

/assets/images/1826326/original/aa3f83b5-3ead-4d9c-8e34-b20a69a21c38?1506902665)
株式会社Studio Ousiaでは一緒に働く仲間を募集しています
カリフォルニアのロングビーチで行われた人工知能やニューラルネットに関する世界最高峰の国際会議の一つであるNIPS 2017で、弊社の開発した早押しクイズAIとクイズのエキスパート6人で構成される人間のチームの対戦が行われ、弊社のAIが人間のチームに二倍以上のスコアの差(465対200)をつけて勝利しました!
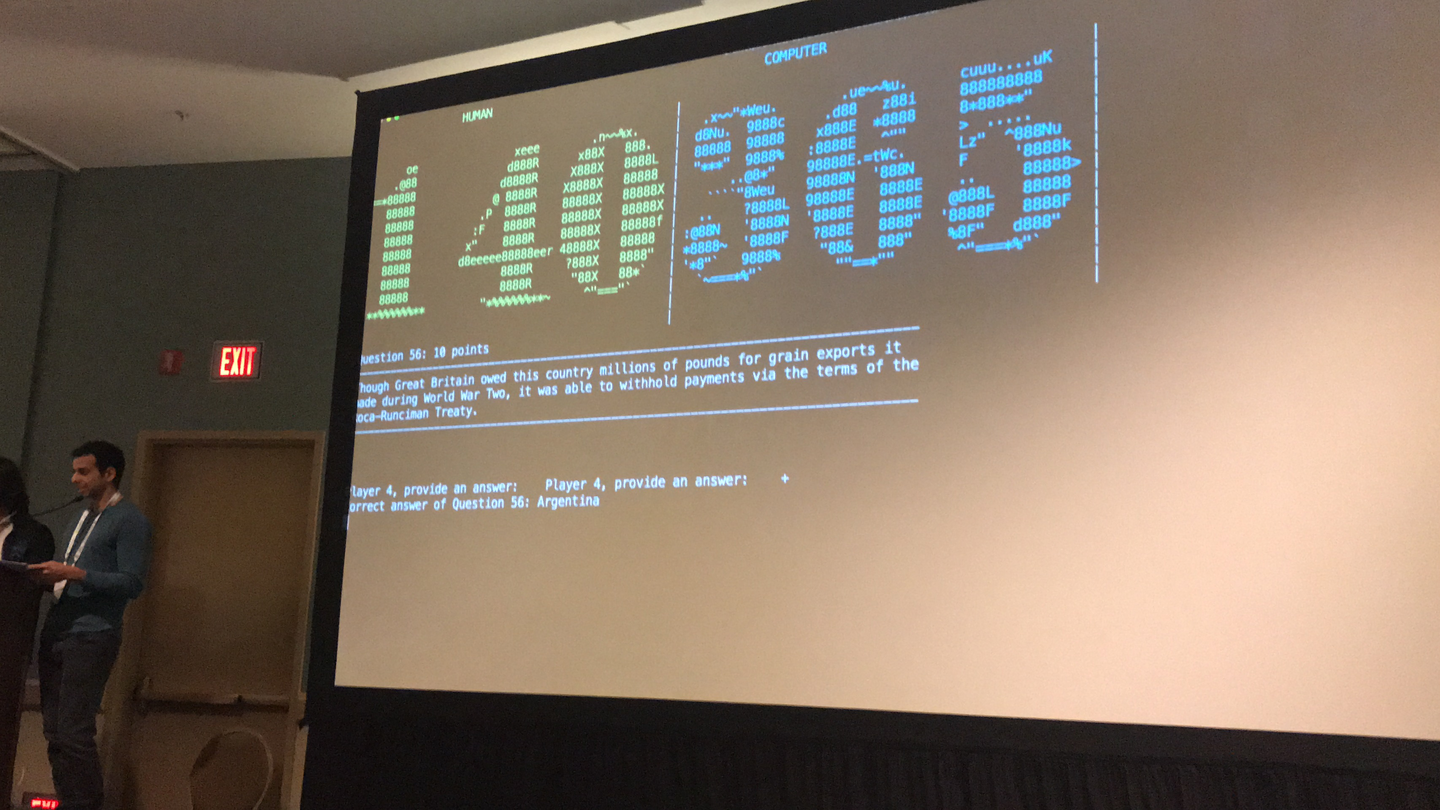
この対戦は、NIPSのコンペティショントラックの一つとして開催されている「Human-Computer Question Answering Competition」の中で行われました。 このコンペティションでは、参加者はクイズボウルと呼ばれる、クイズ対戦ゲームを解くAIを開発することを求められます。 そして、提出したAIは、他の提出されたAIとの対戦をして性能を評価され、このAI同士の対戦で勝利したAIが最終的に人間のチームと対戦するということになっています。 今回の人間のチームは、クイズ番組「ジェパディ!」の優勝者で、テレビ番組「Who Wants to be a Millionaire)」で過去に25万ドル獲得したことのあるRaj Dhuwalia氏や、数学者で、過去にいくつかの米国のクイズコンペティションで優勝した経験を持つDavid Farris氏などの有力なクイズプレーヤーを含む六名で構成されています。 このコンペティションは、2016年に開催された第一回に続いて二度目の開催で、前回と同様にメリーランド大学、スタンフォード大学、Allen Institute for AI等に所属する該当分野で著名な研究者がオーガナイズしています。 弊社は、このコンペティションの第一回目にも出場し、AI間の対戦では優勝したのですが、人間チームとの対局では155対190で負けてしまったため、今年のコンペティションに再度挑戦することになりました。
クイズボウルは日本では馴染みが少ないですが、英語圏を中心に幅広く人気があります。 例えば、AIブームのきっかけとなったと言われる、クイズ番組「ジェパディ!」でのIBM Watsonと人間の対戦で、IBM Watsonに敗れたクイズ王Ken Jenningsは、クイズボウルでも活動していたことが知られています。 また、年間を通じてクイズボウルのトーナメントが開催されています。 そして最近では、質問の意味を解析する自然言語処理の手法を評価する方法として、研究でも良く使われています(*1)。
クイズボウルの特徴の一つは、早押しで回答する必要がある点です。 質問文は、早い段階で答えるのは難しく、読み上げられていく毎に簡単に回答できるように書かれていて、質問の早い段階で正解した場合は15ポイント、そうでない場合は10ポイントがもらえるルールになっています。 このため、質問文のなるべく早い段階で回答することが重要になってきます。 また、一度間違えると同じプレーヤーは再度回答することが出来ないため、回答の精度を維持することも重要です(*2)。 例えば、下記の質問文の回答は「豊臣秀吉」ですが、回答について知っていたとしても、質問文の早い段階で回答するのは、難易度が高いことがお分かりいただけると思います。
