/assets/images/4298867/original/660614d5-392c-46fc-9884-7aab50ba6fcc?1574300883)
株式会社プラスアルファ・コンサルティングでは一緒に働く仲間を募集しています
気味悪いくらいピッタリなタイミングで飛んでくる通知の裏側には健気に木を植え続けるマーケターの姿があった ~精度を上げるには森を作るしかない~

on 2022/08/08
「そろそろアレ買わないとなぁ」
スマホチラッ
「絶妙なタイミングでアプリの通知が来てる……こわっ……でもポチッちゃう……」
ポチー
場面は変わって、その1ヶ月前、"アレ"を販売する企業のEC(通販)マーケティング部にて・・・
「"アレ"、売れ行きは好調なんだけど、今一歩ターゲットにしてるお客さんに刺さりきってない感じがあるんだよなぁ」
「原因はいろいろありそうだけど、通知のタイミングが悪いから埋もれちゃって、うちが"アレ"を売り出したことを知ってもらえていないとかあるかもしれない」
「同じ時間に一斉通知するのはやめて、気味悪がられるかもしれないけど、一人ひとりスマホを見そうなタイミングに通知を飛ばしたい!できれば通知飛ばすべき時間とかも自動分類したい!」
「よし。ECサイトのアクセスログから自動分類してくれるモデルを作ろう!」
「モデルに使うのは決定木、以外にも色々あるらしいな・・・。他にはどんなモデルがあるんだろう」
「GBDTとかランダムフォレストとかオススメだよ。決定木を応用したモデルだし」
「それぞれの特徴とか比較してみようかな」
カスタマーリングス事業部で開発をやっています。油山です。
というわけでこの記事は、マーケティングの分析・予測の手法として、決定木とその派生手法について4回に渡って紹介する記事のその4、最終回です。
今回は、機械学習の良し悪しを測る概念と、実践的にもよく用いられている決定木の派生手法をさらっと紹介します。
- 気味悪いくらいピッタリなタイミングで飛んでくる通知の裏側には健気に木を植え続けるマーケターの姿があった
- 気味悪いくらいピッタリなタイミングで飛んでくる通知の裏側には健気に木を植え続けるマーケターの姿があった ~育った木はどんな姿をしているか~
