こんにちは。エンジニアの佐々木です。
先日12/6、弊社イベントにてカヤックの藤原さんを交えてクラシコムのSREについてお話をさせていただきました。
当日は96名と多くの方にお申し込みいただきありがとうございました。1時間半があっという間で、時間の関係でお話できなかったことも多々ありました。改めてではありますが、記事にて当日の内容含め話せなかったこともご紹介したいと思います。
当日のテーマは「インフラ強化に向けた具体的な取り組み」と「一人に頼らないチーム体制づくりを目指して」という2つでした。
この記事では前半の「インフラ強化に向けた具体的な取り組み」について紹介します。北欧、暮らしの道具店のインフラ構成の変遷を追いつつ、その時々の課題や実際の取組みについて説明していきます。
目次
- 5年前(2017年5月頃)のインフラ構成
- 3年前(2019年9月頃)のインフラ構成
- 今(2022年11月頃)のインフラ構成
- まとめ
5年前(2017年5月頃)のインフラ構成
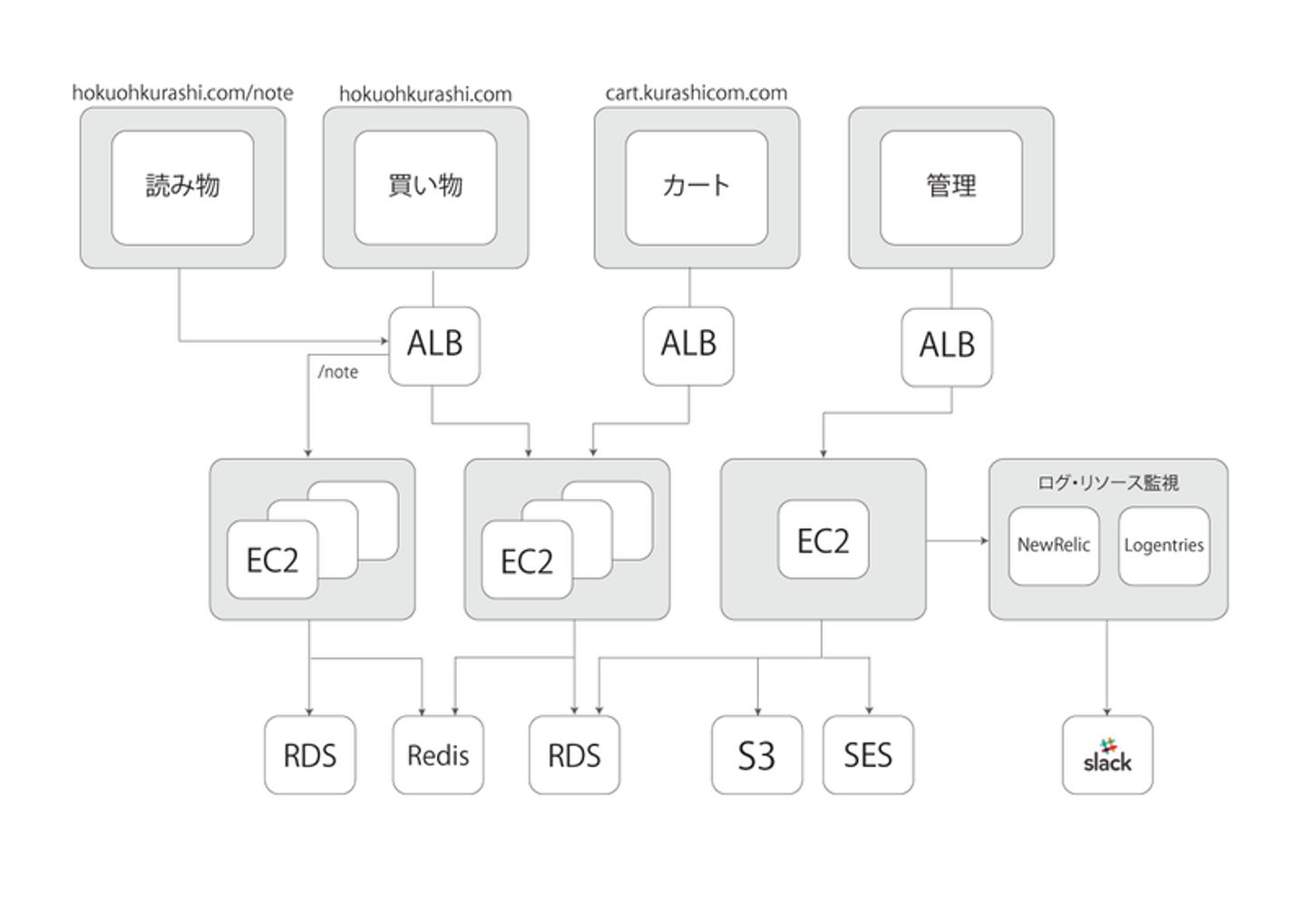
![]()
エンジニア3人で作った月間1600万PVのECサイト
「北欧、暮らしの道具店」を支えるシステムの裏側 より
いきなりイベント中に触れなかった内容ではありますが、これはクラシコム内でSREの活動が始まるずっと前に書かれた記事にある構成図です。
私が入社直後の構成でもありますが、当時インフラ面で以下のような課題感がありました。
- サーバー監視に改善の余地がある
- 大事にならないと把握できない潜在的な問題があるかもしれない
当初、NewRelicとLogentriesは監視するために導入されていました。
しかし、NewRelicはメトリクスの取得のみしていて通知の設定が不十分。
