/assets/images/9254871/original/24e67d7f-0723-4fa9-bd00-255b86ba036e?1649813849)
/assets/images/7671243/original/7b866ced-da5b-4b72-baaa-042121dd07a1?1680836011)
株式会社バンダイナムコネクサスでは一緒に働く仲間を募集しています
バンダイナムコグループで対照学習による埋め込み表現を用いてレコメンド技術検証をした話

on 2022/04/07
【記事移行のおしらせ】
こちらの記事はバンダイナムコネクサスのTechBlogへ移行しました。
下記Linkよりご覧ください。
https://zenn.dev/bnx_techblog/articles/82bd5208f3e54c
こんにちは!
バンダイナムコネクサスのデータ戦略部で機械学習PJTのPdMをしている高野です。
データ戦略部内の機械学習チームでは、グループ内の様々なプロダクトに機械学習機能を提供するためにML基盤や機械学習モデルの開発を行っています。
そこで今回の記事では、機械学習モデル開発の一貫で実施した対照学習を用いたコンテンツベースレコメンドの技術検証について紹介します。
レコメンド技術検証の概要
下記図のように、似たアニメの推薦を実現するために、アニメのシリーズ関係とあらすじデータを用いたコンテンツベースレコメンドの技術検証を行いました。
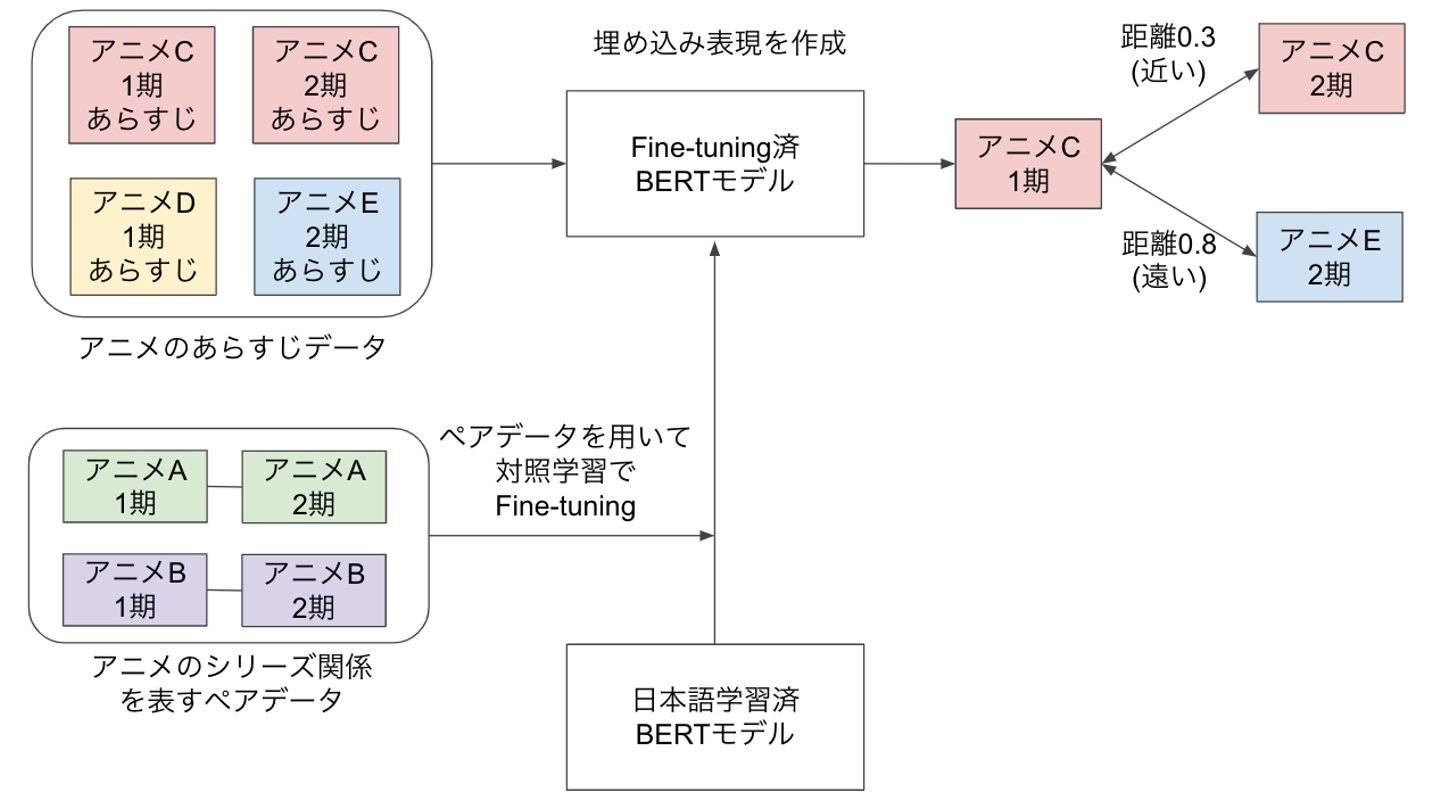
まずアニメのシリーズ関係ペアデータ(例:Aというアニメの1期、2期の関係性を表すペアデータ)をグループ内の動画プラットフォームサービスから取得します。
次にこのシリーズ関係ペアデータを用いて、東北大が提供している日本語学習済BERTモデルを対照学習でFine-tuningします。
このFine-tuning済みモデルを用いて、各アニメのあらすじデータから埋め込み表現を作成します。
この埋め込み表現の距離を計算し、距離が近いものを似たアニメと定義しました。
なぜレコメンド技術検証をしたのか?
