/assets/images/9254871/original/24e67d7f-0723-4fa9-bd00-255b86ba036e?1649813849)


/assets/images/7671433/original/23a5533f-196e-472a-9727-7a0276421aac?1651023931)
株式会社バンダイナムコネクサスでは一緒に働く仲間を募集しています
(※本記事のML基盤は下記に更改されました。よろしければ下記の技術記事をご覧ください)
https://www.wantedly.com/companies/bandainamco-nexus/post_articles/891629
こんにちは!
バンダイナムコネクサスのデータ戦略部で機械学習PJTのPMをしている高野です。
データ戦略部ではグループ内事業の意思決定に貢献するために様々な分析PJTを進めていますが、同時に機械学習機能開発も行っています。
そこで今回の記事では機械学習機能提供の要となるML基盤について紹介します。
ML基盤とは?
下記図のように、ML基盤とはバンダイナムコグループ内の各サービスに対して機械学習機能を提供するシステムになります。
(機能提供対象としているサービス一覧はこちら)
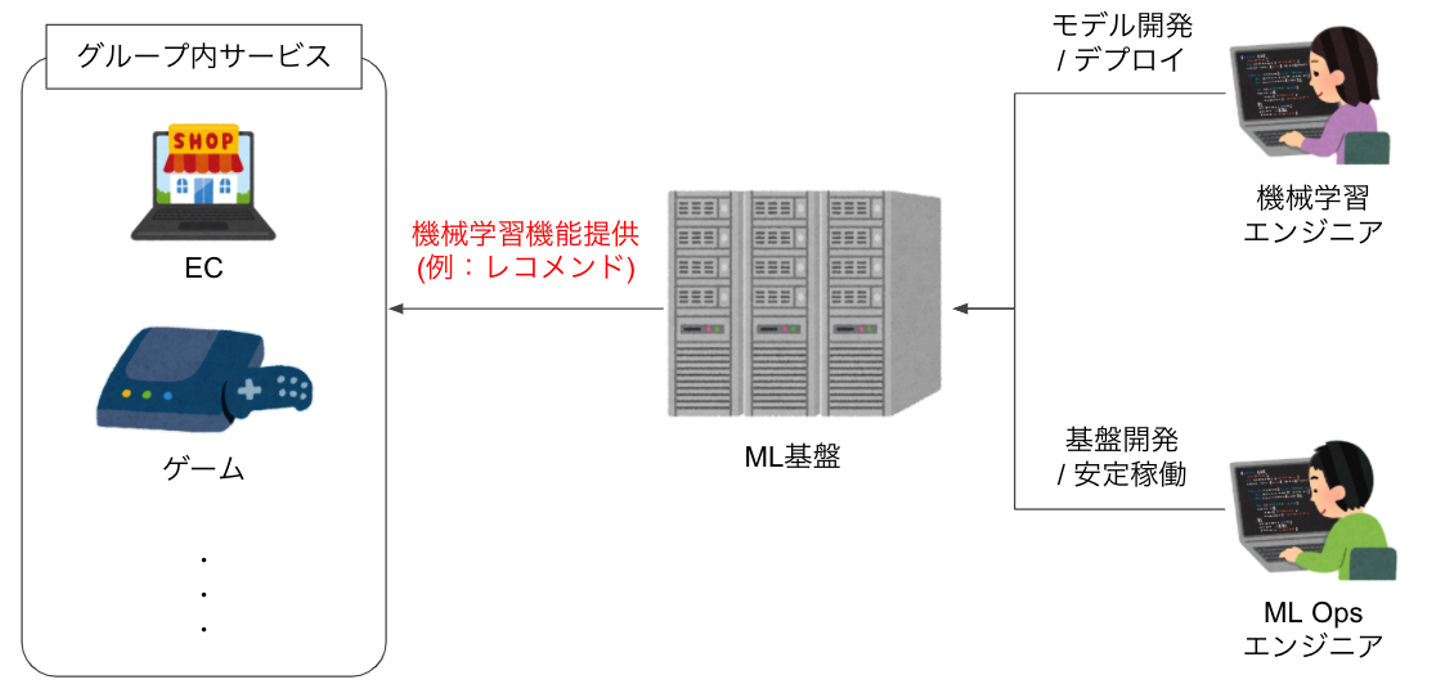
機械学習モデル開発 / デプロイは機械学習エンジニアが担当し、基盤開発 / 安定稼働をML Opsエンジニアが担当するという役割分担にしています。
ML基盤のシステム構成概要
ML基盤のシステム構成は下記図のようになります。
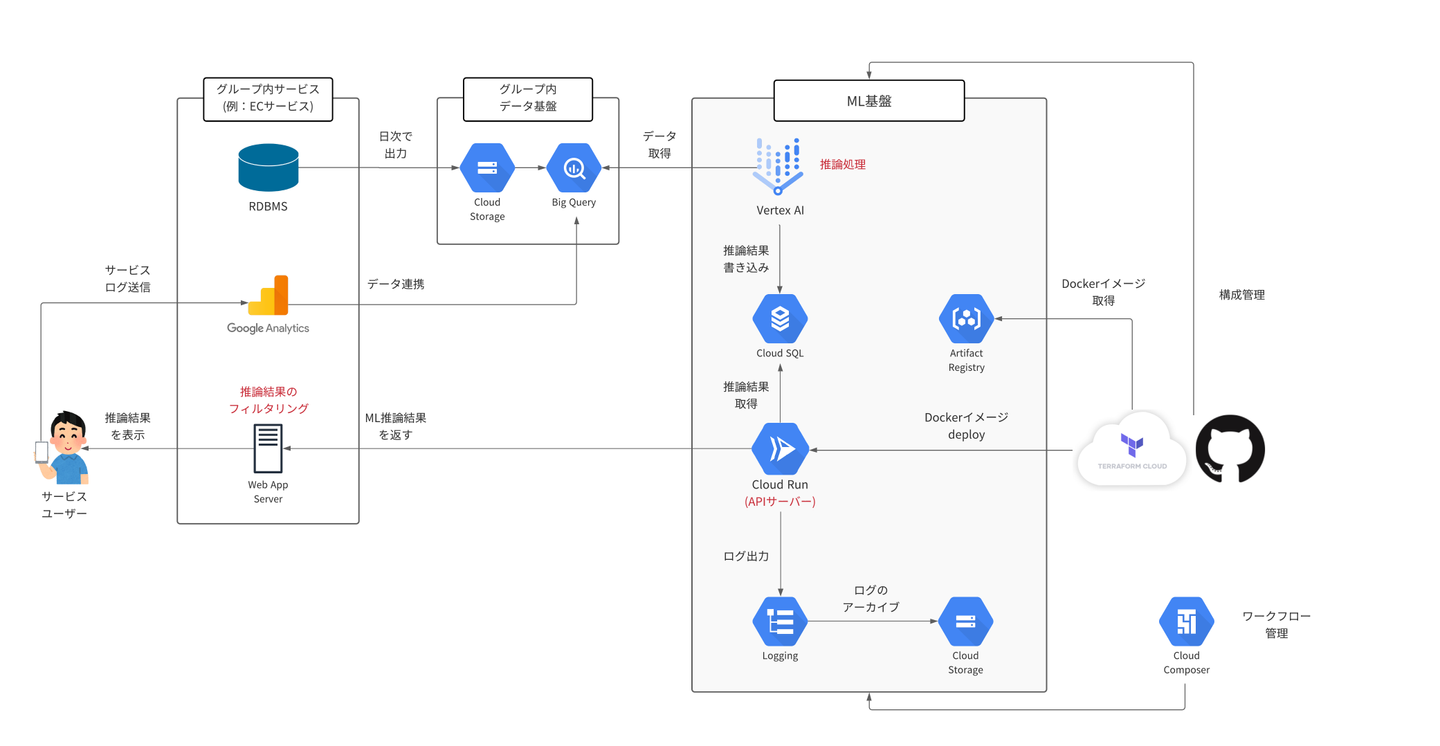
システム構成の詳細は後述しますが、以下3点が特徴となります。
①推論にはDBデータ、Google Analytics(以下GA)データを利用。
②推論結果の提供はAPIサーバーを利用。
③短期間(3ヶ月)でスピードを重視してゼロから構築したので、スモール構成になっている。
またグループ内データ基盤については、こちらの記事で詳細を説明しています。
ML基盤のシステム詳細について
以上を踏まえて、ML基盤のシステム詳細について説明します。
ワークフローエンジンについて
ワークフローエンジンにはCloud Composerを利用しています。
他の手段として、Airflowを自前で構築する方法もありましたが、下記理由によりCloud Composerを選択しました。
・細かいインフラをあまり気にしなくて済む (スモールチームなので運用コストは最小限にしたい)
・GCPリソースとの連携しやすさ
ML環境について
