こんにちは。クラシコムデータ分析チームの高尾です。
この記事は、クラシコムが抱えていた課題と、それをどう解決しようとしているかを記録するために書きました。想定読者はデータ基盤、データ分析チームをマネジメントしている人や、データ基盤を安定運用するために実装をする人を考えています。
目次
- サマリー
- 前提条件
- クラシコムのデータ分析チームの構成
- データ基盤は「動いているが課題を抱えている」状態だった
- あくまでも強調しておきたいこと
- 施策内容
- アドバイザリー風音屋さんからのアセスメント
- DataVault2.0で中間層をつくる方針を立てた
- DataVault 2.0のメリデメを整理
- primeNumberさんと共同プロジェクトの開始
- プロジェクトについて
- このプロジェクトを進める上で高尾が感じたこと
- dbt連携機能の使い倒しに方針を変更
サマリー
この記事のサマリーは以下の通りです。
クラシコムではデータ基盤の安定化の必要性を認識するに至り、Data Vault 2.0で中間層を作る構想を立て、その実現のためにdbtを使おうとしました。その際、利用中だったtroccoで、dbtの機能が実装されるタイミングと重なり、1st userとしてtroccoのdbt連携機能を利用させてもらいました。troccoのdbt連携機能を一通り触った感触として、Data Vault 2.0にこだわらず、まずはLooker上で持たせているETLの機能をtroccoのdbt連携機能に移行するのがよさそう、と考えるに至りました。
前提条件
クラシコムのデータ分析チームの構成
チームの人員はクラシコムの社内外にこだわらずプロ人材から構成されています。チーム運営のコンサルティングは株式会社風音屋、ビジネスサイドは社内スタッフ、データアナリストは副業採用の社員、開発は面白法人カヤックと社内エンジニアが担当し運営しています。
データ基盤は「動いているが課題を抱えている」状態だった
本施策の経緯はこの記事に記載のとおりです。
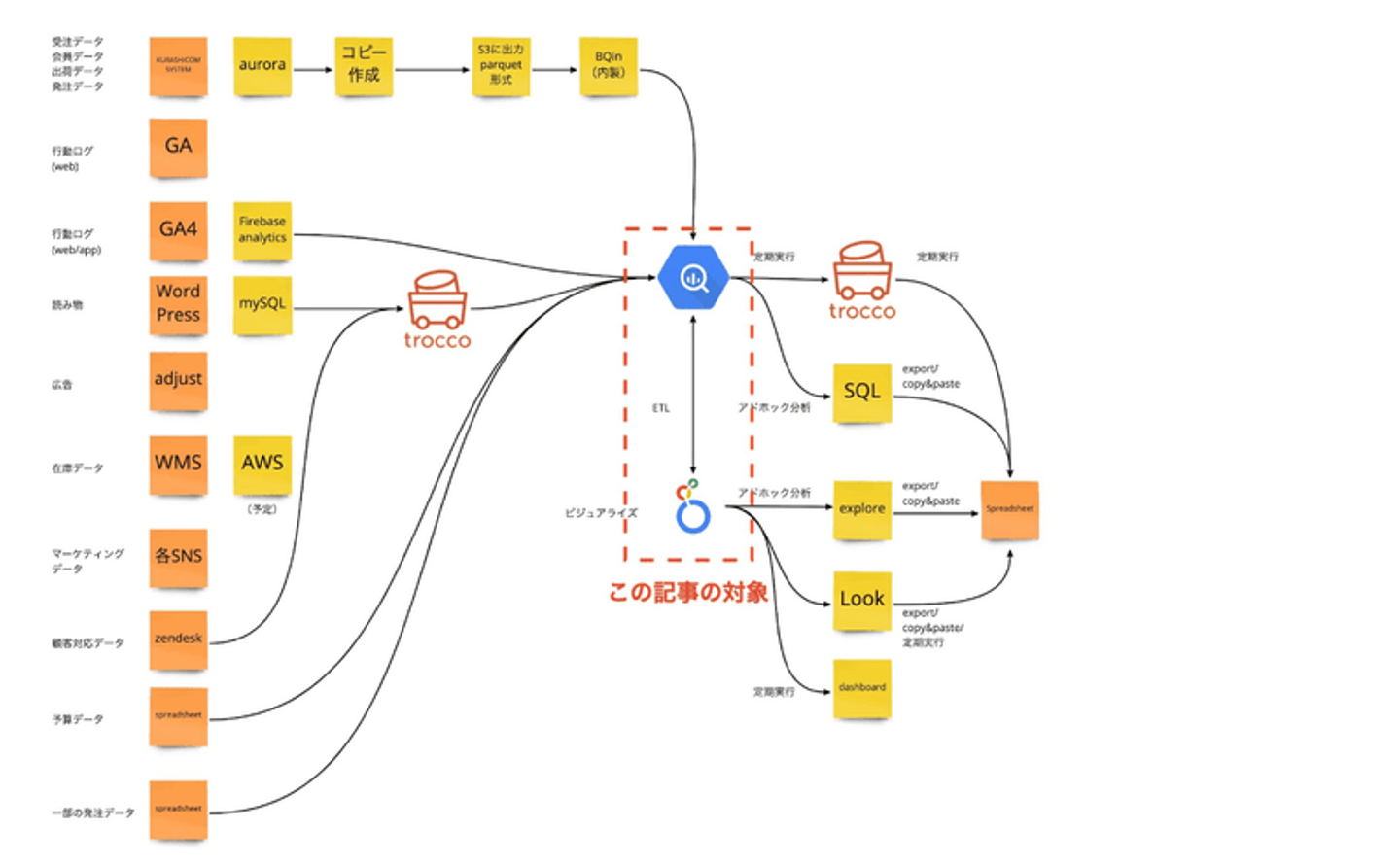
上記の記事の未来像にちょっとだけ近づいていて、いまのフローは下記のとおりです。
![]()
「北欧、暮らしの道具店」データ分析フロー
このフローの中でも、今回取り上げるのは、赤線で囲んだ、LookerにETL機能をもたせてデータマート生成をしている部分です。
Looker導入時(2020年夏頃)は、BigQueryとLookerという最小の構成だったので、保有しているツールでできることをやっており、ビジネスサイドの要求に応えるだけの十分な分析ができていたことが、この構成を採用した理由です。
一方で、ちょっとずつ、「ひずみ」が生じつつあったのも事実です。
複数のデータマートを参照して生成されるデータマートについては、データ連携のタイミングがずれた場合に、正常にマートが生成されないことがありました。
また、一部のデータマートについては、設計者以外のエンジニアが修正を加えようとした場合に、構造が一見して把握しずらく、設計者の手が空くのを待っていたほうが、別の人が構造を把握して修正するよりも早い、という状況が発生していました。
あくまでも強調しておきたいこと
この件に限らず、僕が業務やシステムを改善するときに考えていることを、ここでも共有させてください。
それは、「今の状態は過去にベストを尽くしてきた積み上げで作られてきている」と考えており、そのため「改善は過去の否定ではない。過去を肯定した上で、よりよい未来を作るためにアクションする」ということです。
そのため、あくまで、本件も「なんでそんなETL環境にしちゃったんだ!」という気持ちは全く無くて(意思決定したのは僕ですし)、「より良いものに変えていきましょう」という気持ちで実施しています。