今回のシステムでは、二つのディープラーニングのモデルと、複数の情報検索モデルから出力された複数の特徴を、アンサンブル学習 (gradient boosted regression trees (GBRT)) を用いて組み合わせる(*3)ことで、高精度化を実現しました。 また、中核となっているディープラーニングのモデルとしては、質問文に対して回答を予測する分類モデルを用いました。 具体的には、Deep Averaging Networksという比較的シンプルなディープラーニングのモデルに対して、質問文中に出現した単語とWikipediaエンティティ(固有名詞や専門用語など)を入力することで、質問の意味のモデルを構成し、回答を予測しています。 このモデルの新しい点としては、(1) 単語だけでなく、曖昧性の無いWikipediaエンティティも合わせてモデルに入力していること、(2) 単語とエンティティのベクトルを、弊社が昨年に提案した新しい分散表現モデル(*4)を使って初期化していることがあげられます。
今回のシステムは、弊社で開発している質問応答システムであるQA ENGINEの製品の開発の過程で得られたノウハウを元に開発されました。 開発には、Python、Cython(高速化)、PyTorch(ニューラルネット)、LightGBM(GBRT)、Hyperopt(ハイパーパラメータ探索)などのライブラリを用いました。 また、来年には、このNIPSコンペティションでの成果をまとめて書籍が出版されることになっており、そちらでさらに詳細なアプローチを解説する予定です。
(*1)例: A Neural Network for Factoid Question Answering over Paragraphs (Iyyer et al., 2014) や Deep Unordered Composition Rivals Syntactic Methods for Text Classification (Iyyer et al., 2015)、Opponent Modeling in Deep Reinforcement Learning (He et al., 2016) など
(*2)今回の場合、人間チームは6人いるので最大で6回の回答ができるのに対し、AIは一回間違えたら再回答できません。
(*3)ディープラーニングの出力をアンサンブル学習に特徴として組み込む際にはstackingを用いています。
(*4)Joint Learning of the Embedding of Words and Entities for Named Entity Disambiguation(Yamada et al., 2016)
開発した早押しクイズAIが人間のチームと対戦して勝利しました @ NIPS 2017

