
/assets/images/11166630/original/4e8ad505-ff70-4d46-81bf-8e76f61338d7?1668387329)
株式会社コムデでは一緒に働く仲間を募集しています
はじめに
皆さんは機械学習やデータ解析をする際に何から着手しますか?
これから機械学習を始めたいと思っている方は、おそらく何から始めれば良いかわからないかもしれません。そこで、その答えの一つとしてAWS SageMaker Canvasを今回はご紹介します!
- 機械学習をどこから始めたらいいかわからない
- AWSについて学習をもっと深めていきたい
- インフラに関する知識をつけていきたい
記事の後半は実際に私がAWS SageMaker Canvasを操作し、結果の検証を公開しています!興味のある方はぜひ、この機会に試してみてください。
目次
- 機械学習の事前知識
- SageMaker Canvasとは
- 予測精度の検証対象について
- 料金形態
- SageMaker Canvasの使用手順・結果
- まとめ
機械学習の事前知識
機械学習にはいくつか種類があります。今回対象とするのは最も一般的な「教師あり学習」と呼ばれるものになります。「教師あり学習」というものは機械に対して学習データと正解のセットのデータ(データセット)を学ばせます。
この機械を「モデル」と言い、学習が終わったモデルを「学習済みモデル」と言います。「学習済みモデル」が手に入ったら、そのモデルに対してデータを入力することで、予測結果を得ることができます。
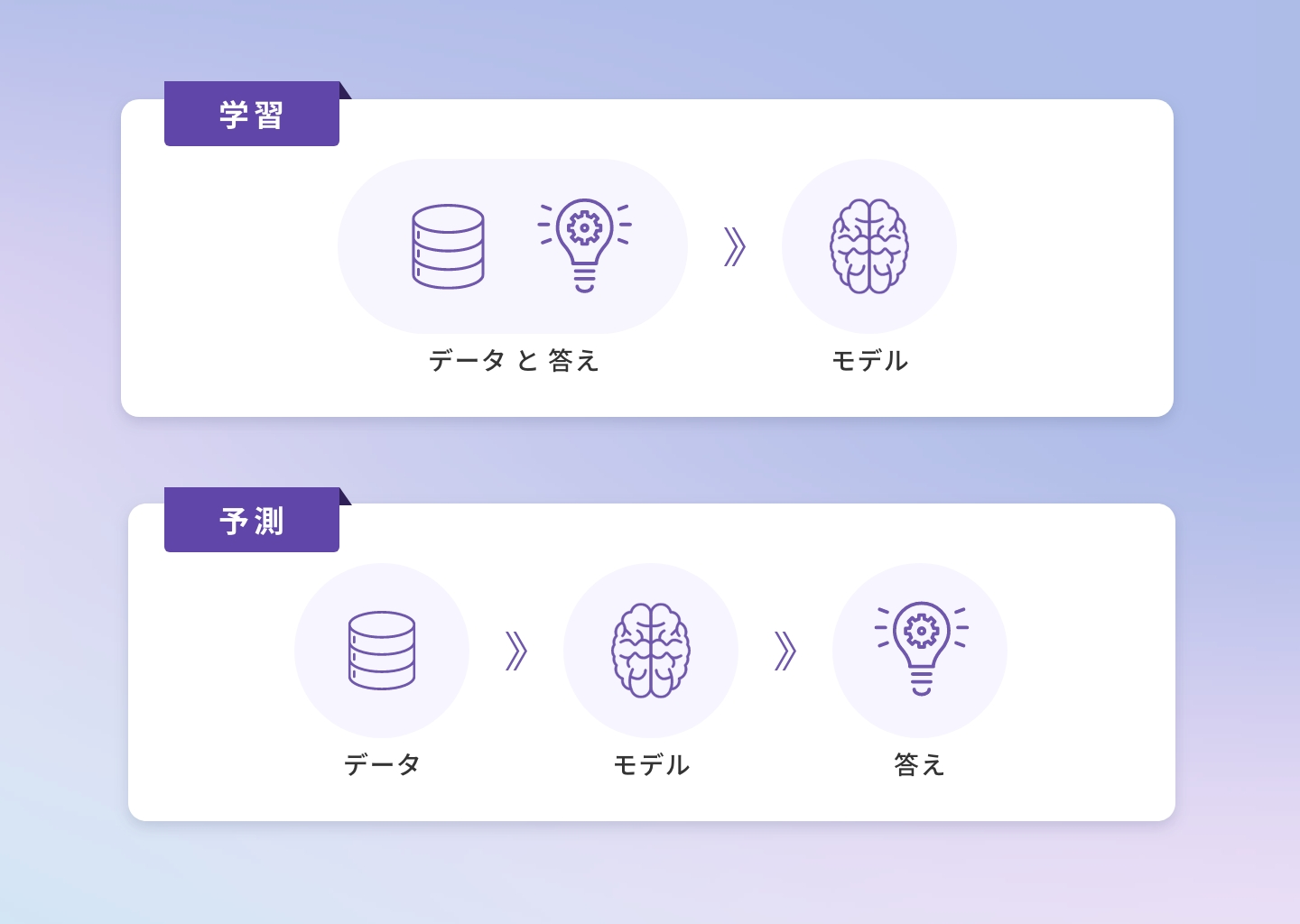
例えば、スーパーマーケットの曜日や立地などのデータと当日来客数(答え)がある場合、それらを使用し、学習モデルを作成します。作成した学習モデルを使用し、曜日や立地などのデータから未来の来客数を予測することができます。
ざっくりとした機械学習の説明は以上になりますが、実際にはデータ作成やモデル選定・策定などやることは多岐に渡り、特にデータの作成・加工には特徴量エンジニアリングといった一学問があるくらい深いものとなっております。
SageMaker Canvasとは
今回使用するSageMaker CanvasはノーコードでGUIでモデルを作成し予測を得られる※AutoMLサービスです。
本来機械学習に取り組む際には特徴量エンジニアリングをはじめとした様々な知識・技術が必要となります。これらの知識がなくとも簡単にデータ解析やモデル作成を行えるサービスとなっています。
初学者はもちろん、機械学習に慣れている方でも初動のアプローチとして利用することで、開発工程の短縮が可能となります。
※AutoML:機械学習を現実の問題に適用するプロセスの自動化、データからモデルを構築するプロセスの自動化などを目的とした技術
予測精度の検証対象について
予測精度の検証には機械学習のコンペティションプラットフォームで最も有名なKaggleのチュートリアル「Titanic - Machine Learning from Disaster」を使用します。
データが揃っていることと、チュートリアルであるため利用がしやすいですが、ある程度の思考力が必要となり難易度が高いため、学習における良いベンチマークになるかと思います。
興味がある方はご自身で試してみることをオススメします!日本語で解説しているサイトも多いので、機械学習の導入としてはベストの課題です。
このコンペティション内容は、映画にもなっているタイタニックの乗員データからそれぞれの生死を予測するといったものになっております。映画を観た方なら分かると思いますが、女性や子供、チケットのクラスが高いお金持ちの人ほど助かる可能性が高い結末を迎えます。
今回のデータの中には性別やチケットのクラスなどがあり、実際にチュートリアルを行う際は上記のようなことを考察しながらデータを見ていき、データを加工したりモデルを調整します。今回使用するSageMaker Canvasが、どこまでこのような考察を自動でやってくれるかが見所となります!
料金形態
SageMaker Canvasはコンソールの利用時間とデータの大きさによって従量課金されます。
・コンソール利用時間
SageMaker Canvasを利用した時間に応じて下記料金が発生します
$1.9/hour
SageMaker Canvasをログアウトするまでセッションが続くので使い終わったらさっさとログアウトしましょう。
・データの大きさ
トレーニングしたデータの大きさに応じて下記料金が発生します。

例えば10カラム×1000行のデータの場合
10000cellとなるので下記のようになります。
10000/1000000 = $0.3
※最新の料金形態についてはAWSのHPを確認してください
HPには記載されていないですが、モデルの学習か予測の際にインスタンスを使用しているようで、その料金も発生します。かかっても数時間程度の起動時間なのであまり気にしなくて良いかもしれませんが、一応ご注意ください。
無料枠も存在するので試しやすいのも良い点です。
参考:https://aws.amazon.com/jp/sagemaker/canvas/pricing/
SageMaker Canvasの使用手順と結果
お待たせしました!それではいよいよSageMaker Canvasを実際に使用していきましょう!
