語処理・機械学習の研究開発のリードをお任せします。
■具体的な業務内容
・プロダクトにおける自然言語処理・機械学習機能の開発
・固有表現抽出やテキスト分類などを用いたニュース記事の構造化の手法の開発
・ニュース記事からのビジネスに有用な知識グラフの構築
・ニュース記事のレコメンデーションの手法の開発
・ニュース、論文/特許やビジネス文書全般からの文章要約・文章生成に関する研究開発
※変更の範囲:開発関連業務
【開発環境】
[組織体制]
Research Division(9名) - LLM Unit(3名)
[主な使用言語]
Python
【ポジションの魅力】
・1億記事以上のニュースデータベース及び大手企業250社に導入されているAnewsのユーザーログ、これらのデータを使った研究開発が可能
・最先端の機械学習・自然言語処理技術を用いてプロダクトを開発できる
・日本語かつビジネス領域における自然言語解析分野においてはトップランナー
・研究開発とプロダクト開発の距離が近く、研究開発の成果がプロダクトに導入されやすい
【必須スキル】※すべて必須
・自然言語処理に対する深い知識と業務経験
・理工系大学院修了
【歓迎スキル】
①以下のいずれかの技術の研究・実務での経験
・BERTなどの深層学習の言語モデル
・固有表現抽出、テキスト分類、関係抽出
・知識グラフ
・文章生成、機械翻訳
・構文解析、係り受け解析、意味解析
②査読あり国際学会や英文学術誌での論文採択の実績
【求める人物像】
・本質的にテクノロジーに興味があり、その分野の第一人者となる気概がある
・論文を読みながら最新の理論をフォロー、検証するのが好き
・ビジネスサイドとコミュニケーションしながら、いかにお客様に届け、事業を成長させるかを考えられる ▼その他
・入社後、必要に応じて東京オフィスへの出社が可能な方
・開発に関する技術的な内容含め、日本語で円滑にコミュニケーション可能な方
目安:日常会話レベル
最後に
当社は、独自の自然言語処理AIを活用した、AI SaaSで日本企業の成長を後押しすることを目指していスタートアップです。2022年8月にはSeriesCラウンドにて総額11億円を実施し累計30億円の資金調達を行い、これから急速に成長をしていくために、当社の技術観点でのブランディング向上およびプロダクトへのムーンショット技術開発を目的とした機械学習リサーチャーを増員募集いたします。
リモートワークなど、働きやすさも大事にしていますので、少しでも気になることがありましたら、ぜひ、まずは気軽にお話させてください!「話を聞いてみたい」よりエントリーお待ちしています。
お会いできることを楽しみにしています!
【関連資料】
・弊社Researchページ(メンバーのプロフィールもご覧ください)
https://stockmark.co.jp/research
・より多くの “気づき” を届ける- 世界中のテキストの構造化に挑む Knowledge Unit の紹介 -
https://tech.stockmark.co.jp/blog/about_knowledge_unit/
・「東大特任准教授が、次なるステージとしてストックマークを選んだ理由。」
https://www.wantedly.com/companies/stockmark/post_articles/292935
・「自然言語処理の分野で40年活躍してきた研究員がストックマークを選んだ理由」
https://www.wantedly.com/companies/stockmark/post_articles/336467
・日本ガイシ株式会社 新規用途探索の高精度化・高速化を目的に ストックマークの独自LLMを活用した実証実験を開始
https://stockmark.co.jp/news/20240208
・日本経済新聞:日本ガイシとストックマーク、新規事業開拓に生成AI
https://www.nikkei.com/article/DGXZQOUC072VC0X00C24A2000000/
0人がこの募集を応援しています
会社の注目のストーリー
ストックマーク株式会社の他の募集
- デジタルマーケティング担当
デジタルマーケター|全体戦略設計から担当生成AIプロダクトのリード獲得
- デジタルマーケティング担当
デジタルマーケター募集|全体戦略設計から担当生成AIプロダクトのリード獲得
話を聞きに行くステップ
- 応募する「話を聞きに行きたい」から応募
- 会社からの返信を待つ
- 話す日程を決める
- 話を聞きに行く
募集の特徴
オンライン面談OK
会社情報
2016/11に設立
81人のメンバー
- 1億円以上の資金を調達済み/
- 3000万円以上の資金を調達済み/
東京都港区南青山1丁目12-3 LIFORK MINAMI AOYAMA S209