- 気味悪いくらいピッタリなタイミングで飛んでくる通知の裏側には健気に木を植え続けるマーケターの姿があった ~育った木の良し悪しを測ってみる~
- 気味悪いくらいピッタリなタイミングで飛んでくる通知の裏側には健気に木を植え続けるマーケターの姿があった ~精度を上げるには森を作るしかない~ ←イマココ
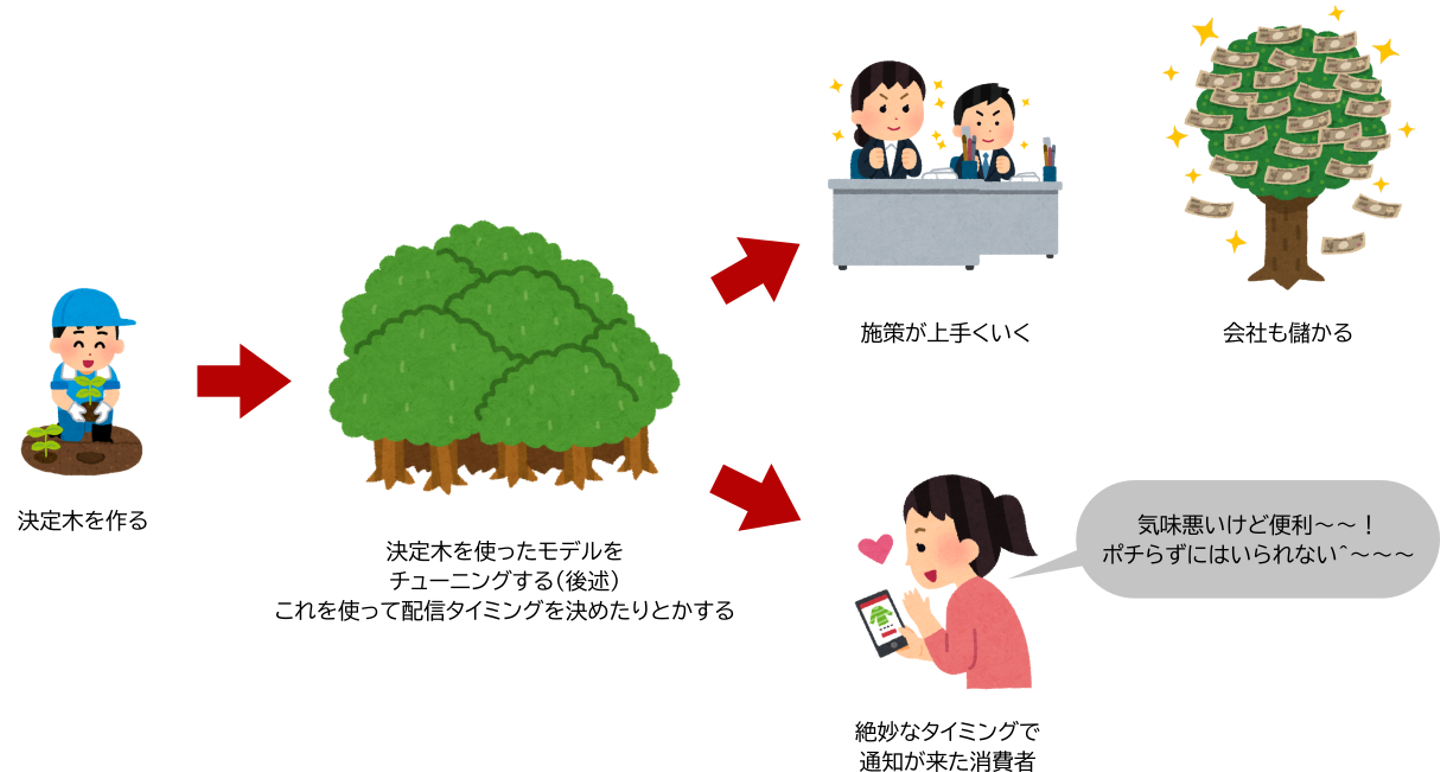
図1: マーケターが木を植えた結果、色々上手くいく様子を表した図
この一連の記事は決定木について、「どこでどう使うのか」「結果はどう解釈できるのか」「実践的にはどう使われているのか」を紹介するもので、次の内容から構成されます。
- マーケターの仕事は「分類」が肝心で、それを楽にする手段の1つとして決定木を紹介(第1回)
- 決定木は機械学習モデルの1つ。よくわからないのでさらっと機械学習を紹介(第1回)
- 例を交えつつ、決定木とは実際に何をしてくれて、どうやって使うのかを紹介(第2回)
- 悪い決定木の問題点を調べ、汎化性能という機械学習モデルの良し悪しを測るものさしを紹介(第3回)
- 決定木は1本単体で使うだけでは、その汎化性能に致命的な弱点があることを紹介(第4回)
- それを克服する、GBDTとランダムフォレストという決定木をたくさん用いる手法をさっと軽く紹介(第4回)
弊社のカスタマーリングスでも実際に、メールなどの配信の際に最も開封・既読されやすいタイミングを顧客1人1人に対して予測して、この記事のタイトルのような気味悪いけれどなんだかんだ嬉しいことをする機能などに、決定木の派生手法であるGBDTが応用されています。
前回(第3回)の記事はこんな内容でした
- データは、[全体の平均] + [個体差] + [ノイズ] という形に分解できる。
- 深すぎる決定木は、本来 [ノイズ] に含まれるべき情報が [個体差] に紛れ込み、過学習を起こしてしまう。(高バリアンス)
- 少ないデータから作られた決定木は、そもそも [全体の平均] が正しく見積もれない。(高バイアス)
