/assets/images/1428645/original/71f8d811-b394-4a4c-a1f7-dd4d764843dd?1577065089)





株式会社Ridge-iでは一緒に働く仲間を募集しています
こんにちは、Ridge-i(リッジアイ)の採用担当です。
リッジアイでは、【Ridge-i University ~Adviser Session~】を開催しております!
今回は牛久先生の特別講義の様子をお届けしていきたいと思います!
Ridge-i Universityとは
リッジアイで週に1回程度開催される、共同研究や技術顧問をして頂いている先生方からRidge-iの社員へ様々な知見をご共有いただく勉強会です。
講演者紹介
CRO 牛久 祥孝(Yoshitaka Ushiku)
画像を人の言葉で説明する画像キャプション生成技術によって博士号を取得した後、NTTコミュニケーション科学基礎研究所でメディア認識の研究に従事。 東京大学 情報理工学系研究科に講師として着任し、学部生から大学院生までの講義を受け持ちつつ、研究室でも画像処理と自然言語処理の融合領域を中心とした研究指導にあたる。
今回のテーマは、性質が異なるデータ間でも、モデルの精度を落とさないための手法
「Domain Adaptation」についてです!
研究が盛んなUnsupervised Domain Adaptationについて講義して頂きました。
ここでは、Source Domainにはラベルが付与されており学習することができるが、Target Domainにはラベルが付与されていないという問題設定を考えます。
AIの開発現場に置き換えると、Target Domainがクライアント環境で取れるデータだがラベルが付与されていないデータセットであるという設定に近いと思われます。
上記のような設定の中で、Target Domainで動くような機械学習手法を作るのがDomain Adaptationと呼ばれます。
今回は2つのアプローチについてご紹介頂きました。
Asymmetric for Tri-training for Domain Adaptation
ここではMNISTがSource Domain、SVHMがTarget Domainと考えます。
MNISTで学習したモデルを使ってSVHMを推論します。データセットのドメインが異なるため正確な推論をすることは難しいですが、その中でも一部のデータについては自信をもって推論できるデータが存在します。自信をもって推論した結果には擬似ラベル(pseudo label)を付与します。
次のステップでは、Target Domainの中で擬似ラベルが付与されたデータをSource DomainであるMNISTに混ぜて学習します。