と、その前に事前作業としては以下の通りとなります。
- Kaggleのアカウントを作成し、Titanicコンペティションのデータセットを取得
- Kaggleのアカウントを作成後、Titanicコンペティションに遷移し、参加
- その後、タブ「Data」の右下にあるDownload Allからダウンロード
実際の使用手順は以下の通りとなります。
- 新規ユーザー作成
- SageMaker Canvasの起動・新規モデル作成
- データセットの登録・設定
- モデルの学習
- モデルの予測
1.新規ユーザー作成
SageMaker Canvasを使用するためにはまずユーザーを作成する必要があります。SageMaker のコントロールパネルへアクセス後、「ユーザーを追加」を押下しすべてデフォルトのままで構わないのでユーザー作成をしてください。
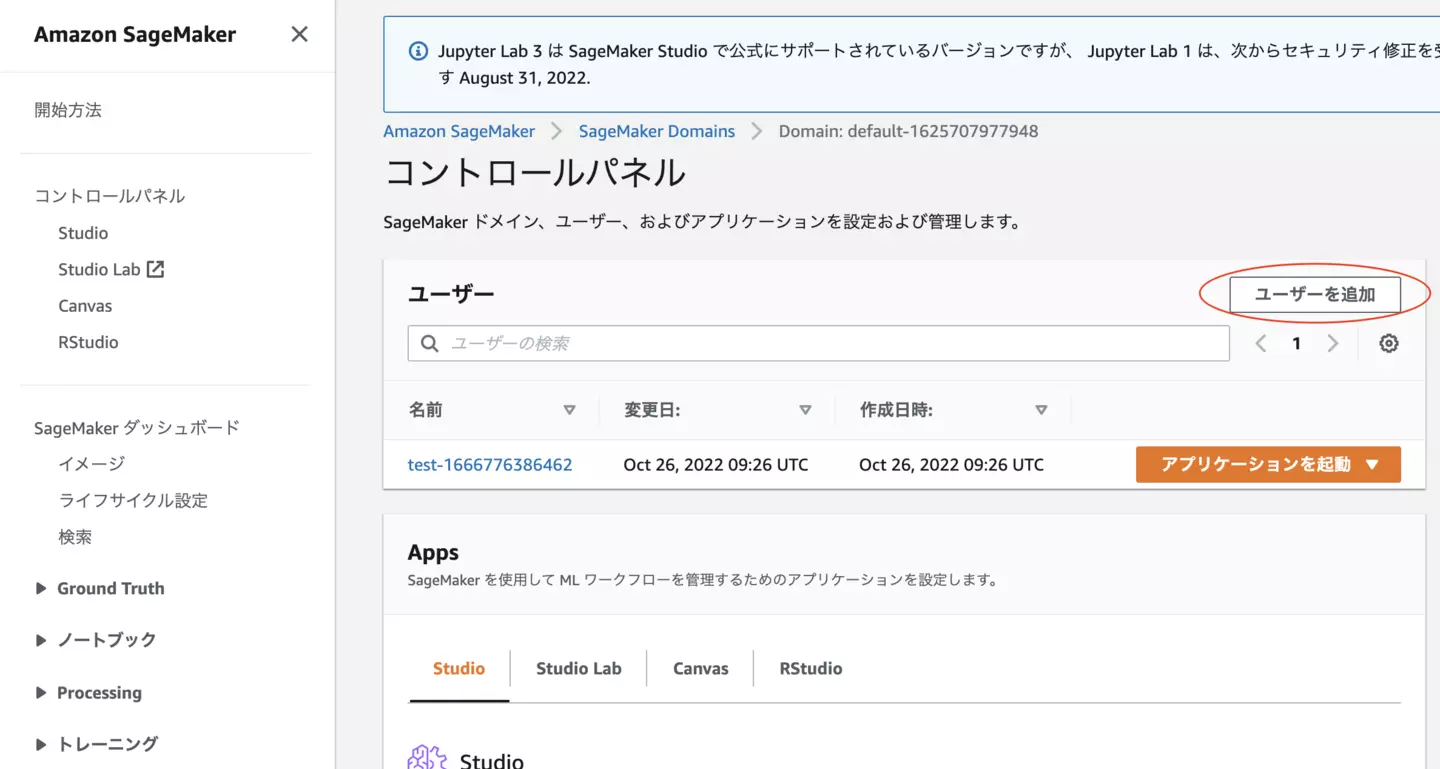
上記のようにユーザーが追加されるかと思います。
2.SageMaker Canvasの起動・新規モデル作成
作成したユーザーの右側の三角マークを押下し、「Canvas」を押下してください。
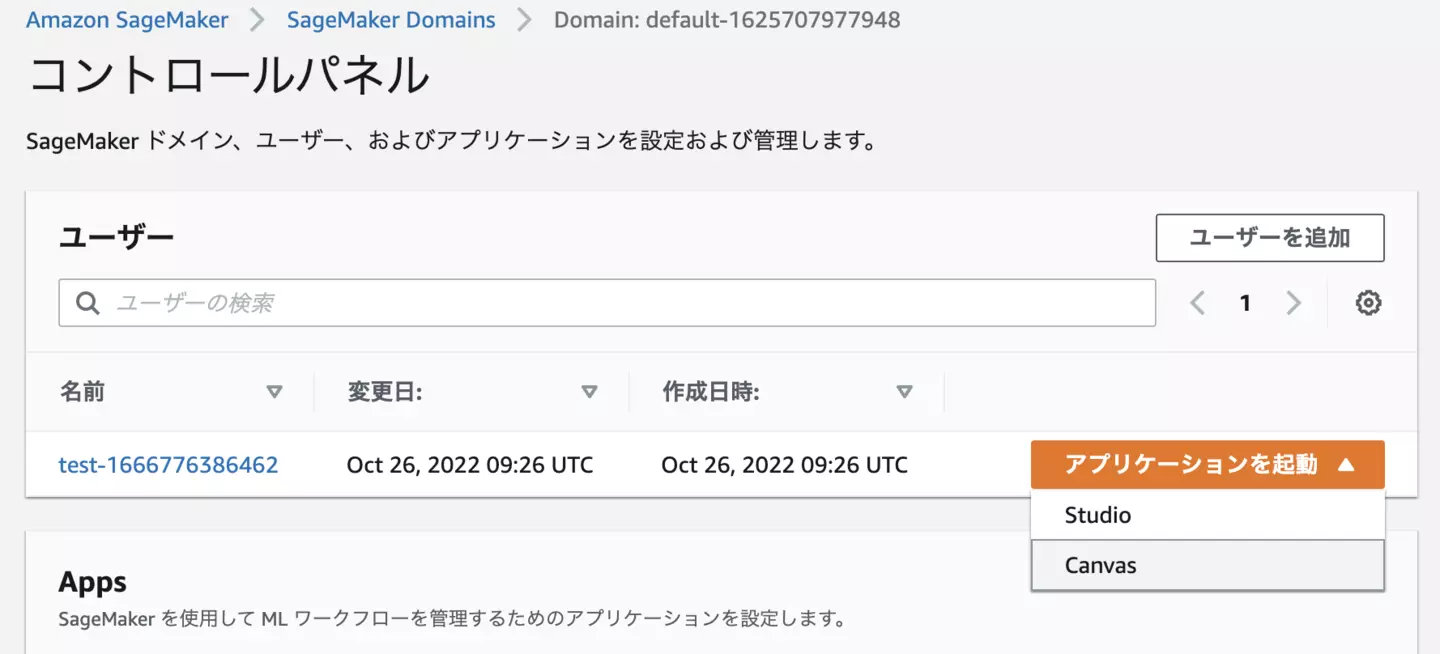