- 汎化性能は、まだ見ぬ未知データに対する予測精度のことで、学習済みモデルの良し悪しを測るものさし。
今回はこんな内容です
- 決定木の学習モデルとしての特徴をまとめ、特に過学習を起こしやすいという致命的な弱点を確認する。
- 決定木をベースとするGBDTとランダムフォレストという学習モデルを、決定木単体の持つ弱点を克服するものとして紹介し、それぞれの特徴をまとめる。
学習モデルとしての決定木は汎化性能に難あり、、、
第3回まで、決定木というモデルの話をしてきましたが、機械学習に用いることができるモデルには様々な種類のものがあります。
例えば、ニューラルネットワークや(一般化)線形モデル、この後触れるランダムフォレストやGBDTなどです。
では、これらと比較して決定木はどういう特徴を持っているのでしょうか。
ここで、モデルに決定木を採用して学習にかけた結果、いい決定木が得られたとします。
この決定木が持つ、いい特徴と悪い特徴を見てみましょう。
いい特徴
- シンプルで解釈がしやすい(ブラックボックスではない)
- 数値以外のデータもそのまま使える
- 前処理をそんなに頑張らなくてよくて楽
- 分類だけでなく回帰にも使える
1つ目に挙げた解釈性こそ、決定木が持つ最大のいい特徴です。
前回の記事の具体例でもありましたが、分類の特徴を別の言葉で説明することができるのです。
この後すぐ書きますが、実は決定木は機械学習のモデルには適さないモデルです。しかしこの解釈性から、人が何か気づきを得たいときのデータ分析の手法として、決定木単体でもまだまだ需要があるのです。
2つ目、3つ目に挙げたものは、実際に機械学習に使うときの話です。これは、決定木をベースとするGBDTやランダムフォレストなどのモデルも持っている特徴です。
4つ目に挙げたものは、分類だけではなく、売上や購入間隔といった数値の予測にも使えるということです。
悪い特徴
- 過学習しやすく、汎化誤差が大きくなりがち
挙げた特徴こそ1つですが、これは致命的です。
第3回の「汎化性能で良し悪しを測る」の節でこんなことを書きました。