上記を繰り返し行うと、Target Domainのラベルがついていないという問題を解消しながらTarget Domainでも動くようなモデルを作成することができます。
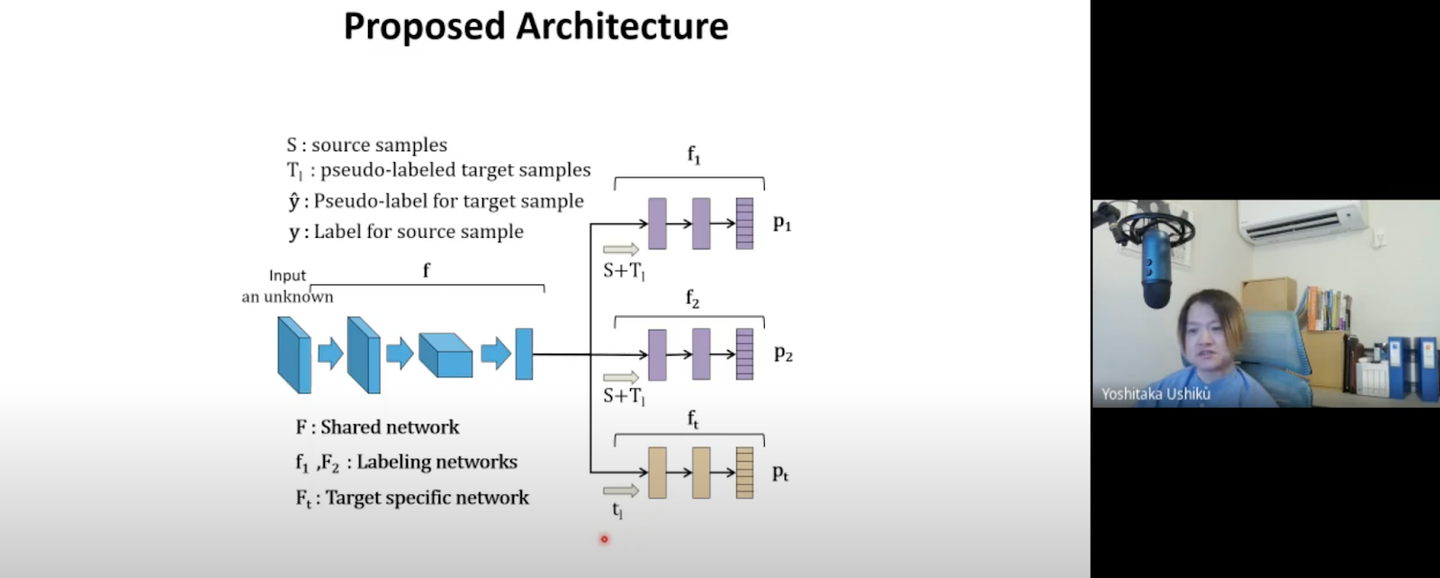
アーキテクチャについても詳細に解説頂きました。
左半分の青いネットワークは特徴を抽出するモジュールで、右半分に3つのClassifierが存在しています。
Soruce DomainのラベルとTarget Domainの擬似ラベルが付与されたデータは紫のClassiferネットワークを通ります。茶色のネットワークはTarget Domainの擬似ラベルが付与されたデータのみが通ります。
最初はSoruce Domainのデータのみで学習し、Target Domainのデータで推論させた際に紫の2つのネットワークの結果が近しく一定以上の確率であれば擬似ラベルを付与するといった流れでTarget Domainにラベルを付与していきます。
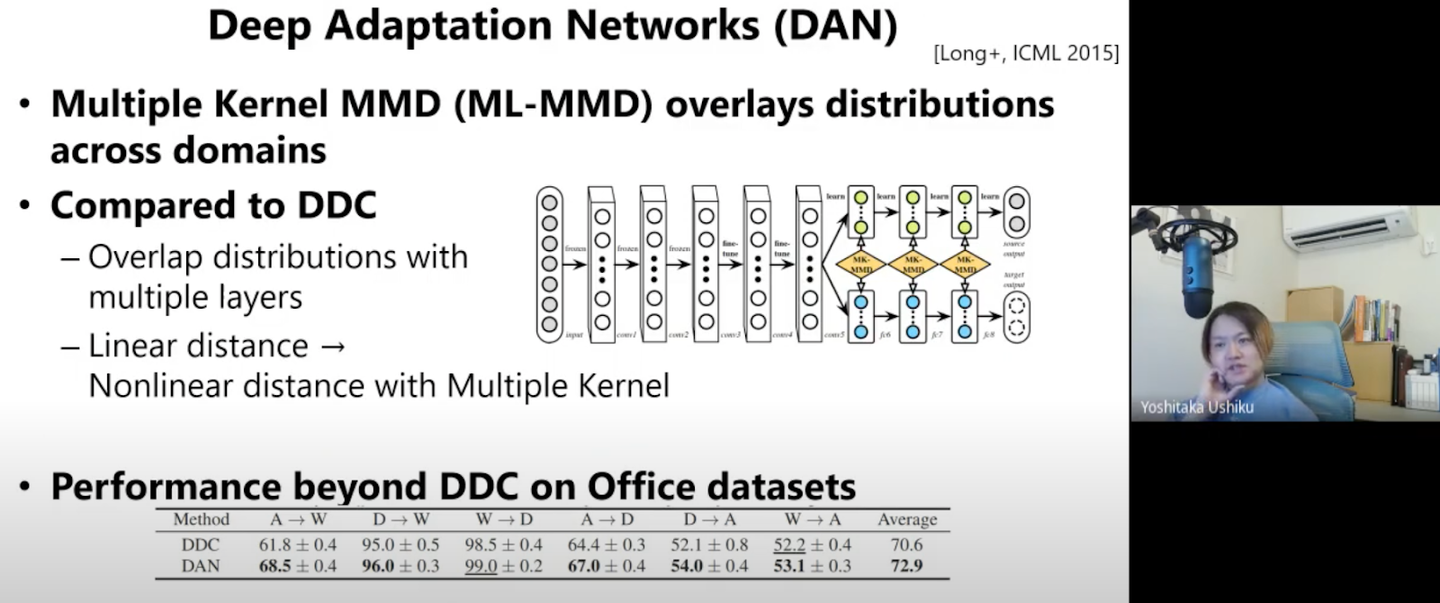
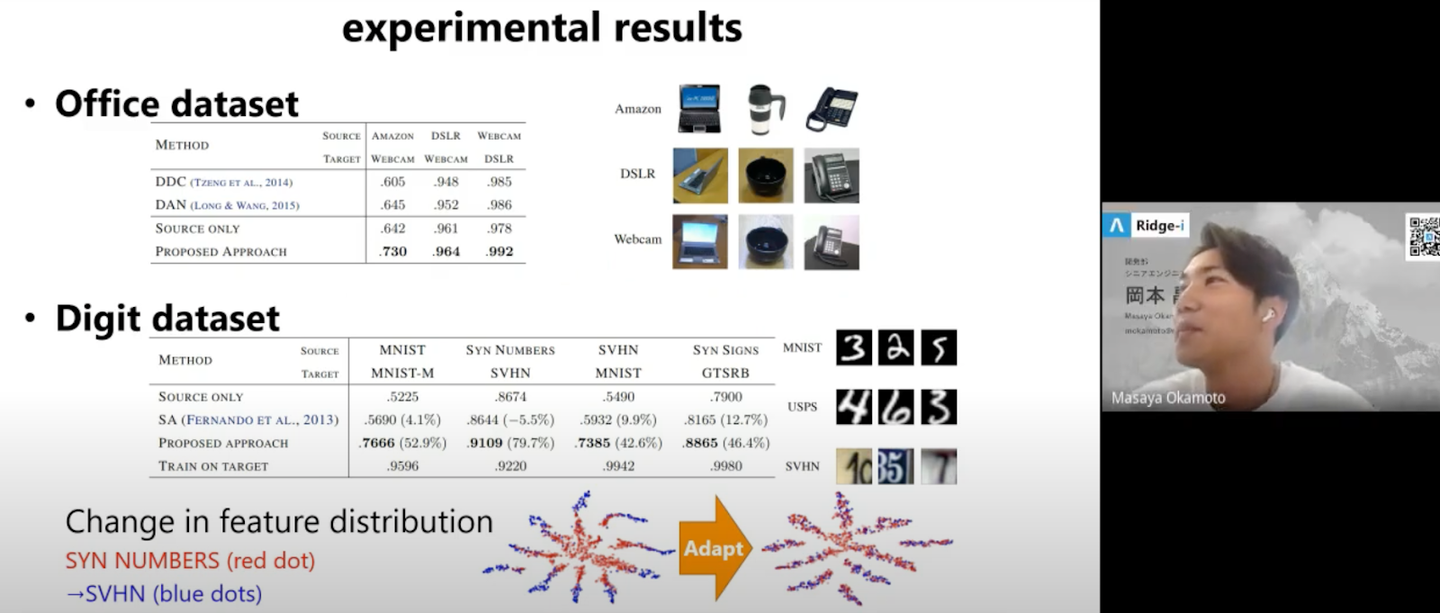
本アプローチはこれまでのDomain Adaptationの手法より精度が良くなっていることがわかります。
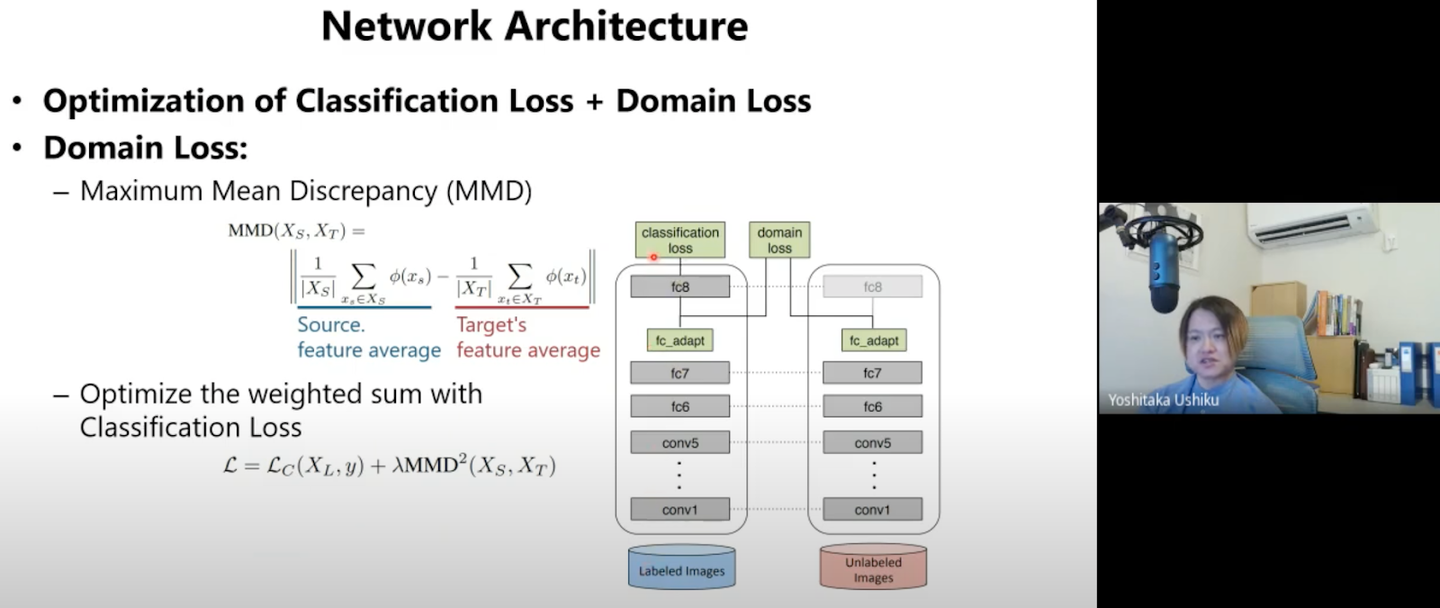