ML環境にはVertex AIを利用しています。
推論にはBig Queryに蓄積された下記2種類のデータを利用しています。
・サービスのDBデータ。
・サービスのGAデータ (ログデータの代替として利用)。
ノートブック管理にはVertex AI Workbenchを利用しています。
開発スピードを優先したスモール構成で開発を進めたかったので、マネージドノートブックが利用出来るVertex AI Workbenchを選定しました。
APIサーバーについて
APIサーバーには、Cloud Runを利用しています。
またAPIサーバーが推論結果を参照する先はCloud SQLになります。
(図には記載していませんが、キャッシュサーバーとしてRedisを利用しています)
このようなAPIサーバー経由で推論結果を提供する方式にした事で、以下のようなメリットを享受しています。
・サービス側とシステム的に疎結合になる。
・リアルタイム性が求められる処理(例:在庫切れ商品の除外)をサービス側に委ねられる。
ログ取得について
ログ取得にはCloud Logging(旧:Google Stackdriver Logs)を利用しています。
前述のシステム構成図に記載の通り、API call / responseのログを取得しています。
(図には記載していないですが、コンテナログも取得するようにしています)
これは、将来的にAPIサーバー上でA/Bテストを実施出来るようにしたいという構想があり、その際に学習/推論用データを取得しておきたいためです。
そしてCloud Loggingの保存期間が過ぎたログはGCSでアーカイブする形にしています。
構成管理について
ML基盤全体のシステム構成管理にはgithubとTerraform Cloudを利用しています。
加えて、Dockerイメージ管理にはArtifact Registry(旧:Google Container Registry)を利用しています。
ML基盤の今後の展望
前述のように開発スピードを優先してスモール構成でML基盤を構築してきたので、今後取り組みたいテーマがいくつかあります。
そこで今後の展望について紹介したいと思います。
推論処理時間の短縮
現状のML基盤には推論前処理の時間が長めという課題があります。
現状内部検討している機械学習PJTにおいては問題ない水準なのですが、将来的にはボトルネックになってくる可能性があります。
そこで今後は推論前処理時間短縮に取り組んでいく方針です。
現状では解決方針として、以下2案を検討しています。
・案1:Kubeflow Pipelines(Vertex Pipelines)を利用して、推論処理実行を効率化し、処理時間を短縮。