決定木は深くすればするほど、より複雑なルールを表現できますが、やり過ぎるとその分教師データに引っ張られて過学習を起こし、汎化性能が悪くなってしまうというトレードオフがあります。
実践で用いる教師データは多くの場合とても複雑です。それは、予測を行うモデルも複雑な入力に対応できる必要があることを意味します。
ということは、モデルに決定木を採用し、複雑な予測を実現しようとすると、その決定木は必然的に深くなってしまい、それが過学習を招いてしまうことになるわけです。
ということで、現実に応用する際に、1本の決定木をモデルとして用いることはまずありません。
そう。モデルに用いられないのは、あくまで1本の決定木。
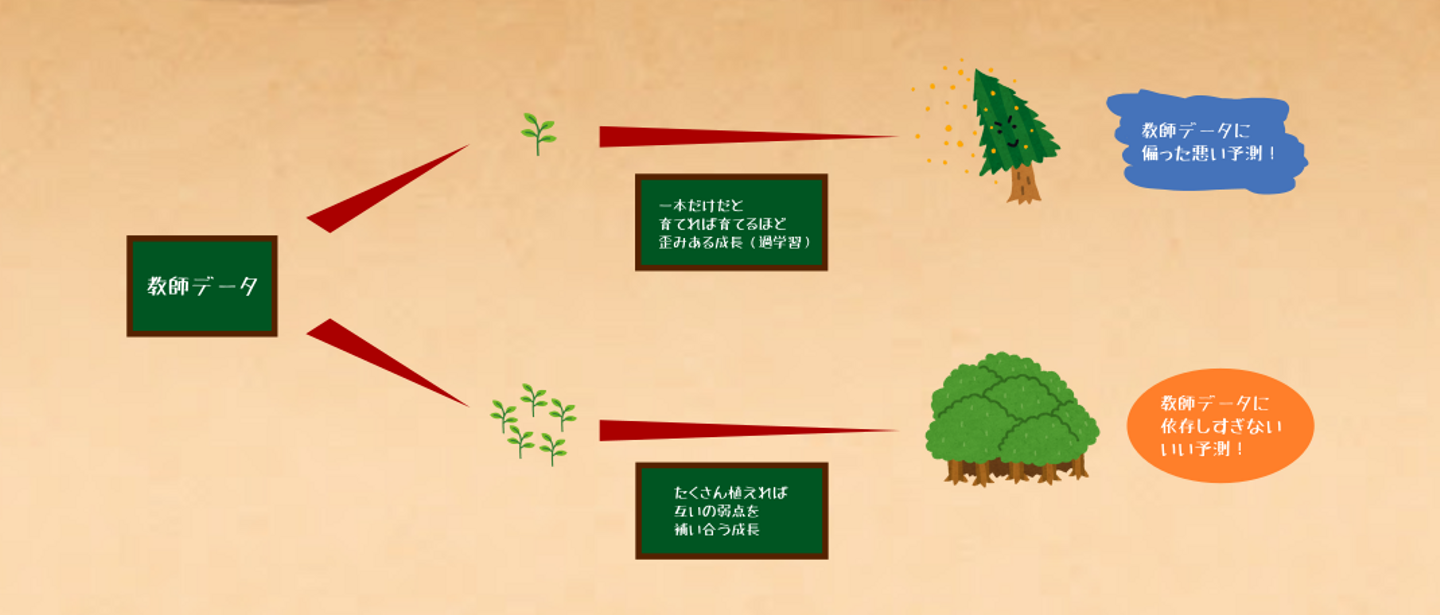
図2: 決定木単体は過学習しやすく、汎化性能が悪い。
三人寄れば文殊の知恵と言いますが、ダメなのは1本だけでどうにかしようとするからで、複数本組み合わせることで弱点を克服することができるのです。
それこそが、ここまでちょこちょこ名前を出していたGBDTとランダムフォレストという2つのモデルです。
実際のデータ分析や機械学習の最前線でもよく使われている、この2つのモデルを紹介してこの記事を締めたいと思います。
GBDT(勾配ブースティング決定木)
前節の通り、GBDTはいくつもの決定木を組み合わせたモデルです。が、一旦その中身は置いといて、学習モデルとして使う利用者の目線でその特徴を見てみましょう。
とりあえず中身は置いといてGBDTというモデルの特徴
GBDT(Gradient Boosting Decision Tree: 勾配ブースティング決定木)は、基本的に数値を予測したり、数値化できる何かを基にした分類をしたいときに用いられます。
名前は小難しく見えますが、中身をよく知らなくても、雑な設定でも(=手軽に)かなりいい精度を出せるモデルです。
何を予測したいかにもよりますが、徹底的に精度にこだわらないといけないような人たちからも「まずはとりあえずGBDTでやろうか🍻」と言われるような地位を確立しています。
以下がGBDTの特徴です。
- 手軽にかなりいい精度が出る
- 1本の決定木と同様に、データの前処理が手軽