しばらくするとコントロールパネルが表示されます。
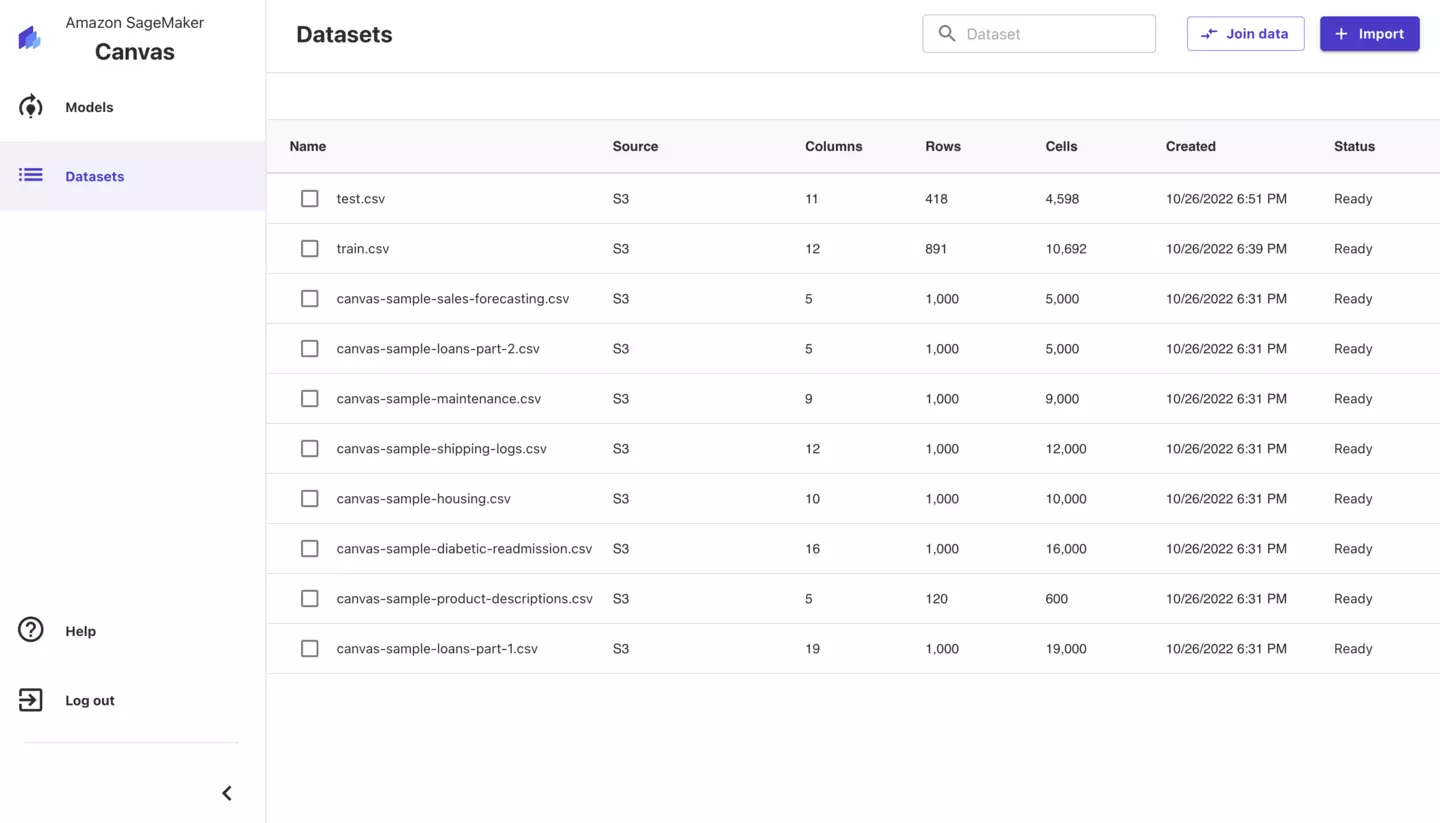
初期画面だと登録されているデータセットが表示されます。左のメニューより、モデルとデータセットの選択が可能です。
まず、モデルを作成しましょう。「Models」を押下してください。
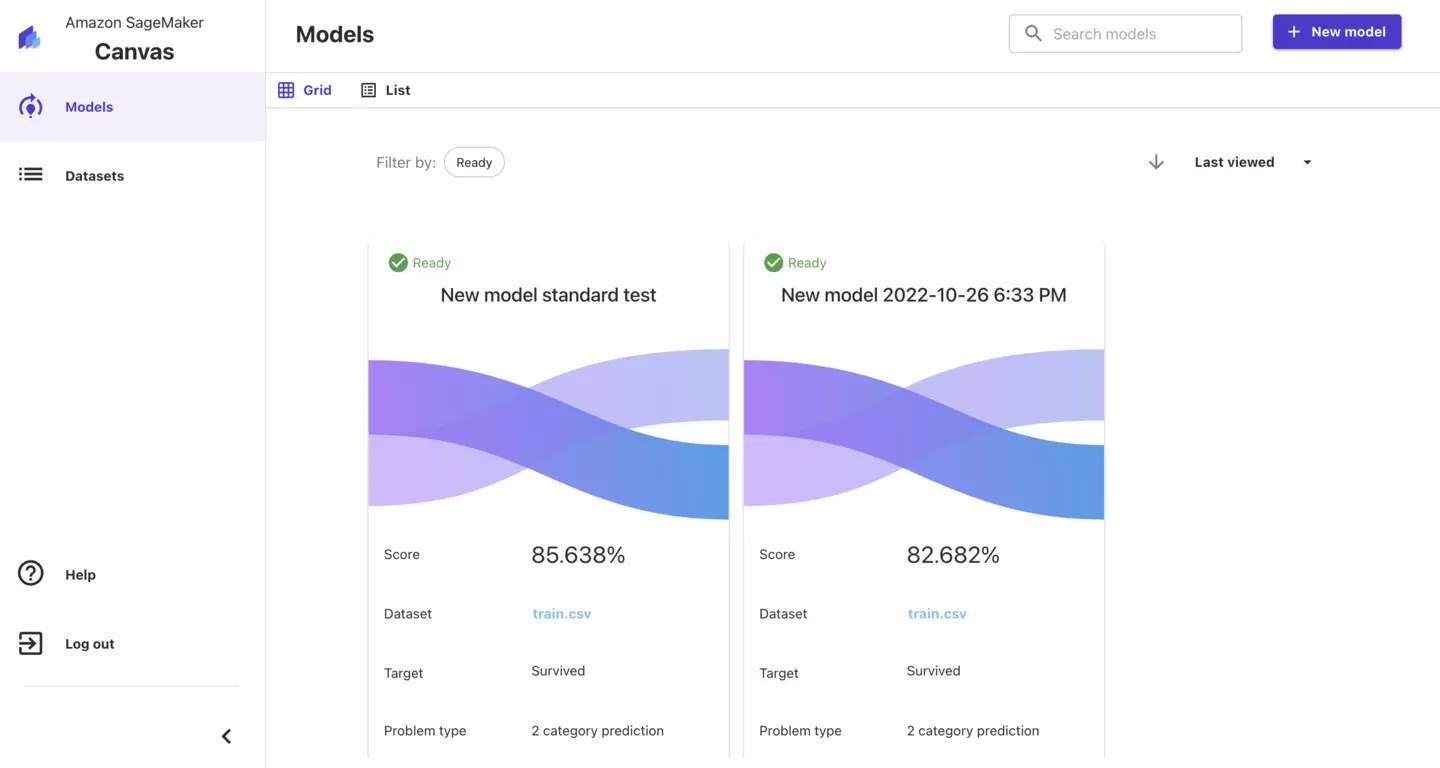
「New model」より、新しいモデルを作成することができます。
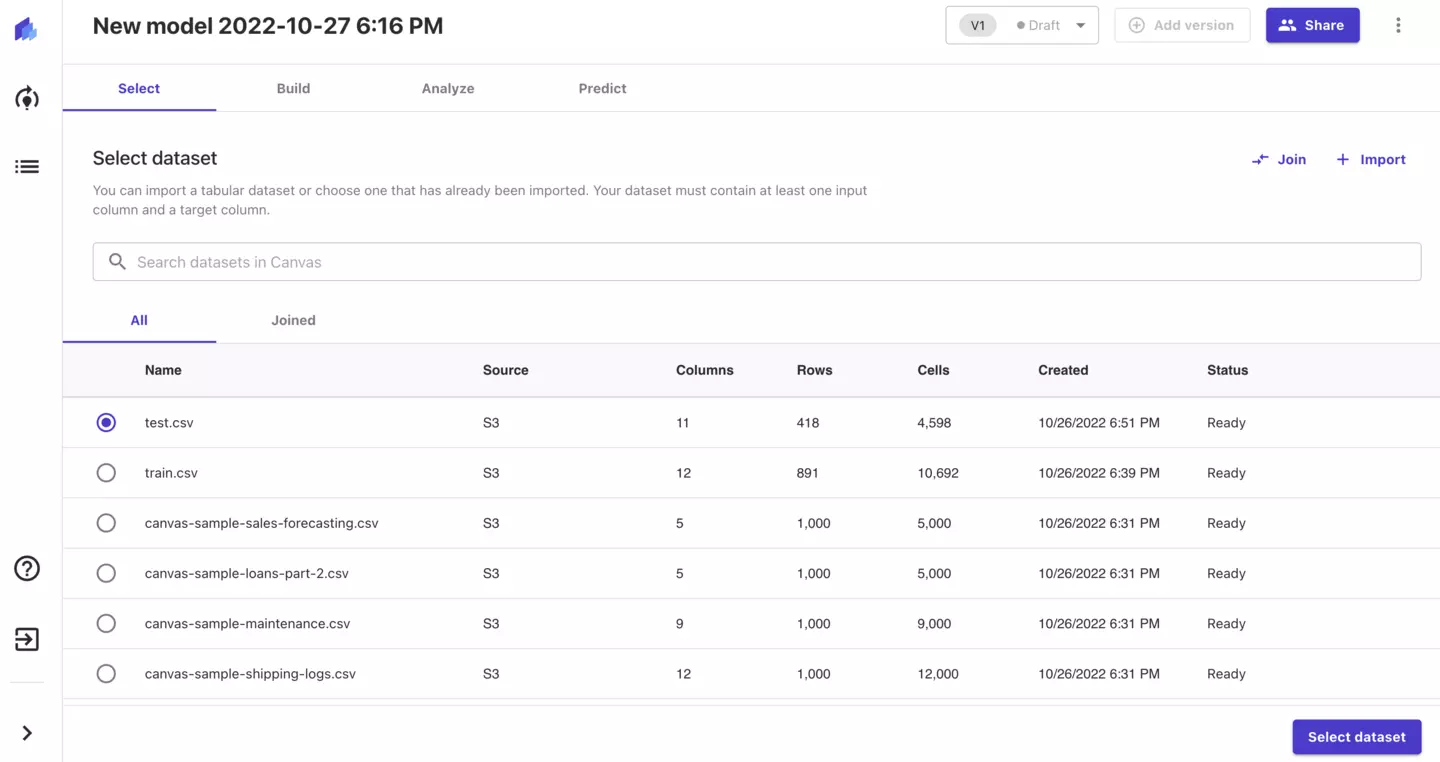
3.データセットの登録・設定
SageMaker Canvasではデータセットを登録する際、ローカル環境から直接アップロードできるようなのですが、手順が複雑だったので今回はS3にアップロードするようにします。
新しいS3バケットを作成し、事前作業で取得しておいたTitanicコンペティションのデータセットを保存してください。
その後、「Import」ボタンをクリックし、
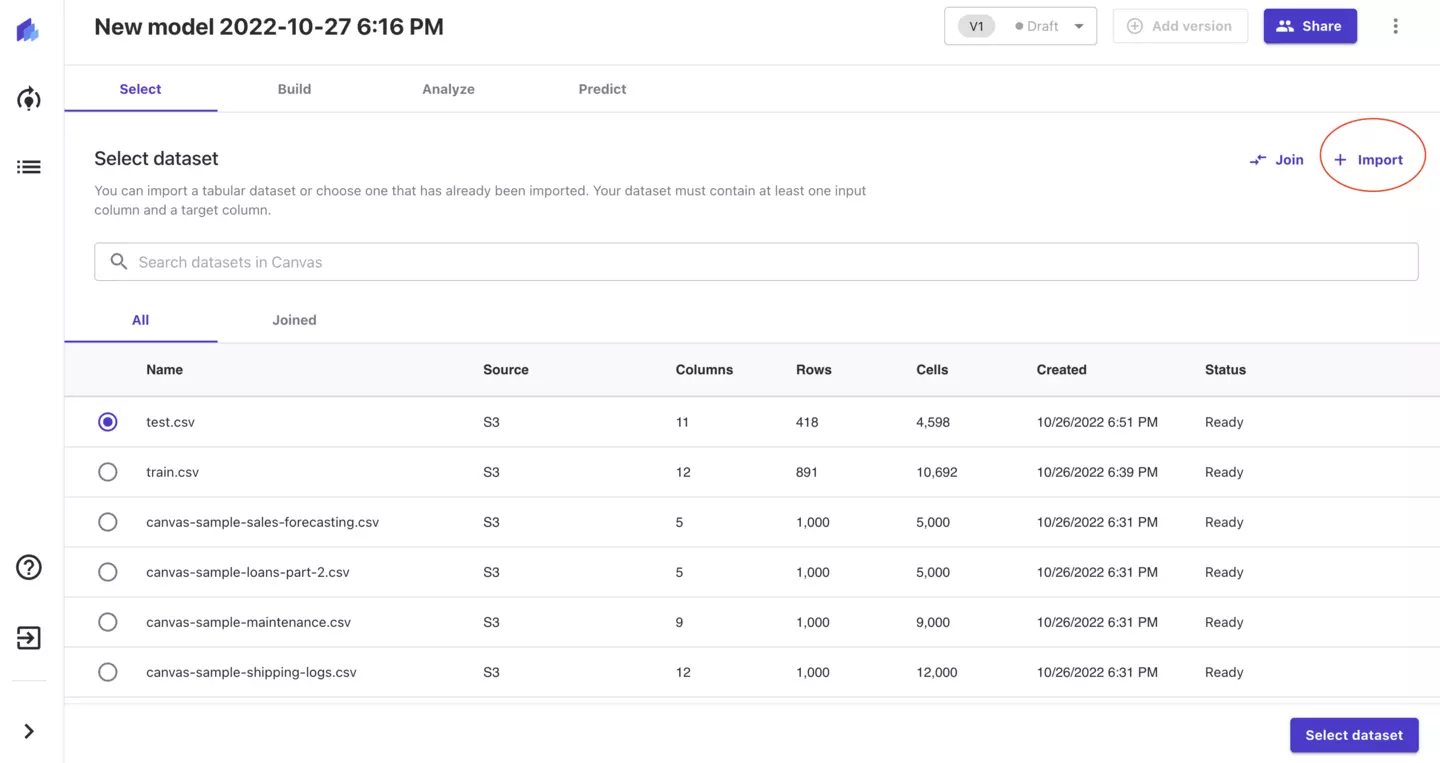
Import画面から先ほど作成したS3バケットを選択します。バケット内にはデータセットが入っています。
