
東京
中途
ストックマーク株式会社のメンバー
取締役CTO
東京大学大学院情報理工学系研究科修士課程卒業(2010年)
新日鉄住金ソリューションズ(2010〜16年) 2000人月規模の会計業務システム開発等にてチームマネージャとして従事し、若手優秀コンサルタントに選出される。
大学院時代の研究に基づく総合的なプログラミング力が強み。専門は超データ並列計算の実装。ビッグデータ解析分野に精通し、自動分類、レコメンドアルゴリズムは専門分野。さらにPHP・java・Swift等幅広く一人でこなすスーパーエンジニア。
システム企画~実装までを20名以上のチームを率いて行う実行力も兼ね備えている。グローバル開発も対応可能。
なにをやっているのか
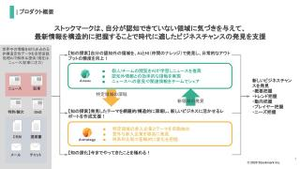
ストックマークは、自分が認知できていない領域に気づきを与えて、最新情報を構造的に把握することで時代に適したビジネスチャンスの発見を支援

Anewsは、有償サービス利用/累計250社へ。Astrategyは、有償サービス利用/累計50社へ
ストックマークが解決する社会課題は、日本の海外との競争力の低下です。
国内GDPの20%を占める最大産業である『製造業を中心に国内エンタープライズ企業』は、イノベーションのジレンマを抱えています。
イノベーションを作り出す最前線で働かれている、商品開発・技術開発・事業開発・R&Dの担当者は、イノベーションを生み出すために、自社の技術を活かす用途探索&技術分析、マートケット理解を進めるために市場調査を行われていますが、情報のスピードが速く膨大にある現代において、人間の力や、既存のツールでは、対応しきれない実態があります。
弊社は、社内外にある世の中にある膨大なテキストデータを自然言語処理AIで解析し、次世代のアイデア創出ができる仕組みを、自社のSaasプラットフォームを通じて提供しています。
是非、次世代のビジネスパーソンのプラットフォームを生み出し、人類にとってイノベーションの絶えない豊かな社会を実現していきましょう!
▼サービス紹介
ストックマークのサービスは、日英中の3.5万サイトもの膨大な情報網から、自然言語処理を活用して、ニュース/ IR / 特許 / 論文 / 社内資料を解析し、最適な形で情報をお届けし、次世代のイノベーション創出&アイデア創出の仕組みを提供し、新しくビジネスチャンスを発掘する支援を行っております。
▼Anews(エーニュース)
情報収集SaaS
業務に直結する情報をAIとヒトのナレッジから、個人/チーム/組織単位で収集が可能
組織全体の「暗黙知」を「形式知」に変えて、組織全体の情報感度を高め、
事業アイディアの着想と組織内での発展を促します
▼Astrategy(エーストラテジー)
市場分析SaaS
AIが技術や事例/リスク&チャンスなど該当情報の意味を理解した情報を、市場分析から将来予測が可能なデータにしご提供することで、様々な分析が可能
▼お客様紹介
日経225を中心とした日本の大手企業が利用
パナソニック様、日立製作所様、味の素様、みずほ銀行様、帝人様、セブン銀行様、三菱商事様、サントリー様、JTB様、リクルートホールディングス様、リクルートキャリア様、ソフトバンク様
など
【関連資料】
▼【超オススメ】いま注目のAI!自然言語処理の実社会活用と未来構想 〜アカデミック、ベンチャーキャピタル、海外動向、スタートアップから見た実態〜
https://youtu.be/YzSa9aUTk8o
▼CEO林 インタビュー動画
https://youtu.be/nNAG1uByRbY
▼CTO有馬 インタビュー動画
https://youtu.be/yFsB0GfwaFU
▼Technology Fast50 2022 Japan
https://stockmark.co.jp/news/20230519
▼Stockmark オープン社内報(Youtube)
https://youtube.com/playlist?list=PLrZHMFQXt_asWdFjymZAIc1h6WrE4kKBa
▼coevo 当社運営のオウンドメディア
https://stockmark.co.jp/coevo
なぜやるのか
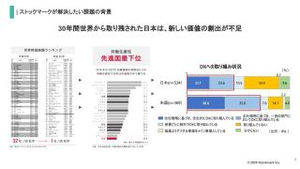
30年間世界から取り残された日本は、新しい価値の創出が不足
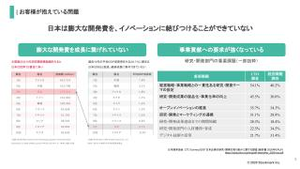
日本は膨大な開発費を、イノベーションに結びつけることができていない
イノベーションを生み出すための、「効率化」の課題は、様々なサービスがリリースされ、解くべき課題ではなく、やることが当たり前の社会となりました。
だからこそ、スタートアップの次なる課題は、「効率化」の先にある、イノベーションを生み出し、日本から競争力を生み出す最前線に立つことであると考えます。
どうやっているのか