Logentriesは、特定の文字列が入ったログが出力されたらSlackに通知されるという設定がされていましたが、ログだけでは情報が少なすぎて、それが不具合を抱えているのかどうかも把握するのが難しい状態。
こういった経験から、すでにお客様から信頼してもらえている自社サービスを安定的に成長させるためには、まずは以下の部分で改善が必須だと考えていました。
- 監視の改善
- 可観測性の向上
- 小規模チームで裏側も改善していける体制づくり
すぐNewRelicでアラートを設定するなど少しだけ改善。その後、他プロジェクト優先で2年ほど月日が経ち、ある日代表の青木からカヤックさんのエンジニアと一緒に仕事をするのはどうかという打診があり、SRE伴走支援が始まります。
3年前(2019年9月頃)のインフラ構成
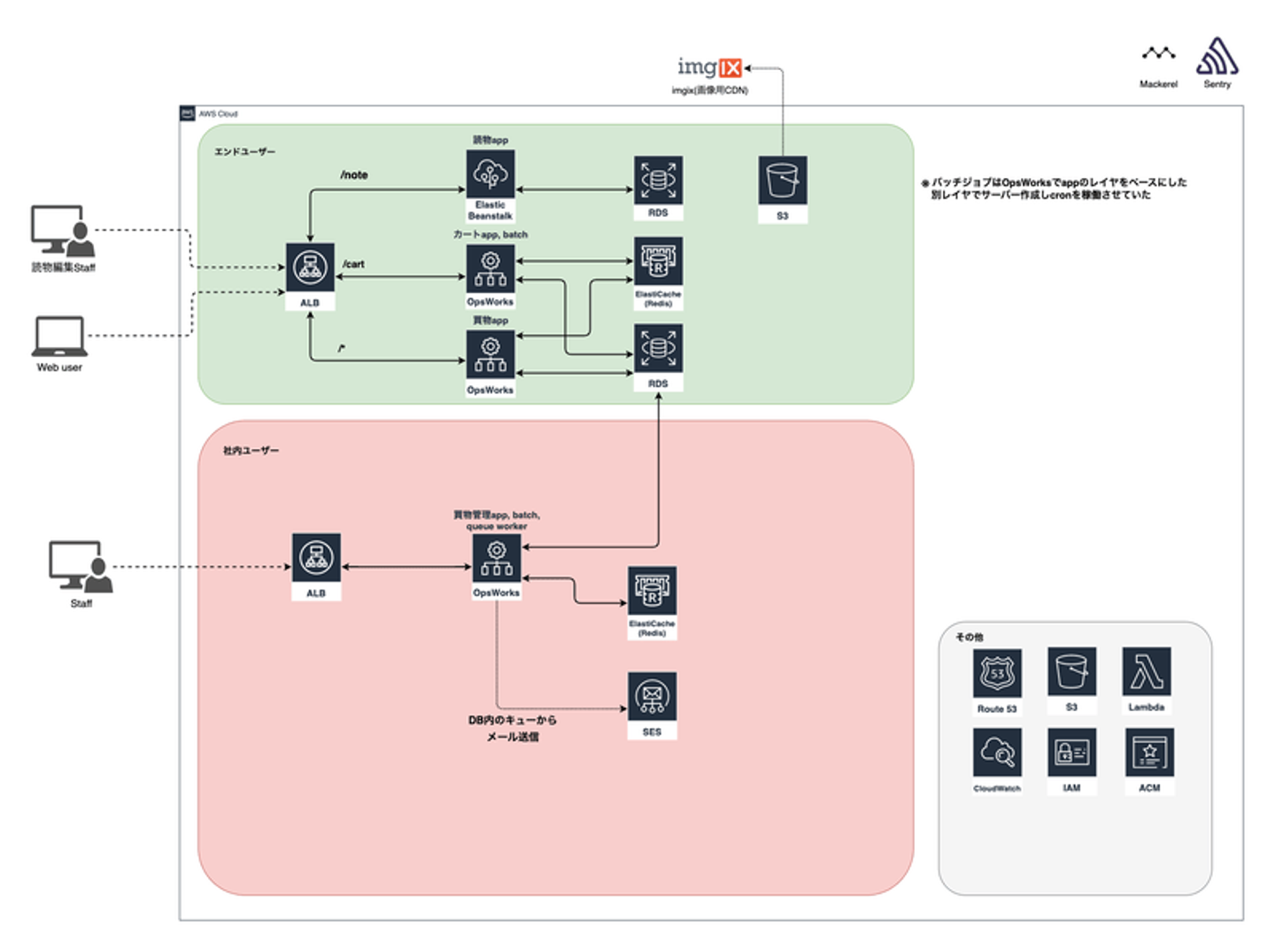
![]()
当時の構成図
これはカヤックさんと一緒にインフラ改善を始める直前の構成図です。
買い物appはOpsWorksでEC2をプロビジョニングしているところや、RDS、SES、S3といったAWSサービスを使用しているところは以前と変わっていません。差分は以下になります。
- 読み物app: EC2 → ElasticBeanstalk
- インフラ監視: NewRelic → Mackerel
- エラー検知: Sentry採用
そしてこの頃の大きな課題は以下です。
- OpsWorks, ElasticBeanstalkの変更が簡単にできない
- セキュリティまわりの対策が手薄
OpsWorksはChefのレシピを元にEC2をプロビジョニングしてくれるのですが、時間がかかりますし、レシピに不具合があれば途中で失敗します。プロビジョニングで10分以上待ったが失敗…というのもザラでした。
また、当時は1つのAWSアカウントに複数環境が入っていたので、本番のAWSアカウントでコンソール上から試すしかなく心理的にも作業しづらい状況。