施策内容
アドバイザリー風音屋さんからのアセスメント
さて、この状況を、クラシコムのアドバイザリーをしてくださっている風音屋さん(データエンジニアリングの書籍を書いている@yuzutas0さんが立ち上げた会社)にみてもらって、次のようなコメントを得て、課題が明確になりました。
・Lookerのディレクトリ構成が複雑(二階層)・Lookerで複雑な集計処理を組み合わせている・Lookerで生成したカラムと、データソースで生成したカラムが混在しており、判別できない(例:idカラム)・データソースの不備を補っている(例:履歴データの取り扱い)・リファクタリングが追いついていない
DataVault2.0で中間層をつくる方針を立てた
この状況に対して、面白法人カヤック池田さんからも起案があって、Lookerからtroccoに複雑な集計処理を切り出して、Data Vault 2.0によって中間層を整理する方針を立てました。
DataVault 2.0のメリデメを整理
Data Vault 2.0を選択するにあたってはスタースキーマやスノーフレークスキーマをはじめとして、いくつかの選択肢を検討しました。
最終的には、データ整備の方法について定義しており、複数のデータソースから入ってきたデータを統合するための手順を定義している、などの特徴をもつ、Data Vault 2.0を採用しました。
とはいえ、Data Vault 2.0にはいくつか懸念点があり、そのなかでも学習コストの高さを不安視していました。ルールが明確になる一方でそのルールを学ぶ必要が生じます。現在の分析チームの規模でその学習コストを払うべきか議論になりました。
結論としては「他の選択肢でも学習は必要になる」「学習コストを下げることはできる」と考えました。
学習コストの高さは「日本語の資料がないこと」「原著のボリュームが多いこと」に起因しています。『30分でわかるData Valut 2.0』というコンテンツを用意すれば、学習コストは削減できるはず、と考えて、開発者には、開発着手の前にドキュメンテーションの時間を確保してもらうようお願いし、しっかりとしたドキュメントを作成してもらいました。
primeNumberさんと共同プロジェクトの開始
さて、そんな中、DataVault2.0の実現のためには、dbtの機能があったほうが効率的である、ということがわかってきました。
一方で、セキュリティやコストの観点からも、データ転送のツールをどんどんと増やすのにも抵抗がある・・・と考えていた矢先、primeNumberさんがtroccoにdbtの連携機能を実装を予定されている、ということがわかりました。
タイミングがばっちり合った、という縁もあり、primeNumberさんとクラシコムの共同プロジェクトとして、クラシコムがtroccoのdbt連携機能のトライアルユーザーとして機能を使わせてもらえることになりました。
プロジェクトについて
構成員ビジネスサイド:クラシコム(高尾)サービス提供者:primeNumberさん開発者:カヤック池田さんファシリテーター:風音屋さん
クラシコムがユーザーとしてtroccoのdbt連携機能を使う、という立場で、開発者としてあったらうれしい機能(buildの機能などが要望として出されました)をカヤック池田さんがリクエストし、primeNumberさん側の事情をもとに優先度や要否を検討いただき、出来上がった環境で、クラシコムが開発を行う。この全体をファシリテートしてくれたのが、クラシコムのアドバイザリーの風音屋さんという立て付けです。
プロジェクトでは、クラシコムで最も参照頻度の高いデータマートの生成部分を、troccoのdbt連携機能上へ移行する、ということをターゲットとしました。