- ランダムフォレストより、基本的にはいい予測ができるが、過学習はしやすい
- 後述の通り、直列に学習を進めるため、学習には時間がかかってしまう
優秀かつ手軽なモデルなので、精度にそこまでこだわり過ぎる必要がなければ「雑にGBDTで作るだけでも十分」というケースも多いことでしょう。
ちなみにGBDTにもいくつか種類があり、実用の際はLightGBMやXGBoost, CatBoostあたりを使うことになるでしょう。それぞれに異なる特徴があるのですが、ここでは割愛します。
GBDTは、たくさんの「誤差を予測する決定木」を直列に学習させたモデル
少しだけGBDTの中身を覗いてみましょう。
GBDTは前述の通り、和訳すると「勾配ブースティング決定木」です。
これは「勾配」「ブースティング」「決定木」という3つの要素に分けられます。
まずわかりやすい「決定木」という言葉。
これはGBDTというモデルがいくつもの決定木から構成されていることを意味します。
GBDTにデータを食わせたときの出力は、構成する個々の決定木の出力全てを加工(平均を取ったり、重みを付けて全部足したり)したものになります。
次に「勾配」という言葉。
これは詳細に踏み込まずに雑に言い切ってしまうと、「誤差を最小化させる」ように学習を反復して進めることを意味します。(正確には「どう最小化させるか」が勾配降下法というアルゴリズムと等しいことから来ています)
最後に「ブースティング」という言葉。
GBDTはいくつもの決定木からなる1つの大きなモデルですが、このようなモデルは、個々のモデルが出す予測結果を使って全体の予測を出します。この大きなモデルを学習させるには、それを構成する個々のモデルを学習させる必要があり、この個々を学習させる方法の1つがブースティングです。
ブースティングは、「まず教師データから1番目のモデルを学習させ、次に教師データと1番目の学習済みモデルから2番目のモデルを学習させ、......、次に教師データとここまでの全学習済みモデルから最後のモデルを学習させる。」という感じで個々のモデルを学習させる方法です。
ブースティングにより作られたモデルは、低バイアス高バリアンスなものになりやすいです。