・案2:推論処理を分散実行出来る(例:Spark, Beam)ようにして処理時間を短縮。
ML Metadataの管理
現状のML基盤には以下のようなML Metadataの管理が出来ていないという課題があります。
・モデルのバージョン管理
・学習に利用したデータセットの管理
開発・運用する機械学習モデルが少ないうちは問題無いのですが、将来的にはボトルネックになってくる可能性があります。
そこで今後はML Metadataの管理に取り組んでいく方針です。
現状検討している解決方針はVertex ML Metadataの導入になります。
ノートブックを定期実行可能にする
前述のように現状のML基盤では、Vertex AI Workbenchをノートブック管理に利用しています。
一方で将来的には、機械学習エンジニアやデータサイエンティスト(隣接チームに在籍)からjupyter notebook形式での定期実行の要望が出てくる事が予想されます。
そこで今後はpapermillを使って、ノートブックの定期実行および、APIでモデル結果のサービングまでを技術検証していく方針を取っています。
これにより、ソフトウェアエンジニアリングと機械学習モデル作成のタスクをうまく分離し、かつ、MLOpsエンジニアとモデル作成者の職務分掌を切り分けるML基盤の実現が可能となります。
Netflixでの参考事例:https://netflixtechblog.com/scheduling-notebooks-348e6c14cfd6
特徴量ストアの技術検証
将来的に開発・運用する機械学習モデルが増えてくると、機械学習エンジニアから以下のような要望が出てくると予想されます。
・特徴量管理が煩雑化してくるので一元管理したい。
・あるモデルで利用した特徴量を別のモデルで再利用したい。
そういった要望に備えて、特徴量ストアであるVertex AI Feature Storeの技術検証を進めています。
さいごに
ML基盤の紹介は以上になります。
今回紹介したML基盤を用いた機械学習PJTも内部では実施していますので、少しでも興味を持って頂けたら気軽にお話を聞きに来て下さい!
バンダイナムコグループの機械学習機能を実現するML基盤について

/assets/images/9254871/original/24e67d7f-0723-4fa9-bd00-255b86ba036e?1649813849)





/assets/images/13122158/original/24e67d7f-0723-4fa9-bd00-255b86ba036e?1682487997)