上記のような疑似ラベルを使った手法の他に、生成モデルを使った「Deep Domain Confusion (DDC)」や「Deep Adaption Networks (DAN)」についても紹介頂きました。
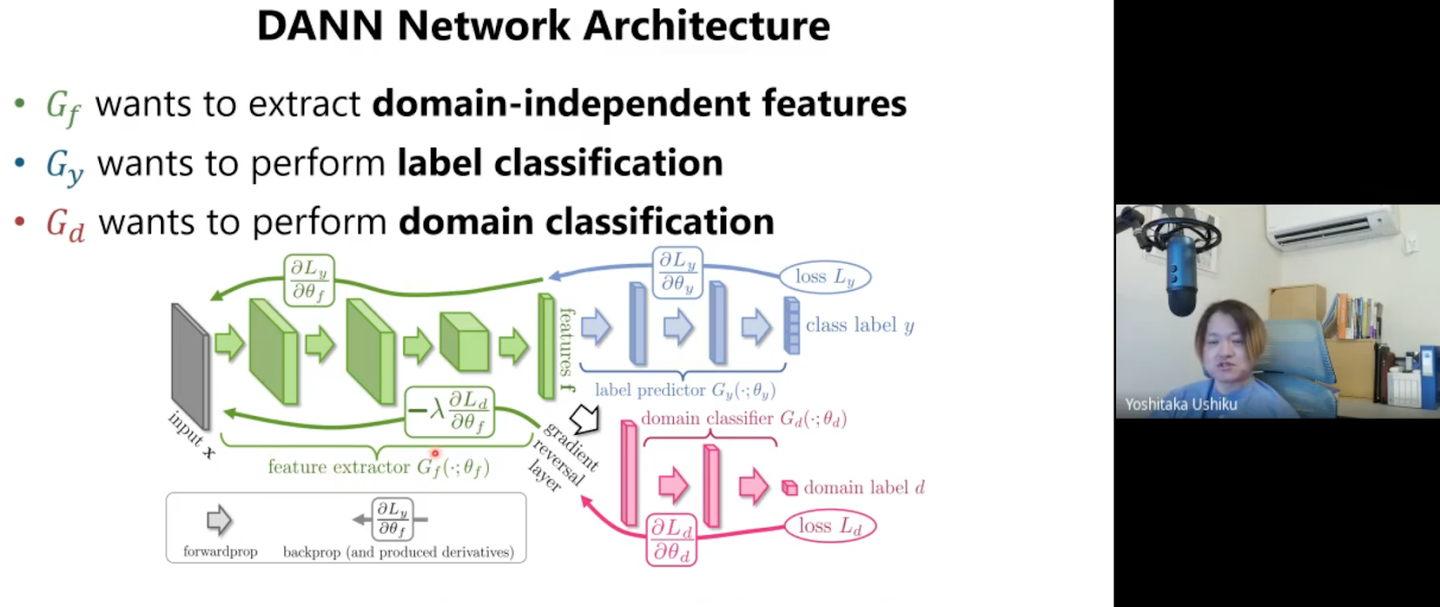
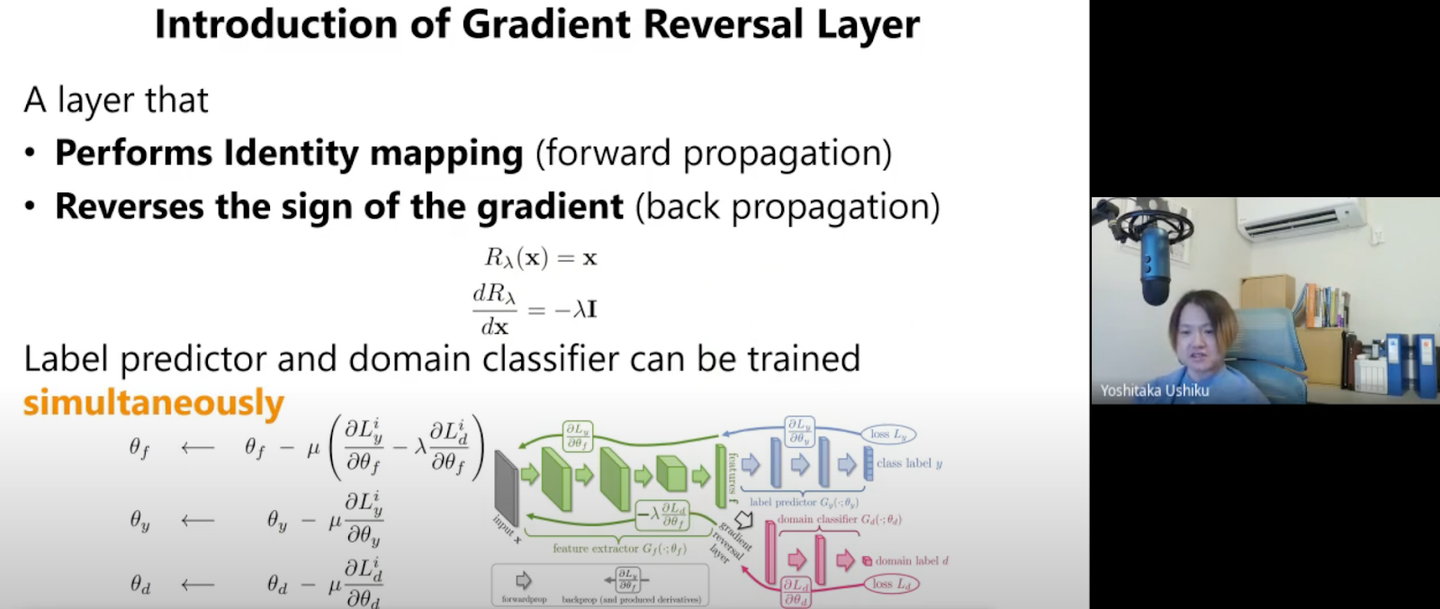
Domain Adversarial Neural Networks (DANN)
こちらはGANに近い考え方をもっており、敵対的学習をすることで異なるドメインにまたがって一貫した情報を持つ特徴量を学習しています。
緑のモジュールは特徴量抽出器で、ここでは入力されるデータが同じクラスならSoruceでもTargetでも同じようなクラスタになる特徴量を抽出するのが目的です。
青のモジュールはClassifierで、赤のモジュールは入力されたデータがSource Domainなのか、Target Domainなのかを見破るモジュールになっています。
赤のモジュールはDomainの差を見破りたいため,Lossを最小化させたいですが、緑のモジュールはDomainによる差を無くしたいためLossを大きくしたいという目的を持っています。(GANとの違いは同じネットワークの中で逆の目的を持ったモジュールが存在していること)
ここで登場するのが、順方向の時は何もせず、逆伝搬の時は勾配の符号を逆にする「Gradient Reversal Layer」です。これにより敵対的な学習を可能にしています。
講義後はエンジニアだけでなく弊社コンサルタントからも質問があり、実際のプロジェクトへ使う際に意識することなどについても教えて頂きました。
最後に
最後までお読みいただきありがとうございます。
Ridge-iは、社会人になった今も学び続けられる素敵な環境です。
もしこのような取り組みに興味がありましたら、是非カジュアル面談にお越しください!
カジュアル面談はこちらから
関連リンク
- Ridge-i 採用HP
- エンジニアブログ・採用ブログ・社員紹介等を掲載しています。
- Ridge-i コーポレートサイト
- リッジアイの会社情報・ニュース・サービス等をぜひご覧ください。
/assets/images/1428645/original/71f8d811-b394-4a4c-a1f7-dd4d764843dd?1577065089)
株式会社Ridge-iからお誘い
この話題に共感したら、メンバーと話してみませんか?
Ridge-i University 牛久先生による特別講義第1回をレポート
/assets/images/1428645/original/71f8d811-b394-4a4c-a1f7-dd4d764843dd?1577065089)