GBDTは文字通り、この3つの要素を含むようなモデルで、次のようなものです。
- GBDTの学習方法
GBDTを構成する決定木それぞれに、データと基準値の間にある「ある種の誤差」を予測するようにブースティングにより学習させる。
- GBDTの出力
[基準値] + [各決定木の出力に重みをかけて足した値]
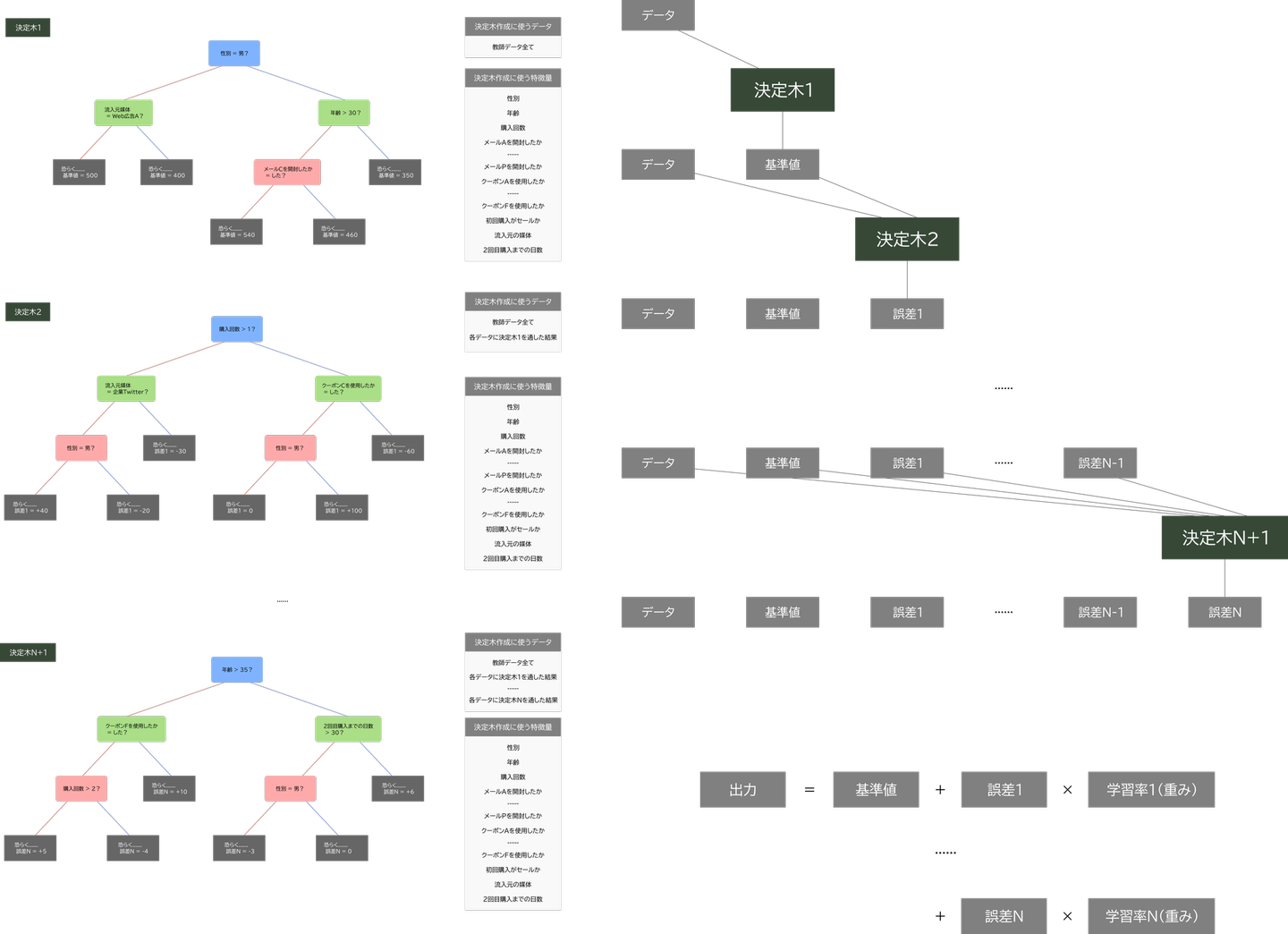
図3: (左)GBDTモデルを構成する決定木の例(図4に拡大版),(右)入力に対して行う計算の仕組み
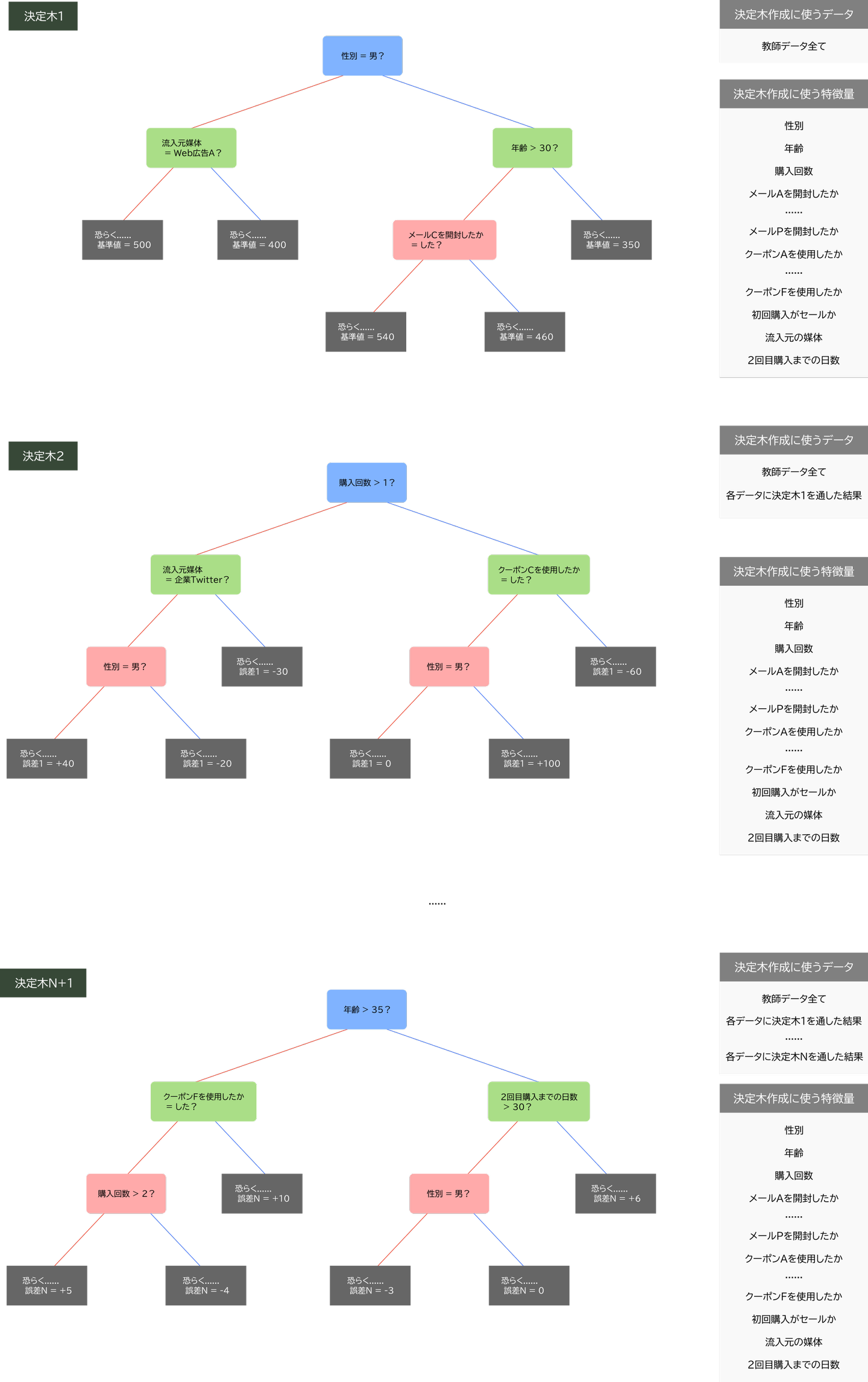
図4: GBDTモデルを構成する決定木の例(図3の拡大版)
ランダムフォレスト
ランダムフォレストは、GBDTとは違うアプローチでいくつもの決定木を組み合わせたモデルです。が、こちらも一旦その中身は置いといて、学習モデルに使う利用者の目線でその特徴を見てみましょう。
とりあえず中身は置いといてランダムフォレストというモデルの特徴
ランダムフォレストは、決定木と同様、分類に回帰とオールマイティに使えるモデルです。
ランダムフォレストもGBDT同様、人気のあるモデルで、次のような特徴があります。
- いい精度が出る
- 1本の決定木と同様に、データの前処理が手軽
- GBDTよりもいい予測は出しにくいが、過学習はしにくい
- 並列に学習を進めるため、学習が早い一方で、メモリを食う
基本的には「精度はGBDTに劣るが、学習スピードでは優位」というのがランダムフォレストの特徴です。
精度については、教師データに多様性があり、特徴量が多いほどいいものになりやすいです。
ランダムフォレストは、たくさんの「ランダムに学習させた決定木」を並列に学習させたモデル
少しだけランダムフォレストの中身を覗いてみましょう。
ランダムフォレストもGBDTと同様、いくつもの決定木から構成されたモデルです。その思想は、ざっくりと書くならば、決定木の素となる設定や教師データをちょっとずつ変えたような決定木を大量に用意し、それらの平均を出力とすることで、外れ値のような尖ったものの影響をなくすというものです。