train.csvを選択し、「Import data」をクリックしてください。
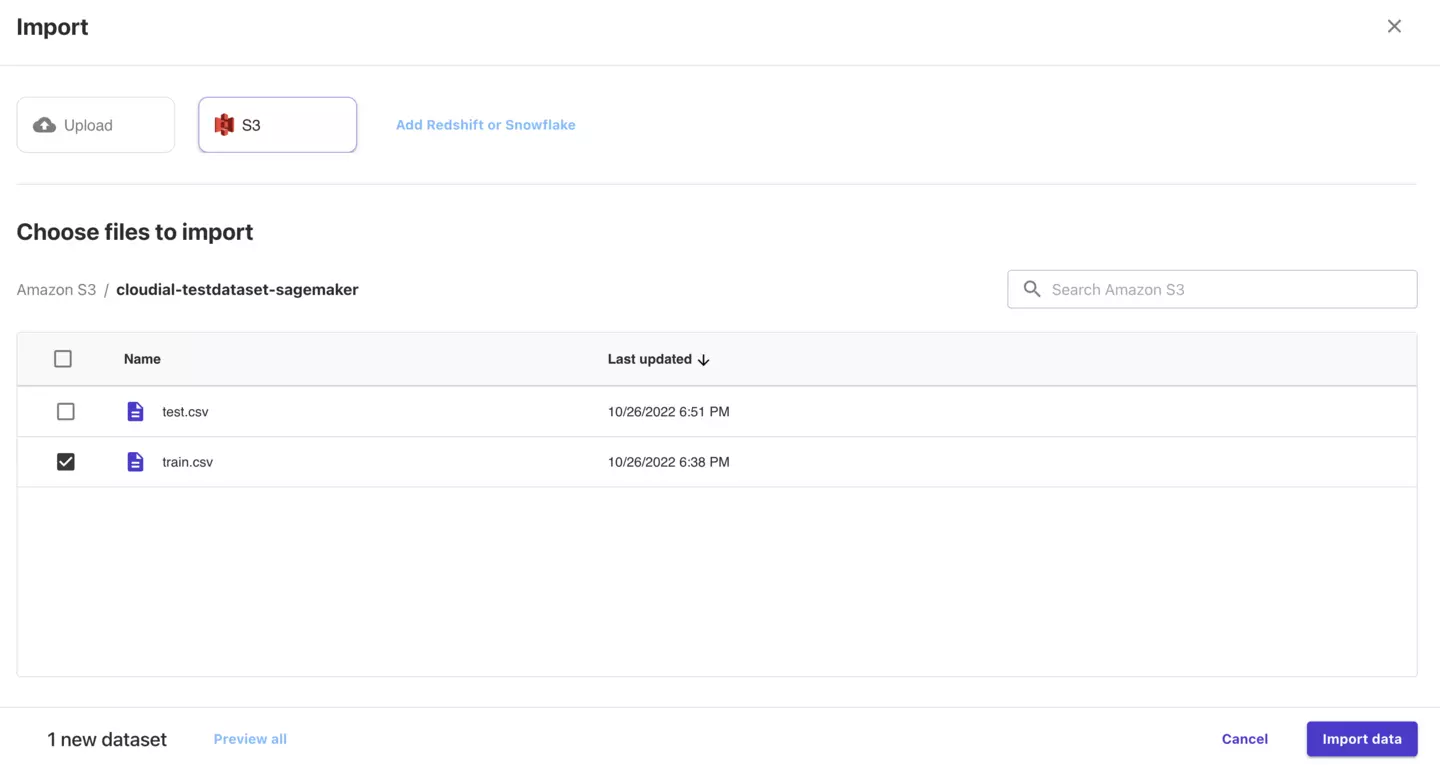
これでSageMaker Canvasにデータセットが登録されました。
test.csvも同様に登録しておいてください。
次はモデルの学習データとして先ほど設定したtrain.csvを使用するよう設定します。
test.csvを選択し、「Select dataset」をクリックしてください。
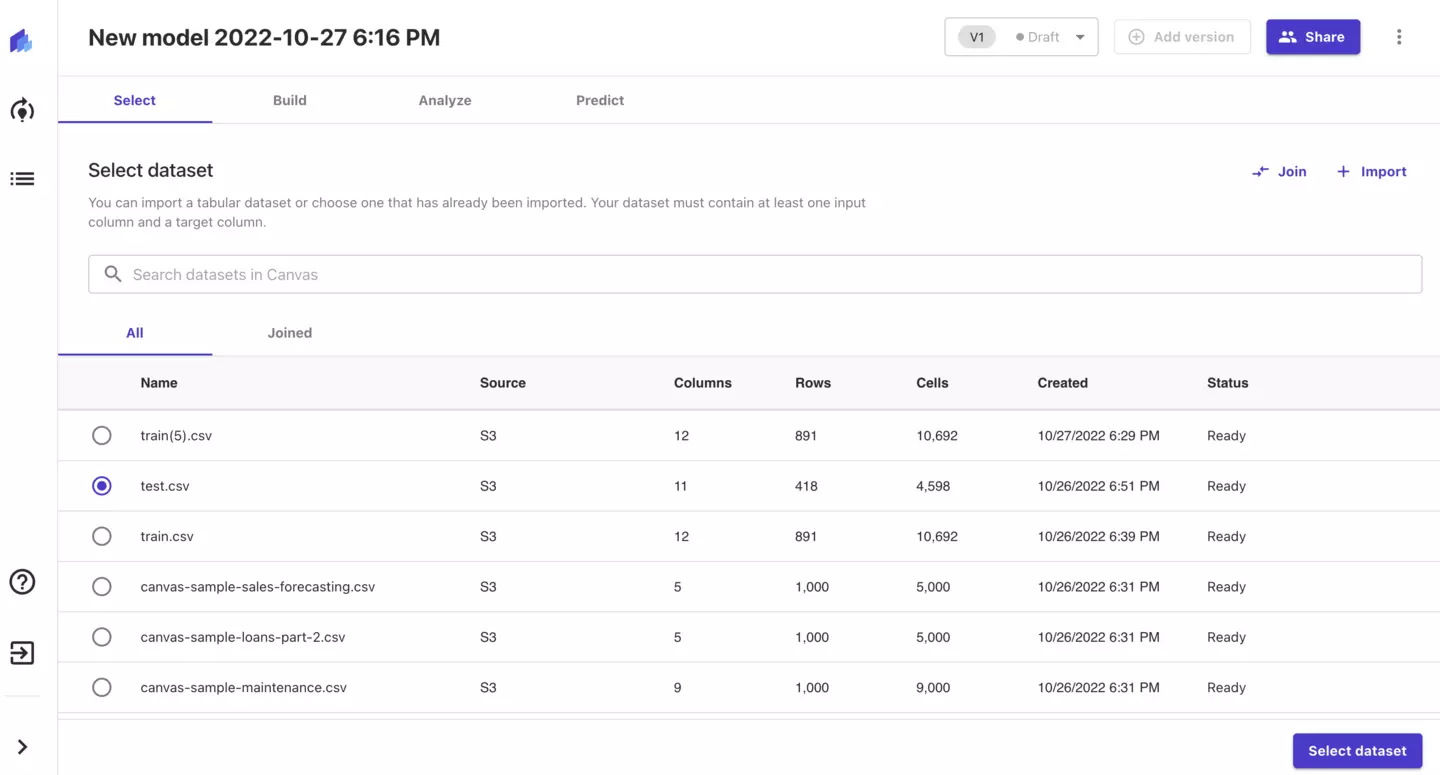
下記のように選択されたデータの情報が表示されます。
データの項目数・データ数ががどれだけあるか、また※データの欠損率までわかります。
※得られるデータは必ずしも完全なデータであるわけではありません。機械学習ではこれらの欠損したデータを適切に修正・保管する必要があります。
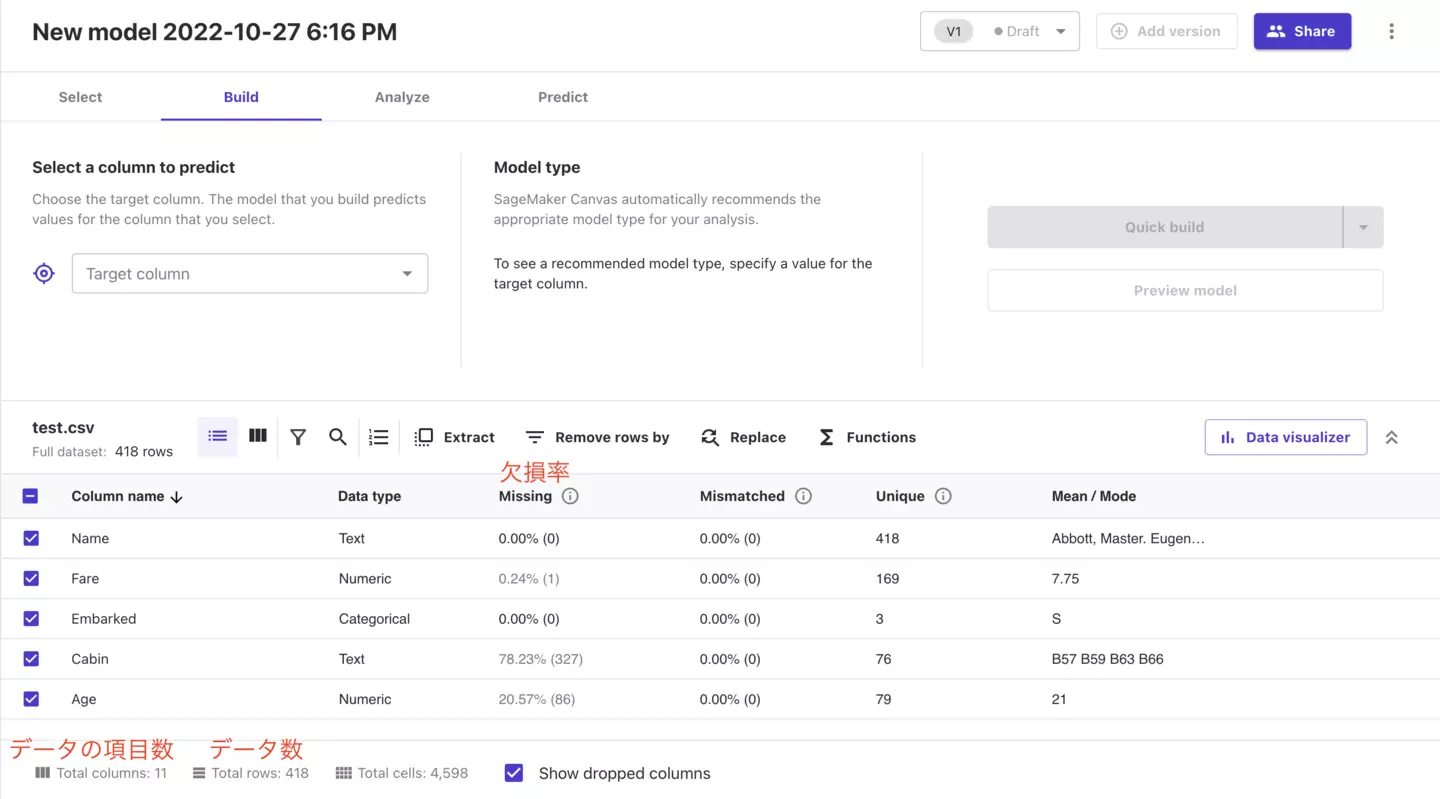
特に下記の赤丸部分を押下すると各種データがグラフ化されます。この時点である程度どのようなデータなのか見ることができます。
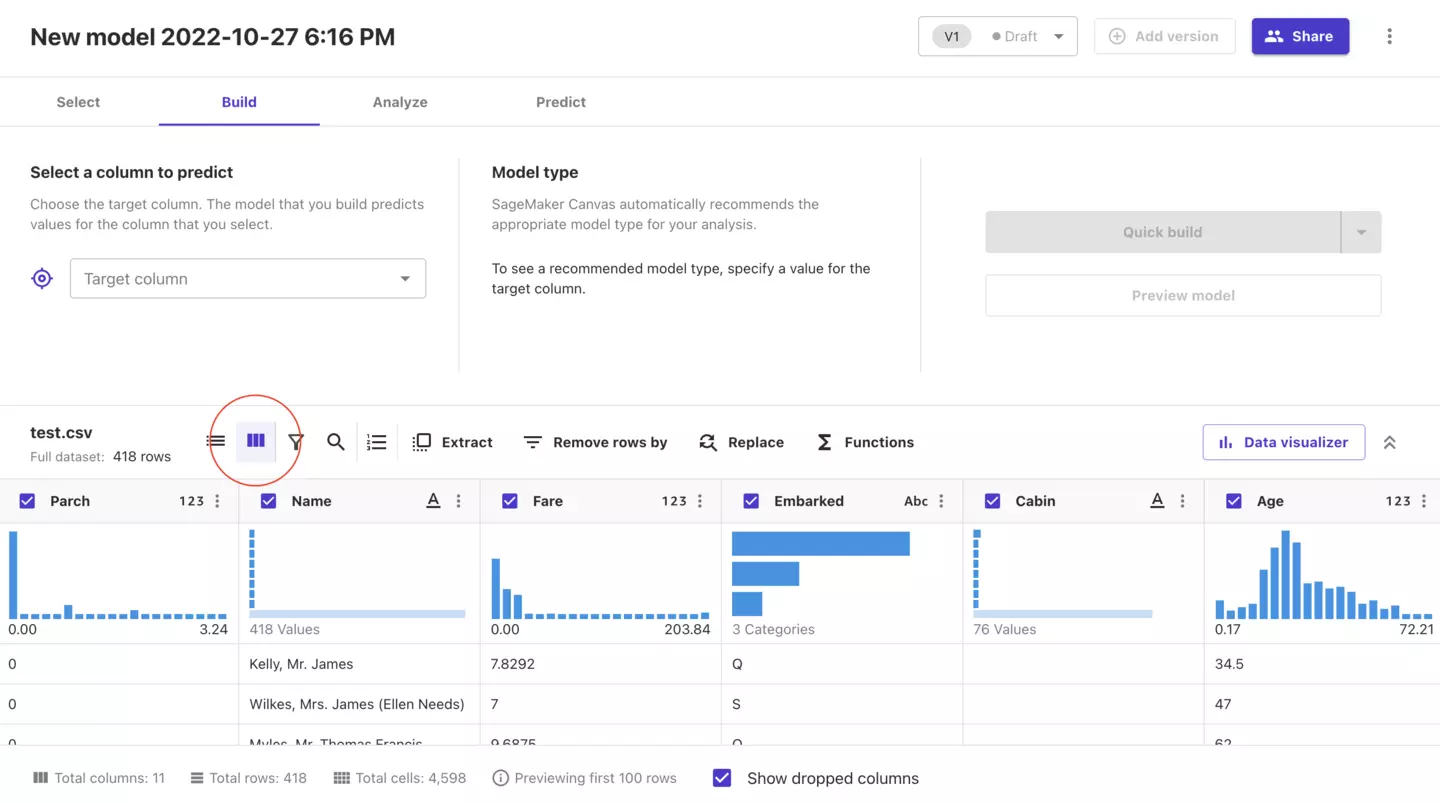