うまくプロビジョニングできたらできたで、効率的なオペレーションが整備できていなかったため、新旧のEC2の付け替えをAWSコンソール上から台数分ポチポチ…。開発時と本番反映時の作業負荷が大きく、簡単には変更しづらいものとなっていました。
イベントでも触れましたが、使っていたOSが古くなってきていたことも本格的にインフラ改善を行うきっかけになりました。
ElasticBeanstalkは元々OpsWorksで動いていたものを本番もDockerで動かしたいという考えから採用されました。
ただ、イージーなのですがシンプルではなく、AWSのコンソール上からElasticBeanstalkを使ってリソースを作成すると、裏側ではCloudFormationが作られそこからいろんなAWSリソースが自動で作られ管理されるようになります。
その関連したAWSリソースを変更したいと思ったときに、リソースの設定をCloudFormationを使わず直接変更してしまい、CloudFormationの設定と差分が発生した結果環境が壊れてしまうことがあります。実際、ElasticBeanstalkの変更が行えなくなったり環境自体の削除もできなくなりAWSサポートに連絡して削除してもらうなどの問題も発生していました。
Mackerelに関しては私が以前使っていたこともあり、導入しやすかったため採用しNewRelicから移行しました。カヤックさんとの改善が始まる前での導入でしたが、カヤックさんもMackerelを使っており、専用のOSSを作られていたり知見が豊富だったので結果的に採用してよかったです。
今(2022年11月頃)のインフラ構成
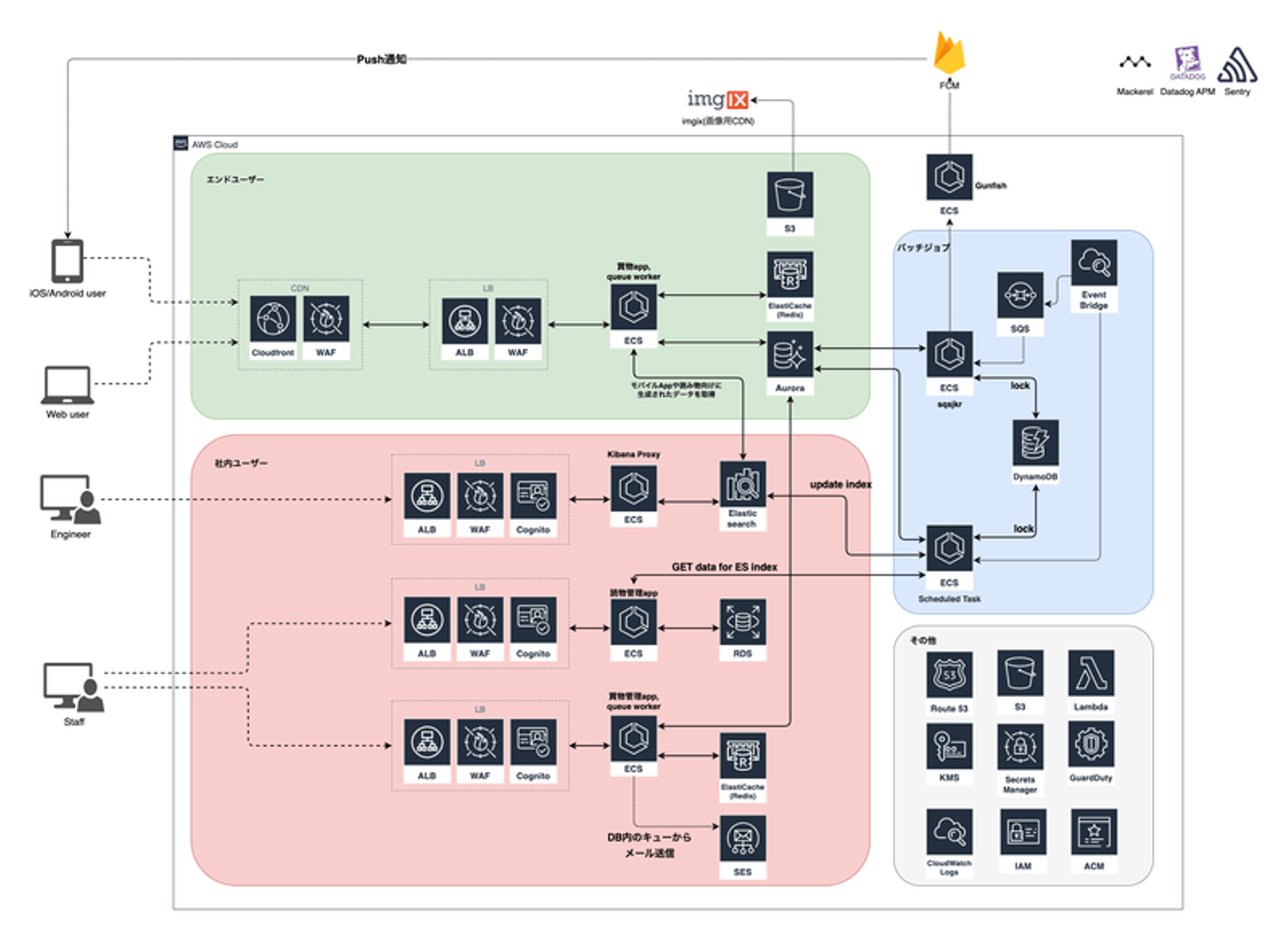
![]()
今現在の構成図