2ヶ月間のプロジェクトを通して、クラシコムはトライアルユーザーとしての役目を果たしつつtroccoのdbt連携機能によってDataVault 2.0でのETL機能移行を実現することができました。
このプロジェクトを進める上で高尾が感じたこと
ビジネスサイド、かつ、クラシコムのデータ基盤とデータ分析チームをマネジメントする立場として、段々と技術的な詳細への理解が追いつかなくなってくる中で、僕が果たすべき役割はゴールイメージの明確化、やることやらないことの整理、初手の設定、スケジュールの管理だと考えており、その部分にコミットしていました。
また、複数社のエンジニアが会話する様子は、すごく興味深くprimeNumberさんとカヤックさんのやりとりをみれる定例はめちゃくちゃ勉強になりました。
というのも、ビジネスサイドが要望をだして、エンジニアがそれに応える、というシーンは多くの経験があるのですが、エンジニアが要望を出して、エンジニアが応える、というシーンは、あまり目にする機会がなかったのです。これによって、お互いの開発の背景が解像度高くわかっている人同士が会話するとどういうやり取りになるのかを知ることができました。
たとえば・・・
それは初期リリースには必要、あるいは必要ない、という整理の仕方や、〇〇な機能が必須と考える理由、の池田さんの説明がうまかった。とあるエラーが発生したときの調査の仕方、クローズのさせ方、どこを妥協しないか、という点が興味深かったです。
そのため、マネジメントだから技術の詳細わからない・・・なんて言ってるともったいないことになるな、と気を引き締めるいい機会にもなりました。
dbt連携機能の使い倒しに方針を変更
実際に、Data Vault 2.0によって中間層を作りながら、troccoのdbt連携機能上でETL機能の実装を行ってみて、方針を転換するほうがよいのでは?という議論になりました。
「データ基盤の安定化」というゴールに対して、中間層の生成は、構造を整理することで近づくアプローチです。一方、dbtを利用することで、依存関係の整理やデータ欠損の防止を実現することができます。
実装を担当したカヤック池田さんからは「troccoのdbt連携機能の使い心地がよいこと、Data Vault 2.0の設計を構想しながらdbt上に移行するよりは、一度dbt上に移行をすべて行ってしまって、その後構造を考えたほうが効率がいいのではないかと考えた」という起案がありました。
Data Vault 2.0は一回保留し、troccoのdbt連携機能への移行をやりきることに決めました。
いまみているゴールイメージはこんな感じです。
・Lookerはdimensionとmeasureを記述するだけの場所として使う
・Looker上でPDTを使っている部分を、troccoのdbt連携機能に乗せ換えるだけでも、依存関係の整理やデータの欠損の防止が可能になる、と期待しています。
・troccoのdbt連携機能への移行ができた後、そのときの状態に応じてData Vault 2.0で構造を整理するかを検討しよう、と考えています。
株式会社クラシコムでは一緒に働く仲間を募集しています
/assets/images/8987032/original/ddeeb212-469f-4efc-9ee4-c5b04a64e96d?1646380372)



/assets/images/8987032/original/ddeeb212-469f-4efc-9ee4-c5b04a64e96d?1646380372)
/assets/images/8962265/original/c7866d47-17e7-4032-8d3d-04275630324d?1646121547)