データのなかで今回の答えとなるカラムを選択しましょう。
Target columnの中からSurvivedを選択してください。
Target columnを選択すると、それぞれのカラムとTarget columnとの相関が表示されるようになります。
この時点である程度相関がなさそうなものに関しては学習対象から外してしまっても良いです。
今回は何も外さずに進めていきます。
4.モデルの学習
データが揃いましたので、モデルの学習を開始します。Quick buildの右側にある三角マークを押下すると
- Standard build:モデル作成をする。(実行時間が結構かかります。)
- Quick build:高速でモデル作成をする。(Standard buildを行う前のチェックとして使用します。)
が表示されますが、両方とも試してみてください。
今回の説明ではQuick buildを選択し、実行します。
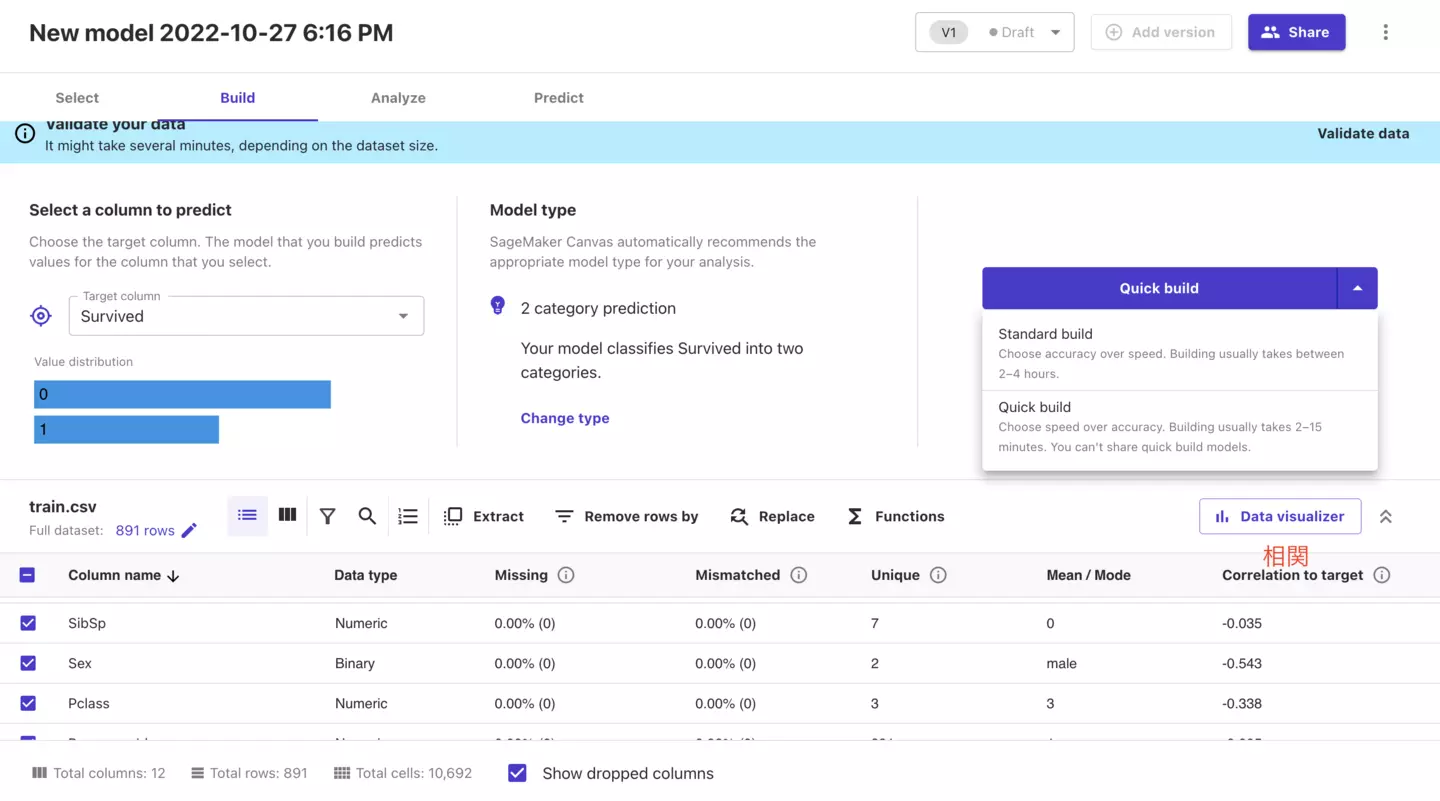
Quick buildは数分、Standard buildは数時間かかります。
モデルの学習が完了したら、下記のような画面に遷移します。
Quick buildでも学習時点での精度は82%と出ていますね!良いですね!