これが現在の構成です。AWSサービスが増えて一見複雑になったように見えるのですが、コンポーネント同士のつながりはシンプルです。以前の構成との大きな差分をピックアップします。
- OpsWorks、ElasticBeanstalkがECS/Fargateに
- ECSになるに合わせてバッチジョブ構成変更
- エンドユーザー側のアプリケーションは一つに統合
- CloudFront、WAF、Cognitoなどアプリケーション前段部分の拡充
- ElasticsearchやGunfish/FCM(Push通知基盤)など追加
- Datadog APM採用
OpsWorks、ElasticBeanstalkに関してはすべてECS/Fargateに移行しました。複数アプリケーションあったのでトータルで1年以上かかってはいますが、このおかげで、以下の点で管理や変更作業がしやすいというメリットを享受しています。
- Fargateのためサーバー管理が楽に
- 手動によるサーバーの作り直しやターゲットグループ入れ替えが不要に
- プラットフォームが統一されてスイッチングコスト減。CI/CDも対応しやすい
- インフラ部分の設定の見通しがよくなった
- Secret Managerを使用し秘匿情報管理がより簡単でセキュアに
- バッチ・キューワーカーの冗長化
ECS移行のタイミングと合わせて、AWSリソースはすべてterraformで管理するようになりました。他のメンバーからのレビューも受けやすくなりましたし、GitHubで変更履歴も残っているので、品質や変更のしやすさが大きく改善しています。
CloudFront、WAF、Cognitoなどアプリケーション前段部分拡充の他にも、RDSがAuroraになったり、KMSやSecrets ManagerやGuardDutyをちゃんと使うようになったり、AWSアカウントもマルチアカウントにして運用するなど、システムの安定性とセキュリティの向上にも着手し続けてきました。
