 rinoguchi.net
rinoguchi.net rinoguchi.net
rinoguchi.net rinoguchi.net
rinoguchi.net lab.astamuse.co.jp
lab.astamuse.co.jp lab.astamuse.co.jp
lab.astamuse.co.jp lab.astamuse.co.jp
lab.astamuse.co.jp m3tech.blog
m3tech.blog m3tech.blog
m3tech.blog
アスタミューゼ株式会社 / 開発インフラ部
PythonからDataprocを操作してシームレスに並列処理を実現する - astamuse Lab
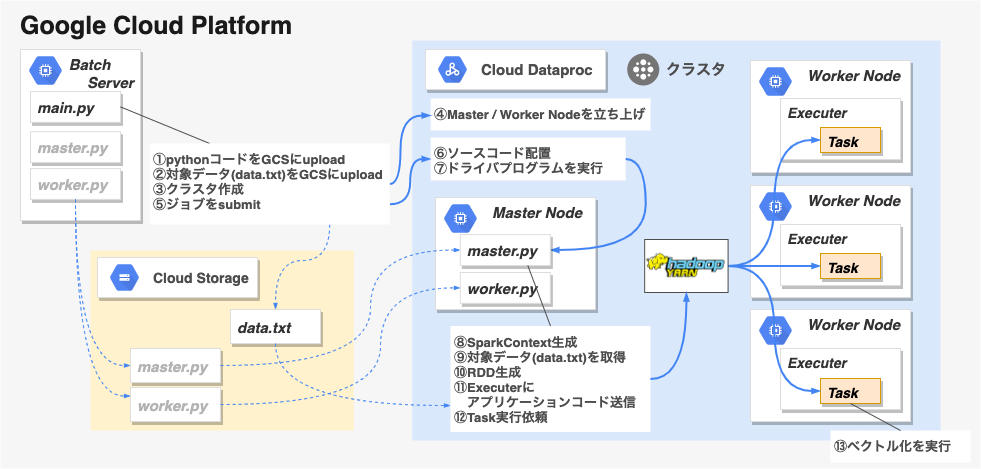
私は当社で、特許データなどの名寄せ(同一人物に対してユニークなIDをふる作業)を担当しております。 特許の名寄せには、人物名・組織名・出願日・共同出願人など様々な特徴を利用するのですが、中国人名などでは同姓同名が起こりやすく、同じ名前で数万件の特許が出願されるケースもあるため、別人を判別する処理(名分け)が重要です。その根拠の一つとして特許の類似性を導入することにしたのですが、特許文書をベクトル化に尋常じゃなく時間がかかるため、処理を並列化することにしました。 分散処理用のクラスタを準備・管理していくのがハードルが高いので、フルマネージドな分散コンピューティングサービスであるDataprocを利用することにしたのですが、Dataprocであっても普通にコンソールやCLIから利用すると、手作業やbashスクリプトが登場してしまいます。 巨大な名寄せアプリケーションは全てPythonで実装され、一連の処理は自動化されていて、特許文書のベクトル化というごく一部の処理のために世界観を崩したくありません。なので、PythonからDataprocを操作してクラスタを構築しPythonのアプリケーションを送り込んでジョブを実行する形にすることで、他のプログラムと同様に全てをPythonコードでコントロールするように工夫しました。