また、学習の中で重要視したカラムも左下にランキングで表示されるのですが、1番目に性別(Sex)が上がっているのも大変良いですね。
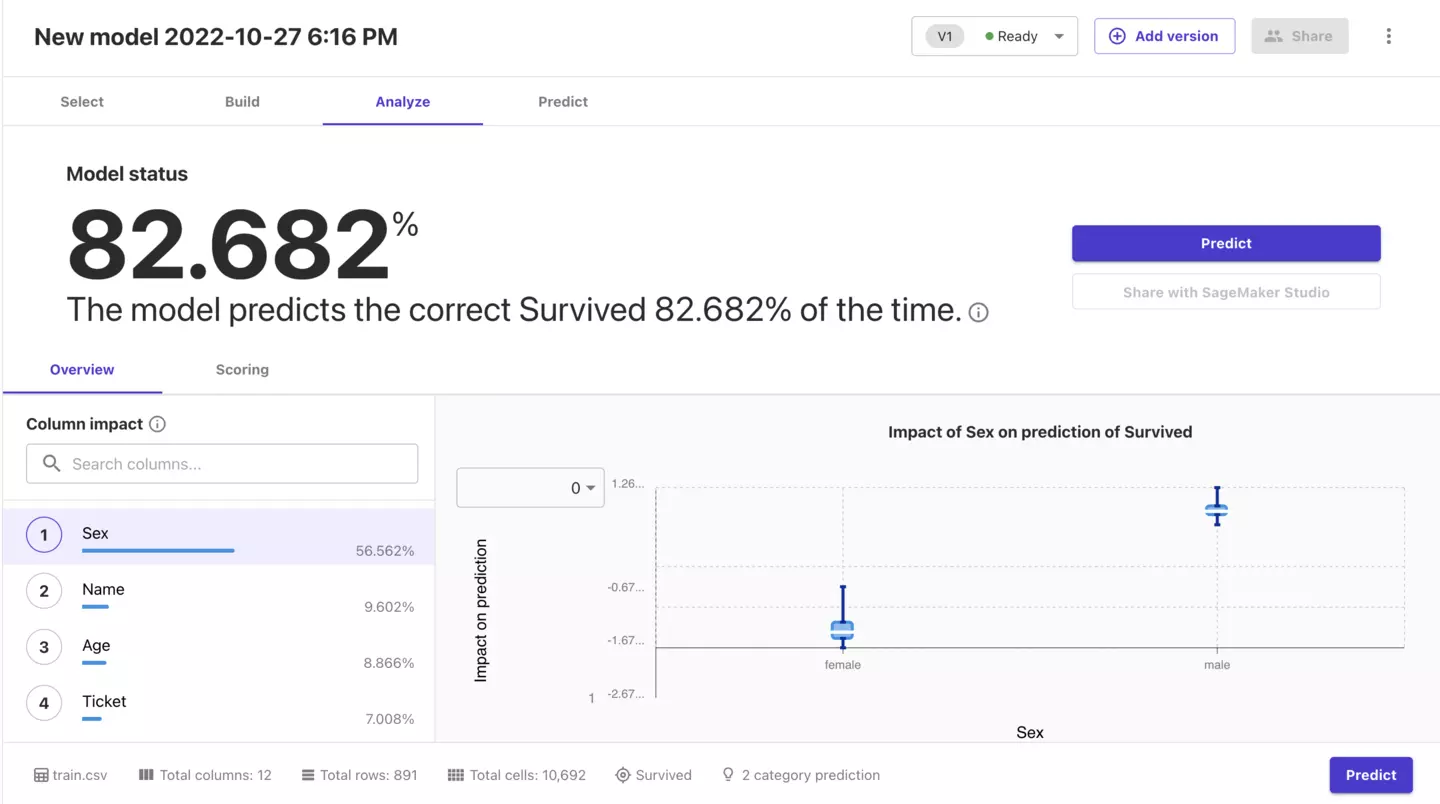
Standard buildで試した結果は下記のようになります。
さらにチケットのクラス(Pclass)もランキングトップに上がってきました。
タイタニックについて知っている人が重要だと挙げそうなカラムが上位に来ているのは驚愕です。
SageMaker Canvasにはデータしか与えていないにもかかわらず、これだけの結果が得られてしまうのはすごいですね。
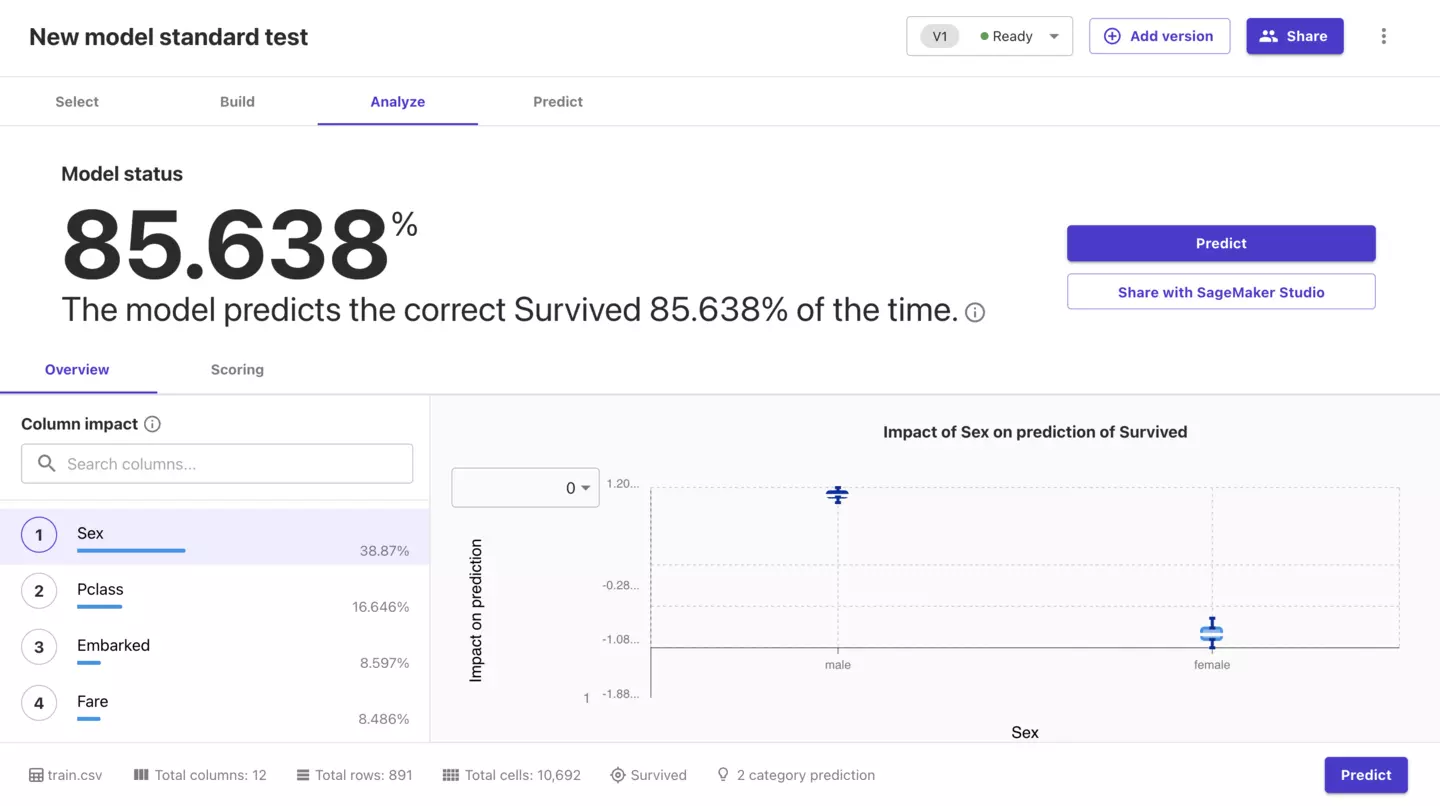
Scoringをクリックするとグラフで確認することができます。
正答率がどうなっているか視覚的にわかりやすいのはGoodですね!
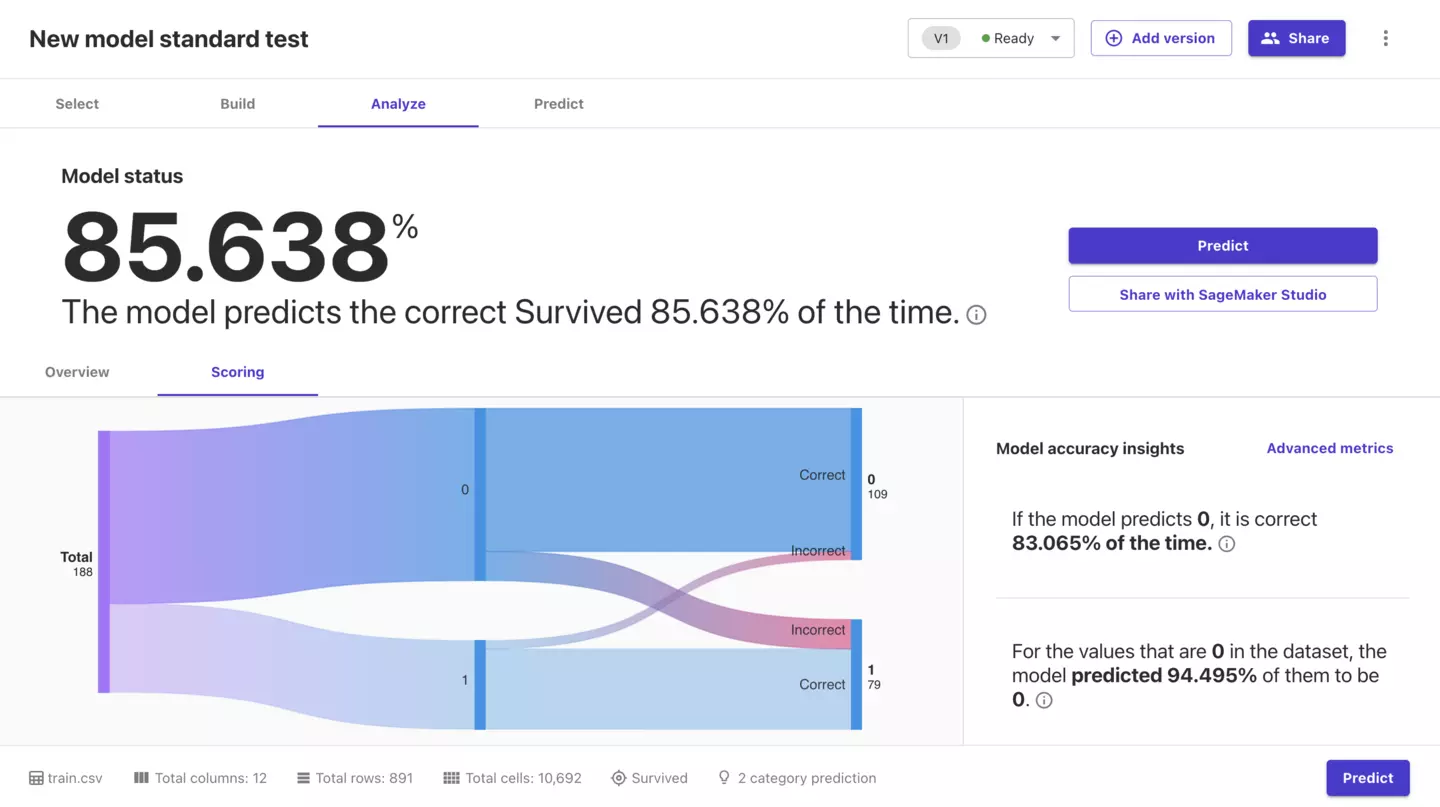
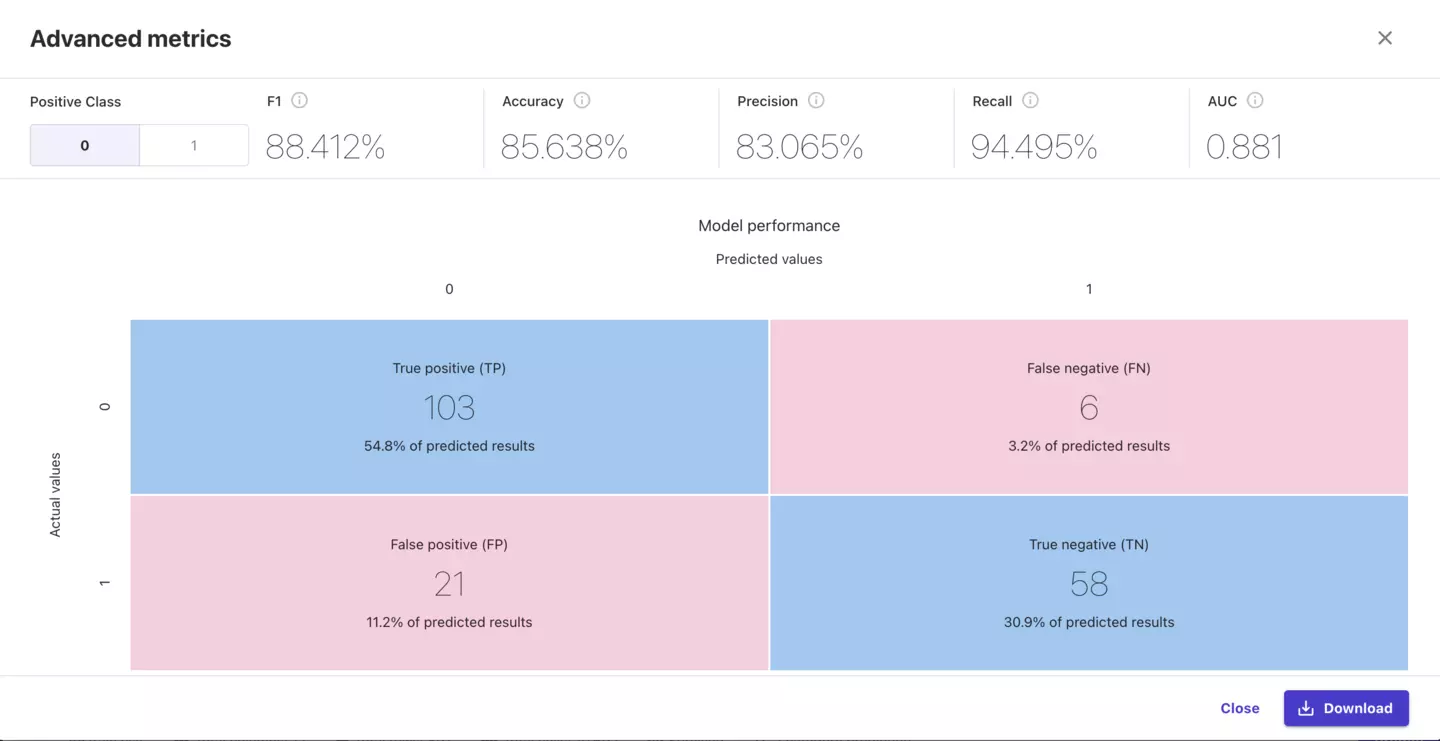
特にAdvanced metricsを押下すると下記のようにさらに詳細な情報を得ることができます。
F1値やAccuracyなどが一発で分かるのはほんとありがたいです。
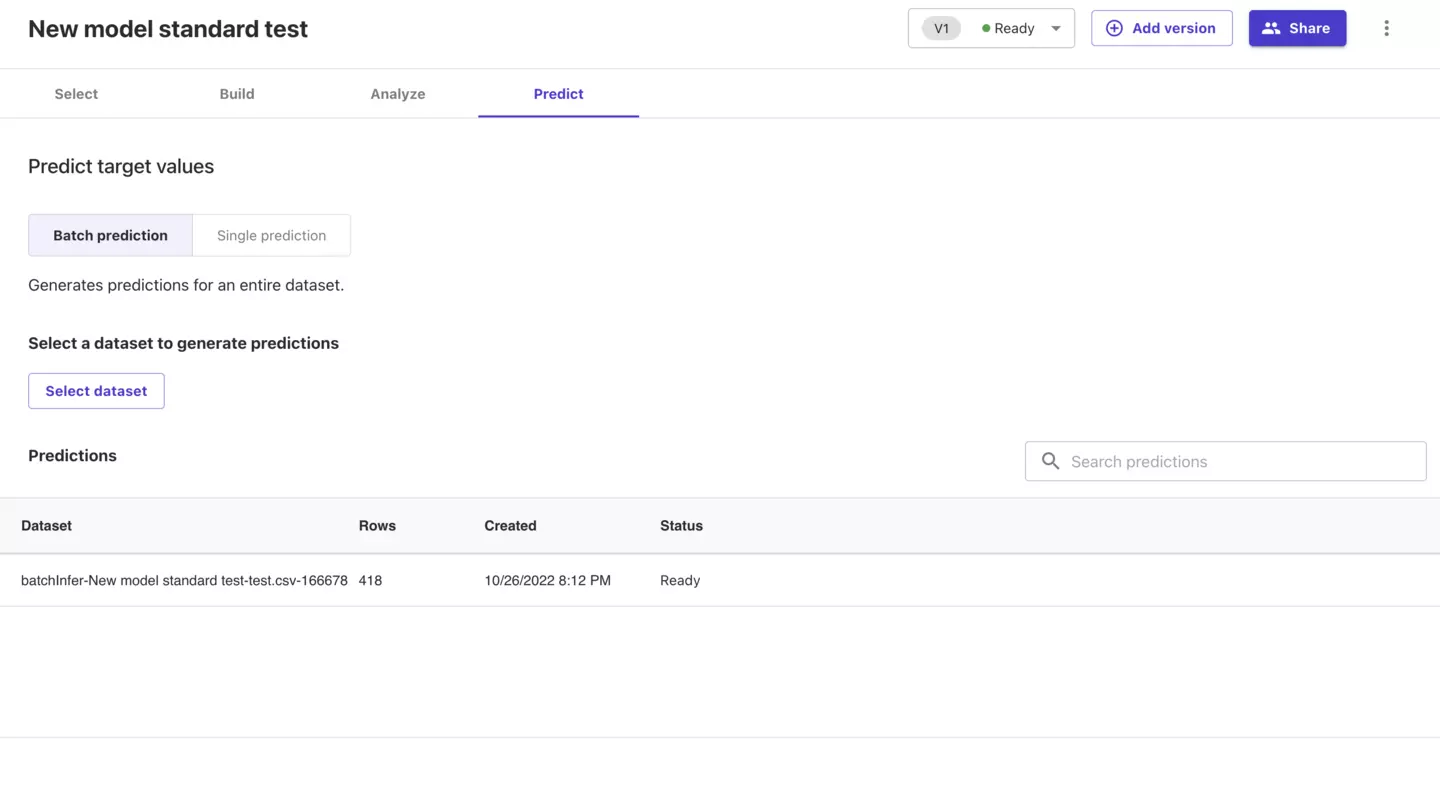
5.モデルの予測