結果、大きな不具合が起きたらどうしようといったリリースや運用面での心理的なハードルが下がり、開発に集中できる環境の整備が進んだと感じています。
参考: 北欧、暮らしの道具店を支えるAWSマルチアカウント運用(Speaker Deck)
また、構成図には記載しませんでしたが、DBへアクセスするための踏み台サーバーもEC2からECSに移行しています。
FargateでECSタスクを用意しておりSession Managerを利用しトンネルさせています。
ECSのデプロイツールとしてecspressoを採用しているのですが、ecspressoでタスク数の操作もできるため、踏み台が必要なときには1、使わないときは0にすると同時にSession Managerで登録されたマネージドインスタンスの登録も解除するという運用にしています。
踏み台サーバーは頻繁に使うものでもなく、起動/停止が早いのでとくにストレスなく、サーバー費用を抑えつつセキュアな状態で運用できていると思います。
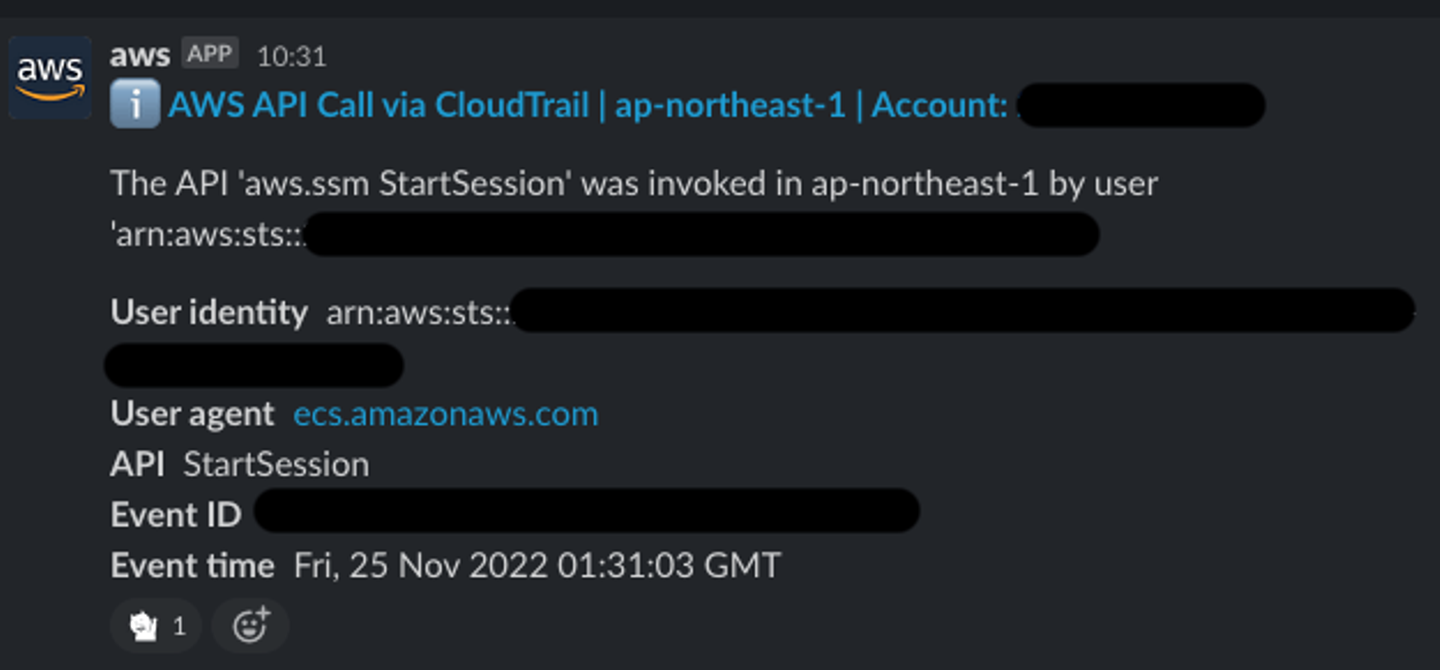
なお、セッションが始まったらChatbotからSlackに通知されるなど監査体制も整備しました。
![]()
Slack通知例(絵文字は北欧、暮らしの道具店の猫ちゃん。LINEスタンプもあります)
ElasticsearchやPush通知基盤(Gunfish, FCM)まわりはインフラ改善の一環ではなく、モバイルアプリのリリースに合わせて導入されたものになります。この記事では詳細を割愛させていただきますが、参考ブログのリンクを記載します。
Datadog APMに関しては、負荷試験を実施するタイミングで導入しました。いくつかAPMのサービスを比較した結果、コスト・導入のしやすさで選択しています。また、このとき負荷試験ツールとしてk6を使うなどもしています。詳しくは下記ブログに記載しているのでご覧ください。