なので、GBDTで行ったようなまどろっこしいことは必要ありません。
- ランダムフォレストの学習方法
ランダムフォレストを構成する決定木それぞれを学習させる際に、「教師データをランダムに間引いてみたり」「学習に用いる特徴量をランダムに変えてみたり」することで、決定木それぞれが多様な出力をできるようにする。どの決定木も自分以外の決定木に依存しないため、並列に学習を進められる。
- ランダムフォレストの出力
全決定木の多数決を採ったり、平均を取ったりした値
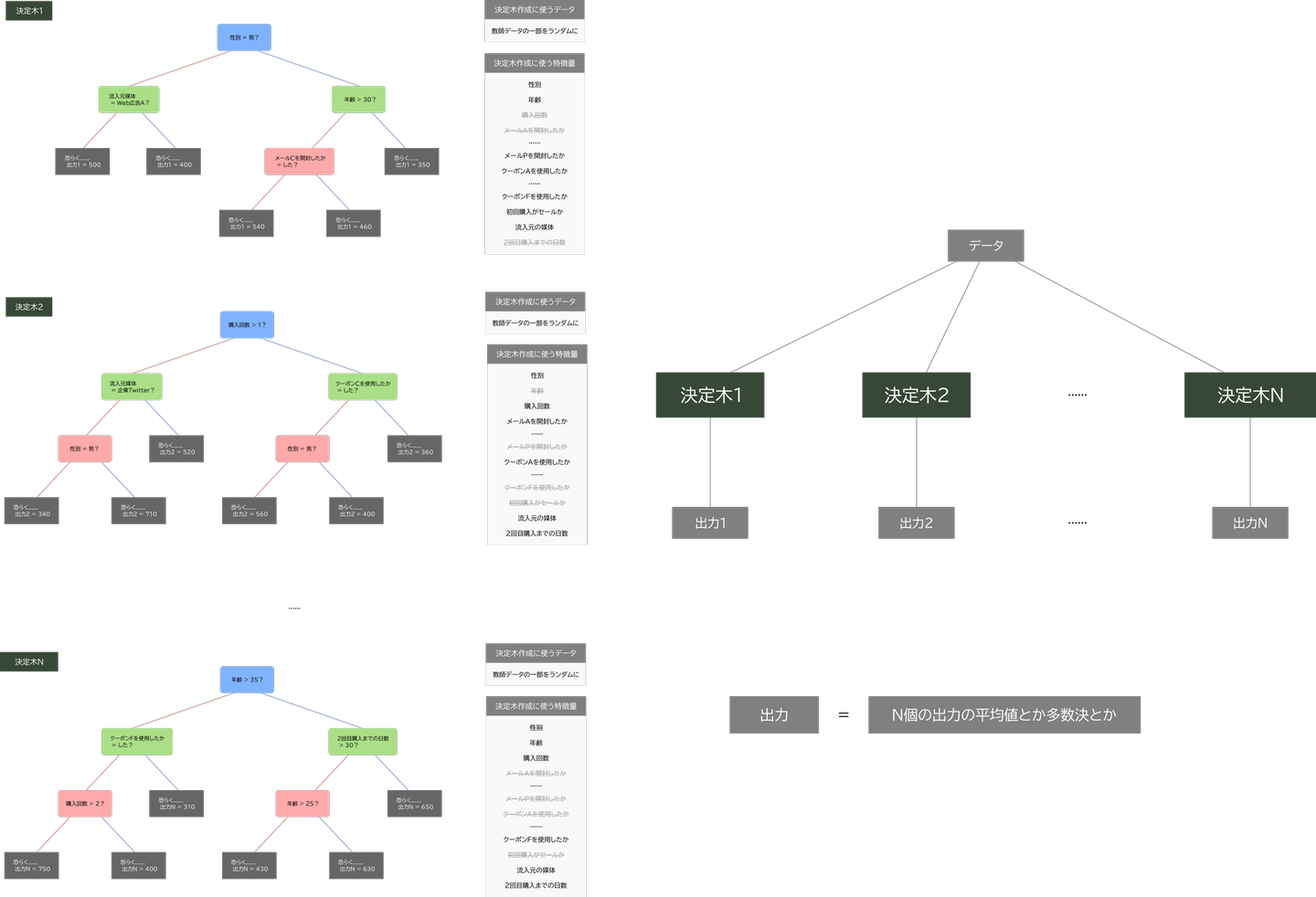
図5: (左)ランダムフォレストモデルを構成する決定木の例(図6に拡大版),(右)入力に対して行う計算の仕組み
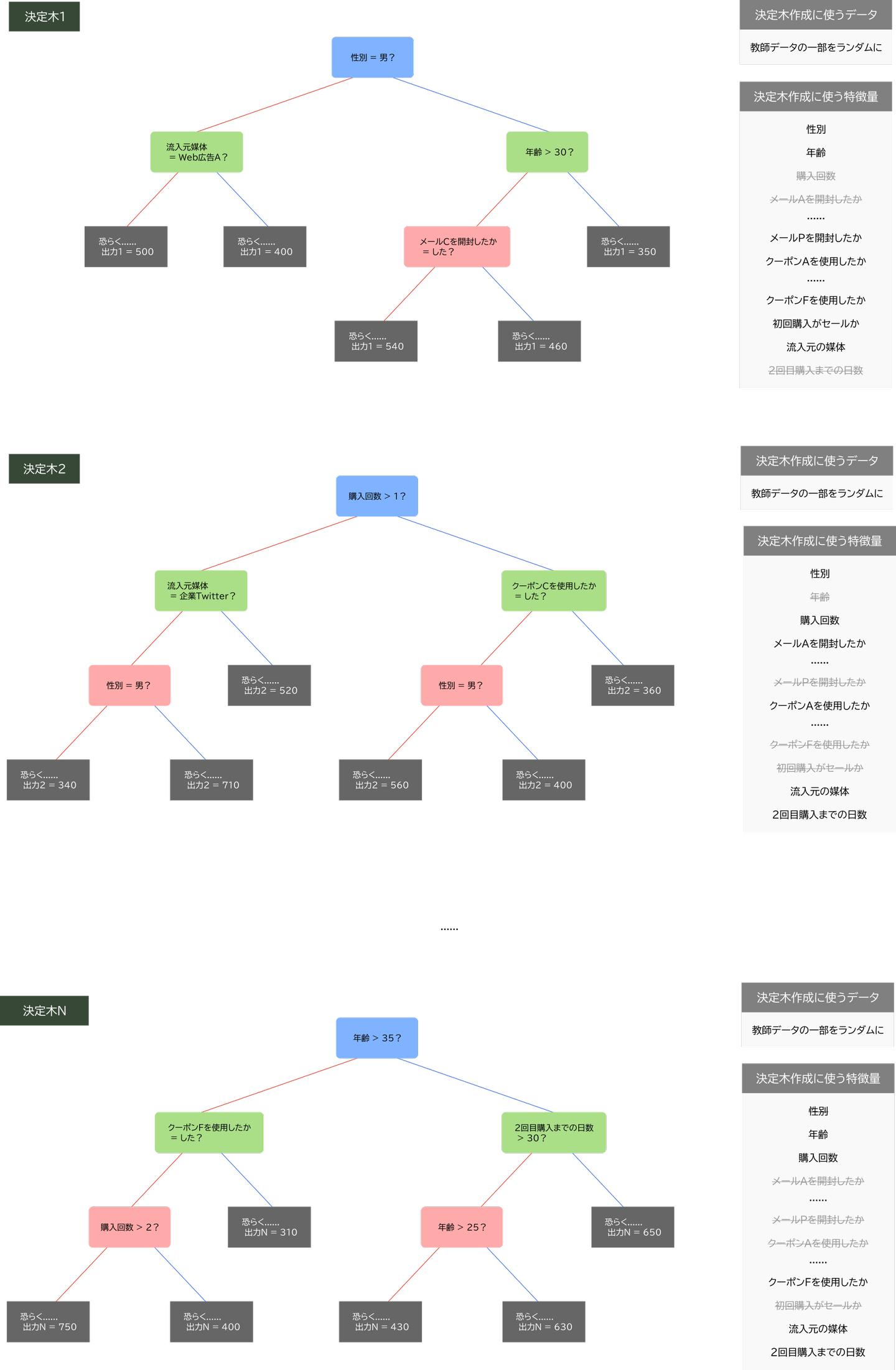
図6: ランダムフォレストモデルを構成する決定木の例(図5の拡大版)
ランダムフォレストという名前は、その学習方法を見ると正に言い得て妙ですね。
ランダムフォレストを構成する決定木それぞれは、ある程度深くても問題ありません。最後に全てを平均化したり多数決を採ったりして均されるので、データが偏ってさえいなければ、多様性のためにむしろ1本1本は過学習しててもいいというわけです。
多様性のあるモデルたちを並列に学習させる方法をバギングと言います。
バギングにより作られたモデルは、高バイアス低バリアンスなものになりやすいです。
ランダムフォレストは、決定木という低バイアス高バリアンスなモデルをバギングすることで、平均的に低バイアス低バリアンスを目指そうという思想で設計されているようです。
ということで第4回はここで終わりです。この記事はこんな内容でした。
- 決定木は、1本だけでは過学習を起こしやすいという致命的な弱点を持つ。
- いくつもの決定木を用いるGBDTとランダムフォレストというモデルは、1本だけのときの弱点を克服する。
- GBDTは手軽かつ高精度なモデルで、盛んに用いられている。
- GBDTはブースティングというやり方で、個々の決定木に「ある種の誤差」を直列に学習させる。