最後にモデルによる予測を行います。
「Predict」をクリックすると下記画面に遷移します。
「Select dataset」をクリックしてください。
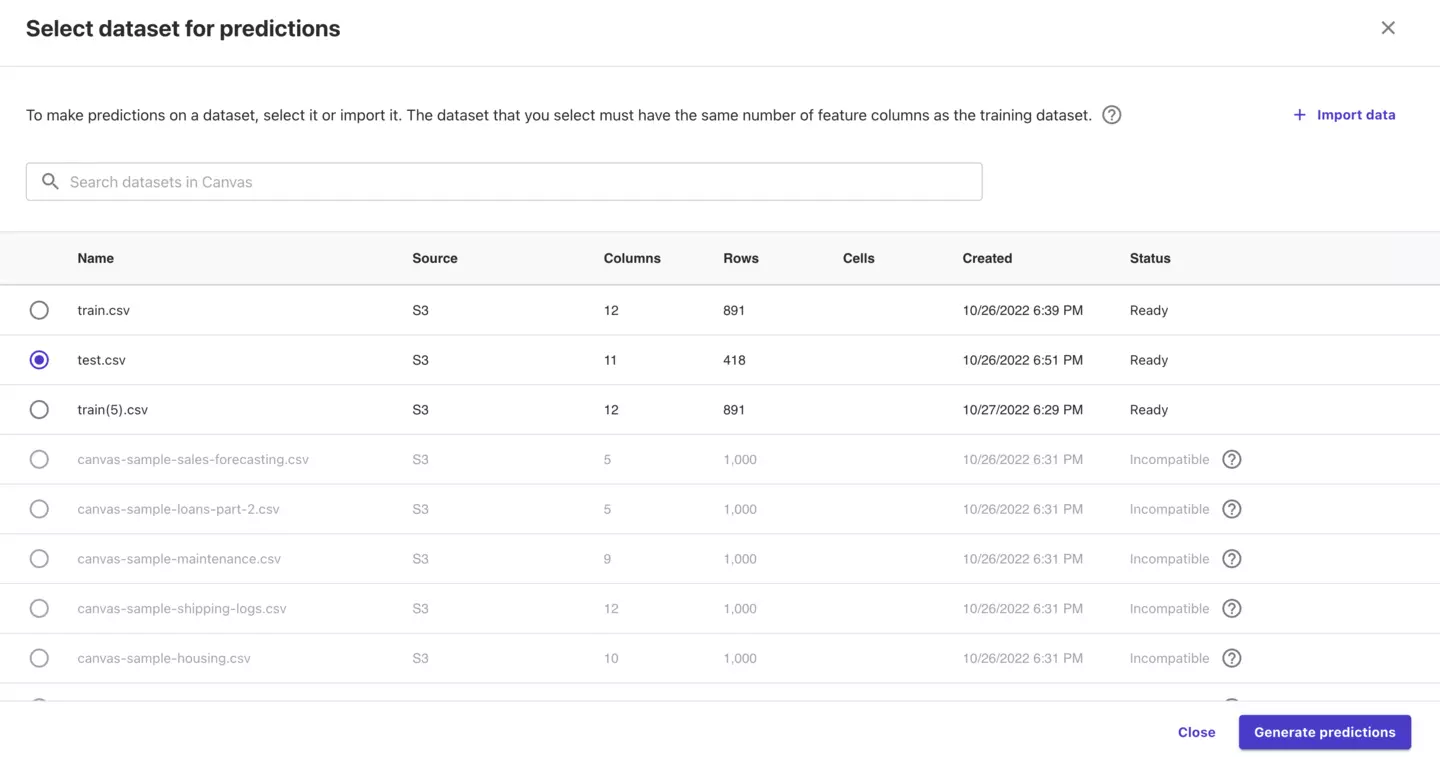
test.csvを選択し、「Generate predictions」をクリックすると予測が開始します。
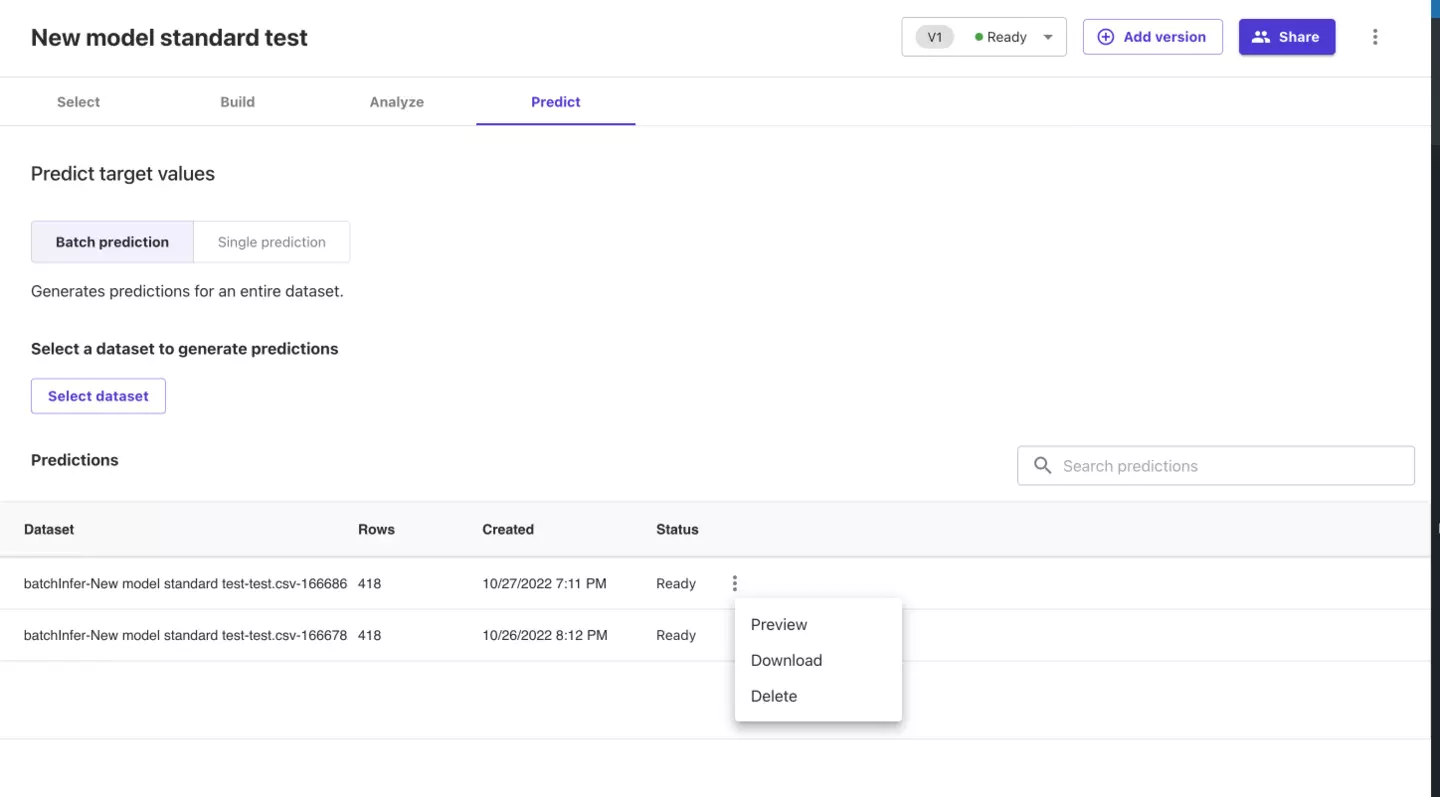
予測が完了するとStatusがReadyになります。
右側にある点を押下し、Downloadを選択してください。
予測結果のcsvデータが得られます。
これが機械学習において得たかったデータになりますね。
csvの中身は下記のようになっており、予測値(probability)と回答(今回はSurvived)が得られます。

さて、予測が得られたのでこの予測がどれだけ合っているか検証しましょう。
検証するためにはKaggleのタイタニックコンペティションのページより、予測結果をアップロードします。
アップロードした結果、下記のような結果になりました。
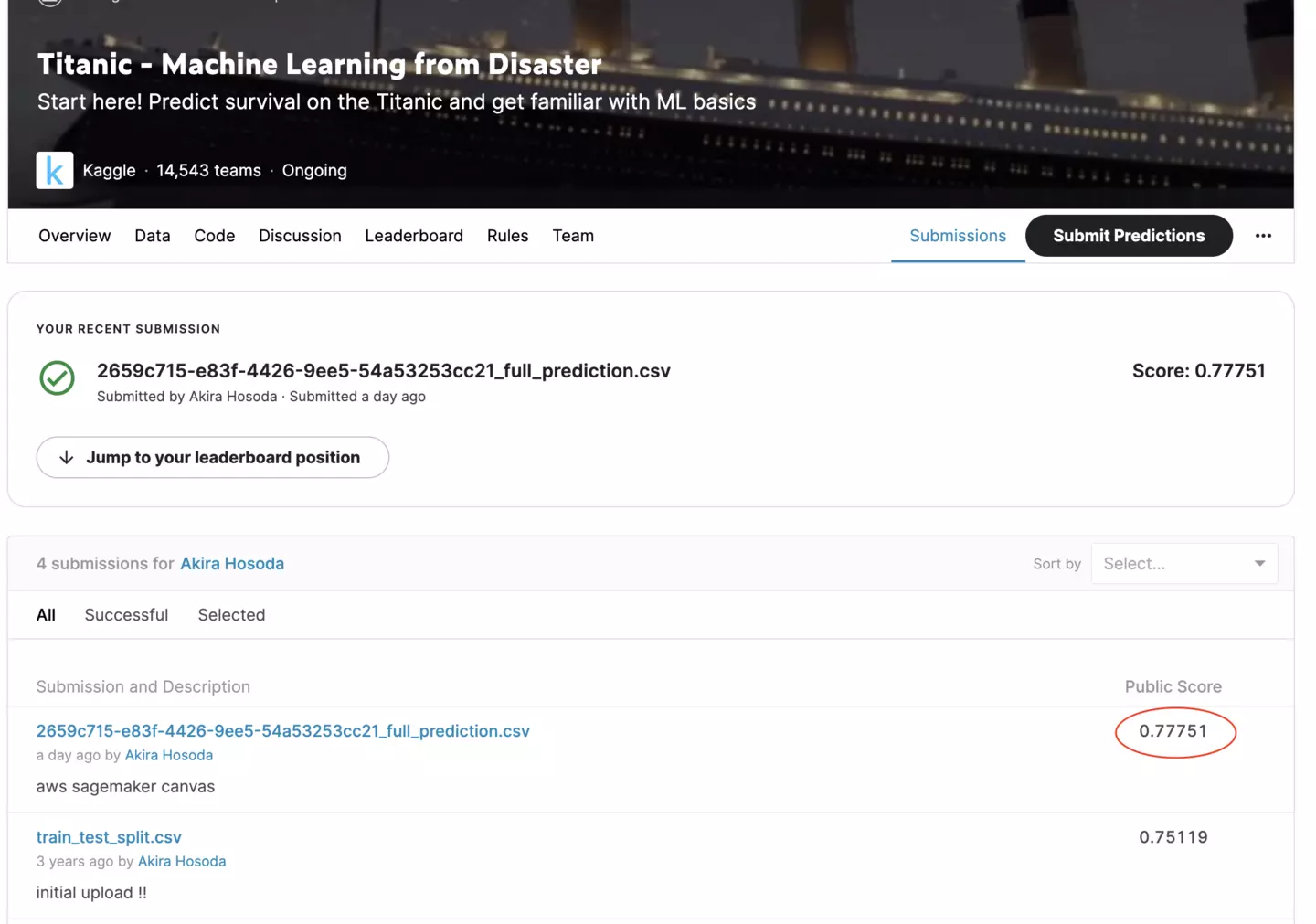
正答率は77%ですね。
以前チュートリアル通りに機械学習を進めた際の結果が75%だったので、ただ何もせずにSageMaker Canvasにデータを通すだけで、
チュートリアル以上の結果を得ることに成功してしまっています。いい性能していますね!
これにてSageMaker Canvasの使い方・検証は完了です。
まとめ
今回はSageMaker Canvasを使用し、機械学習を行えることができました。コードを一切描かず、グラフィカルな情報を得ることができ、予測精度が良いモデルを得ることができました。
機械学習の用途として利用せずとも、データの中で何が重要な情報なのか?などといった課題解決にも役立つと思います。また、作業に関してもとても簡単ですので、機械学習の案件があったらとりあえず、SageMaker Canvasに投げてしまうというのもありだと思います。
色々な使い方はあると思いますが、是非ともこのサービスの触り、パワーを感じてもらいたいです。機械学習の片鱗を触ることができ、とても刺激的な経験になるかと思います。
/assets/images/11166630/original/4e8ad505-ff70-4d46-81bf-8e76f61338d7?1668387329)
株式会社コムデからお誘い
この話題に共感したら、メンバーと話してみませんか?
【開発日誌#23】AWS SageMaker Canvasから始める機械学習




/assets/images/10103870/original/2ba56922-9e7c-4e02-bbaa-6811b67ad347?1660276798)