まとめ
5年間のインフラ構成の変遷を追いながら、課題と実際の取り組みを紹介しました。
年単位での変遷なので一気に変わったように見えますが、当然、一足飛びで今の状態になったわけではありません。少し先を見据えて、少しずつ改善を加えた結果が年月を積み重ね、気づくと大きな変化になっていました。
少し話は変わりますが、開発チームのパフォーマンスを図る有名な指標となっているFour Keysに、5つ目の指標として「信頼性(運用のパフォーマンス)」が2021年に加わっています。
クラシコムでは数値化できてはいませんが、運用が安定し信頼性が高まると、開発のパフォーマンスも上がることはこの5年間の私の肌感ではありますが強く感じました。
今後もより良いサービスにするべく、SREの活動は継続して健全なシステムを作り続けたいと考えています。
一緒に「北欧、暮らしの道具店」というサービスを開発してくれるエンジニアを募集していますので、気になる方はぜひ一度Wantedlyからご連絡ください。
株式会社クラシコムでは一緒に働く仲間を募集しています
/assets/images/8987032/original/ddeeb212-469f-4efc-9ee4-c5b04a64e96d?1646380372)


/assets/images/8987032/original/ddeeb212-469f-4efc-9ee4-c5b04a64e96d?1646380372)


/assets/images/8987032/original/ddeeb212-469f-4efc-9ee4-c5b04a64e96d?1646380372)


/assets/images/8962265/original/c7866d47-17e7-4032-8d3d-04275630324d?1646121547)