技術検証を実施した理由は下記2つになります。
①進行中のレコメンドPJTにおけるコールドスタート問題の解決策として有効
②チーム内のエンジニアの技術チャレンジを後押ししたかった
チーム内の機械学習エンジニアがコールドスタート問題の解決方法として、コンテンツベースレコメンド手法を調べている際に下記の先行記事を見つけました。
本記事はこの手法を引用させていただいております。
「内容にもとづいたアニメ推薦のための Contrastive Learning による埋め込み作成」
https://kirarajump-tech.hatenablog.com/entry/2021/12/12/112218
そしてチーム内で上記記事について議論した結果、コールドスタート問題の解決策として有効そうだという結論になりました。
もちろん他にもコールドスタート問題の解決策はありましたが、チーム内エンジニアの「この技術の検証を行いたい」というモチベーションを重視して、対照学習を用いたコンテンツベースレコメンドの技術検証を行う事になりました。
レコメンド技術検証の詳細
検証観点
技術検証の観点は以下2つにしました。
・検証①:バンダイナムコグループが展開するIPのアニメ/映画に対して、近しい作品の推薦ができるか?
・検証②:対照学習でのFine-tuningを行う事で、より近い作品の推薦を実現できるか?
検証①の詳細
まず対照学習でのFine-tuning済みモデルを用いて、グループ内の動画プラットフォーム内のアニメ/映画のあらすじデータに対して埋め込み表現を生成しました。
その埋め込み表現をUMAPで次元を3次元まで削減し、そのユークリッド距離を作品同士の近さと定義しました。
このユークリッド距離を用いて、以下3つの検証を行いました。
①作品のジャンルが同じペアとジャンルが異なるペアの距離の分布
②同一視聴者の視聴作品ペアの距離平均の分布
③ジャンルごとに色分けした3次元MAP
①作品のジャンルが同じペアとジャンルが異なるペアの距離の分布
まず作品のジャンル(例:アクション。ラブコメ)が同じものであれば距離が近いという仮定から、ジャンルが同じ作品ペアとジャンルが異なる作品ペアのユークリッド距離のヒストグラムを調べました。
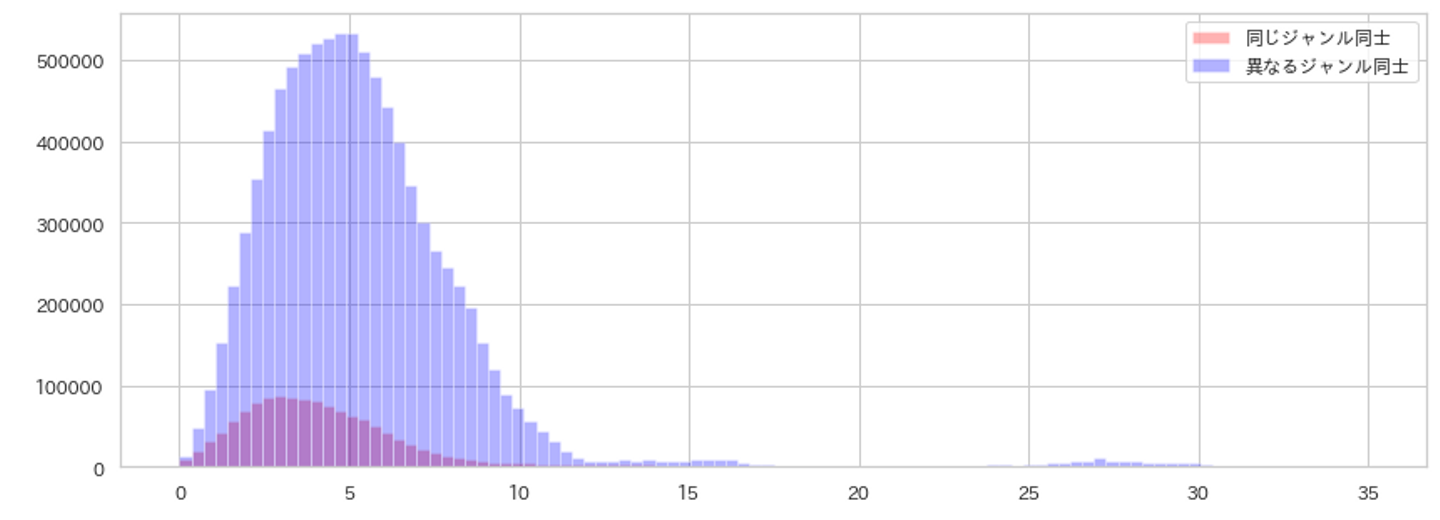
ヒストグラムのボリュームゾーンを比較すると、同じジャンル同士のアニメの距離の方が、異なるジャンル同士のアニメの距離より近い事がわかります。
・同じジャンル同士の中央値: 3.816
・違うジャンル同士の中央値: 4.930
この事から、似た内容のアニメ同士の方が、作品同士の距離が近くなるように埋め込み表現を生成できていると言えます。
②同一視聴者の視聴作品ペアの距離平均の分布