- ランダムフォレストはGBDTに精度は劣るが、学習速度に優位性があるモデルで、盛んに用いられてる。
- ランダムフォレストはバギングというやり方で、個々の決定木が多様性を持つように並列に学習させる。
これにて、4回に渡った「気味悪いくらいピッタリなタイミングで飛んでくる通知の裏側には健気に木を植え続けるマーケターの姿があった」という記事(長い・・・)はおしまいです。
第1回では、マーケティングには分類が必要なことと、機械学習モデルの話をしました。
第2回では、とある例を用いて実際に決定木を作ってみました。
第3回では、悪い決定木をもとに、モデルの良し悪しを測るものさしである汎化性能という概念を紹介しました。
最後に今回、決定木よりも汎化性能に優れた、GBDTとランダムフォレストというモデルを軽く紹介しました。
「通知の裏側に健気に木を植え続けるマーケターの姿が"必ず"いる」というわけではないですが、マーケティングには分類や予測といった機械学習の需要が確かにあり、「じゃあ具体的にどんな道具を使うのか?」という問いの解答の1つとして、決定木を使ったモデルが実際に動いているということを、ふんわりなぞるのがこの一連の記事だったと言えるでしょう。
ということで記事をお読みくださりありがとうございました!
/assets/images/4298867/original/660614d5-392c-46fc-9884-7aab50ba6fcc?1574300883)

株式会社プラスアルファ・コンサルティングからお誘い
この話題に共感したら、メンバーと話してみませんか?
気味悪いくらいピッタリなタイミングで飛んでくる通知の裏側には健気に木を植え続けるマーケターの姿があった ~精度を上げるには森を作るしかない~

/assets/images/4298867/original/660614d5-392c-46fc-9884-7aab50ba6fcc?1574300883)




/assets/images/7996434/original/660614d5-392c-46fc-9884-7aab50ba6fcc?1635406102)