左からCEO林、CTO有馬

社内の忘年会の様子です!
「カスタマーサクセスセントリックに意思決定をする自律分散型組織へ」
当社は、お客様のサクセスを中心に意思決定をすることを重視しています。
そうすることによって、現場でスピーディに意思決定が可能になり、より自律したチームとなっていくことができ、お客様から必要とされる提供価値を作り続けていくことができます。
また、カオスな状態でも、お客様を中心にできる方法を考え自律的に動くことができるからこそ、仕事を楽しく、自分ごとにしながら、高いパフォーマンスが出せるチームになっていきます。
こんなことやります
【現状の課題】
私たちが目指すのは、Web上のあらゆるビジネス情報を再整理し、ビジネスシーンでのデータ活用業務を自然言語処理AIで総置換することです。そのために、世界中のニュース、企業情報、論文、特許などをWebから収集、抽出、加工して顧客に提供し、企業の製品化・事業化を加速させられるような「オープンデータリサーチサービス」を開発しています。
しかし、顧客が「欲しい情報」を配信するための機械学習モデルやアルゴリズムの設計において以下のような複数の課題を抱えています。
・配信コンテンツ決定処理(text-preprocessing, deduplication, filtering, classification, etc)の精度の問題で、顧客が本当に欲しい記事を配信できずUXを下げている
・利用率向上に寄与しうるデータ拡充や精度向上施策を決めづらい
・機械学習にフォーカスするチームのリーダーが不在
【業務内容】
シニア機械学習エンジニアとして組織をリードすることを期待しています。
・機械学習や自然言語処理を用いた配信パイプラインの検証・実装・運用
・顧客フィードバックと利用データをもとに配信精度の課題を探索し、精度向上やデータ拡充の施策につなげる
・顧客に配信するニュース,論文,特許,レポートといった情報ソースの拡充戦略の策定と実行
※変更の範囲:開発関連業務
【チーム構成】
Opendata Unit
・バックエンドエンジニア2名
・機械学習エンジニア2名
・DRE 2名
<構造化/PaaS事業チーム(別チームだが随時協業)>
・機械学習エンジニア2名
・MLOpsエンジニア1名
【開発環境】
[開発言語]
データ/機械学習パイプライン: Python
Webクローラー: TypeScript(Node.js)
[コンテナ]
Docker
[IaC]
Terraform
[クラウド]
AWS
【ポジションの魅力】
・数億件規模の配信データを対象とした機械学習パイプラインの開発と運用を経験できる
・Customer SuccessチームやSalesチームとコミュニケーションしながら、顧客の定性課題を直に体感しつつ改善策の提案・実行を経験できる
・ResearchチームのNLPプロフェッショナルと協業しながら機械学習モジュールの検証と実装フェーズを経験できる
【必須スキル】※すべて必須
・理工系大学院を修了
・5年以上のエンジニア経験
・機械学習を用いたサービス開発/運用経験
・AWSを用いたサービス開発/運用経験
・開発チームのリード経験
【歓迎スキル】
・コンピュータサイエンスに関連する技術分野の修士号または博士号
・顧客向け自社開発サービスの開発/運用経験
・AWSを用いた機械学習実験, モデル管理, データ管理, 学習・推論パイプライン構築の経験
・Terraformを用いた開発/運用経験
・リーダーなどの立場で事業背景を理解し自ら施策を立案/実行した経験
【求める人物像】
・コンピュータサイエンスが好き
・最新の理論や事例をフォロー、検証するのが好き
・与えられた課題だけでなく、自ら問いを立て、そのために必要な解決策を生み出せる
・ビジネスサイドとコミュニケーションしながら、いかにプロダクトに貢献できるかを考えられる
・前向きなチャレンジ精神
<その他>
・入社後、必要に応じて東京オフィスへの出社が可能な方
・開発に関する技術的な内容含め、日本語で円滑にコミュニケーション可能な方
目安:日常会話レベル
最後に
当社は、独自の自然言語処理AIを活用した、AI SaaSで日本企業の成長を後押しすることを目指していスタートアップです。2022年8月にシリーズCで11億の資金調達完了。2024年2月には、経済産業省およびNEDOが推進する「GENIAC(Generative AI Accelerator Challenge)プロジェクト」に採択され、2024年5月に1000億パラメーターの自社LLMを公開いたしました!
従業員も100名を超え、更なる成長を目指すために人員を募集しております!
リモートワークなど働きやすさも大事にしています。お気軽に「話を聞いてみたい」よりエントリーしてください!
【関連資料】
・Opendata Unitのご紹介
https://stockmark.wraptas.site/48e328c4d33a480f837a6509f575db8f
0人がこの募集を応援しています
メンバーの性格タイプ


会社の注目のストーリー
ストックマーク株式会社の他の募集
- デザインマネージャー
デザインMgr募集|生成AI✕SaaS 戦略立案から組織マネジメントまで
- デザインマネージャー
デザインMgr|生成AI✕SaaS 戦略立案から組織マネジメントまで
- ソフトウェアエンジニア
ソフトウェアエンジニア/リードエンジニア|チーム開発でフルスタックに成長可
話を聞きに行くステップ
- 応募する「話を聞きに行きたい」から応募
- 会社からの返信を待つ
- 話す日程を決める
- 話を聞きに行く
募集の特徴
オンライン面談OK
会社情報
2016/11に設立
81人のメンバー
- 1億円以上の資金を調達済み/
- 3000万円以上の資金を調達済み/
東京都港区南青山一丁目12番3号 LIFORK MINAMI AOYAMA S209