動画プラットフォームの視聴ログから同一視聴者の視聴作品同士のペアの埋め込み表現の距離を計測し、視聴者ごとに平均してヒストグラムを作成しました。
ただし、下記については除外しました。
・100以上の作品を見ているユーザ
・同一作品の視聴(例:作品Aの1話と2話)
・同一シリーズ(例:同じIPに関するシリーズもの)
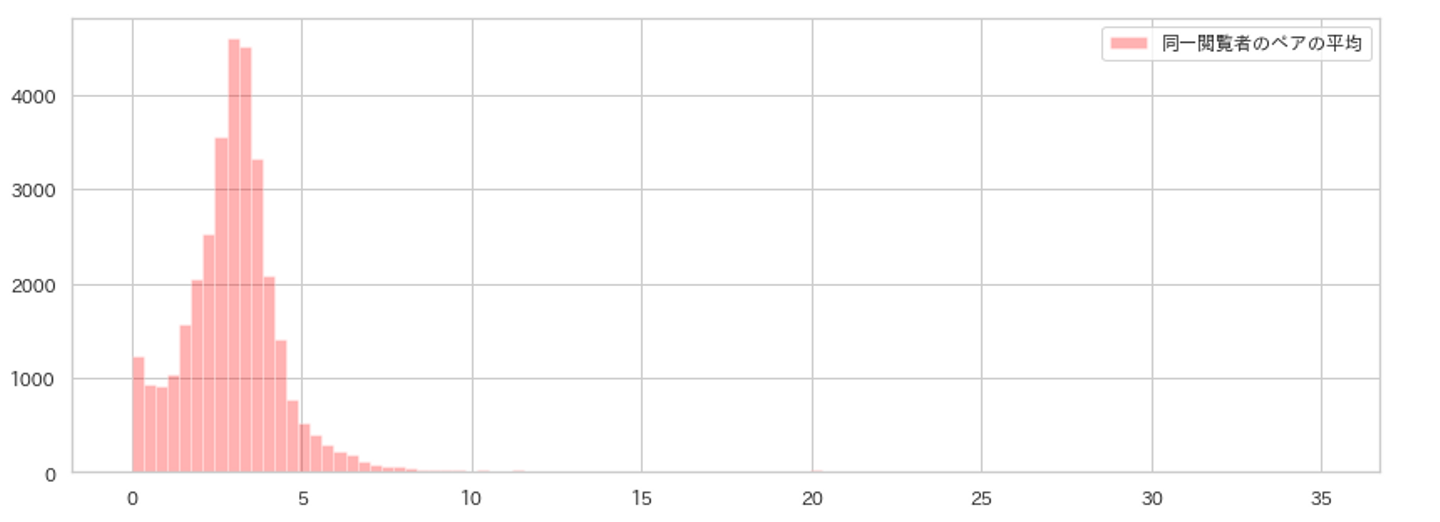
ヒストグラムからボリュームゾーンが3.0前後であり、中央値は2.99と同一ジャンル同士の距離の中央値よりも小さい事がわかりました。
この事から視聴者は埋め込み表現の距離が近いアニメを実際に視聴していたことが分かりました。
③ジャンルごとに色分けした3次元MAP
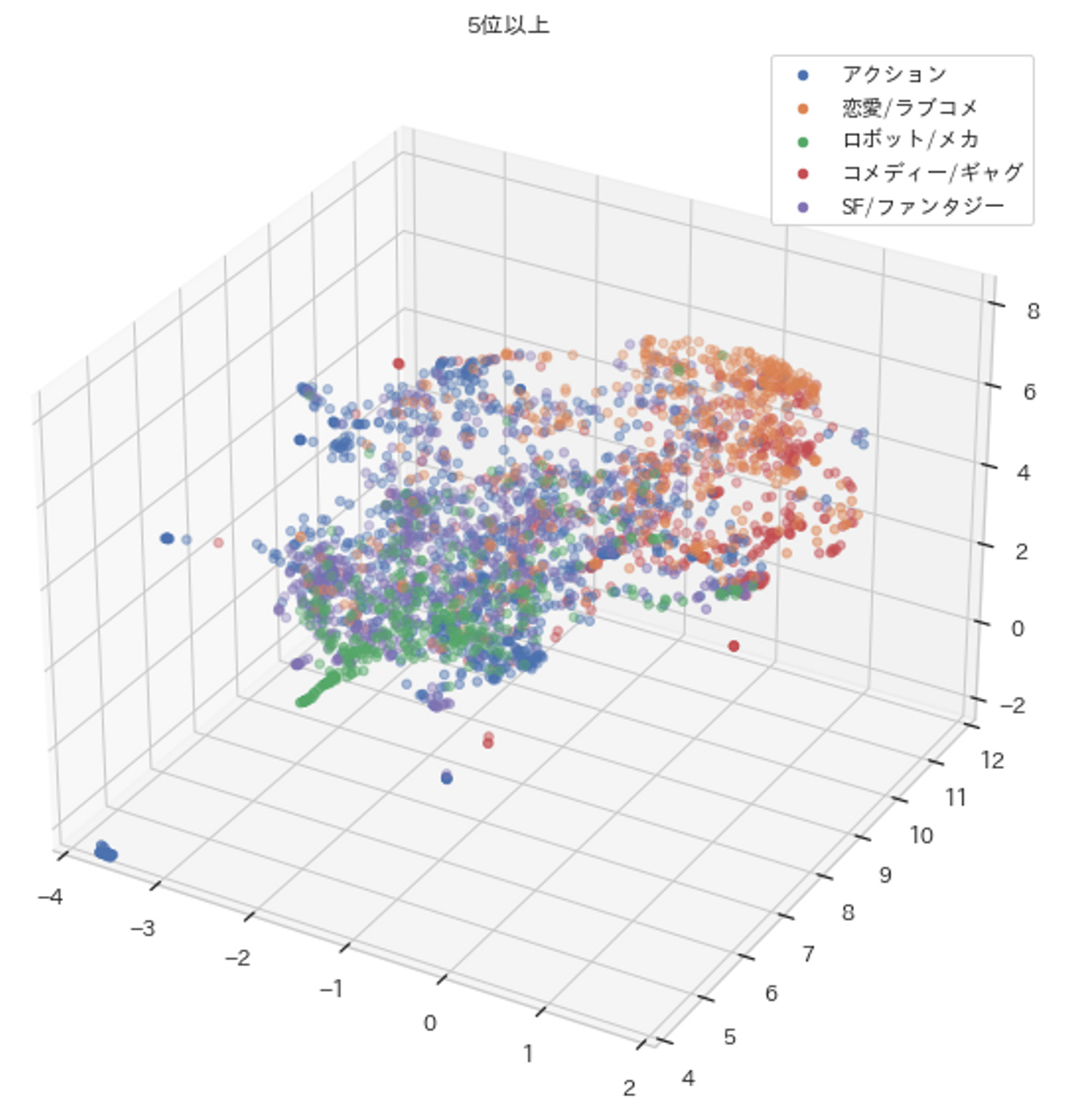
ジャンルごとに色分けした3次元MAPを作成しました。
ただし、全ジャンルを表示すると色が混ざって見にくくなるため、作品数の数が多いTop5のジャンル(以下Top5)とそれ以外のジャンル(以下6位以下)に分けて作成しました。
まず下記の5位以上のMAPから、右上に恋愛/ラブコメ(オレンジ色) 、左下にロボット/メカ(緑色)が集中しているなど、ジャンルごとに近い距離となっている事がわかります。
次に下記の6位以下のMapからも、右上にスポーツ/レース(紫色)、その下にドラマ/青春(赤色)が集中しているなど、ジャンルごとに近い距離となっている事がわかります。
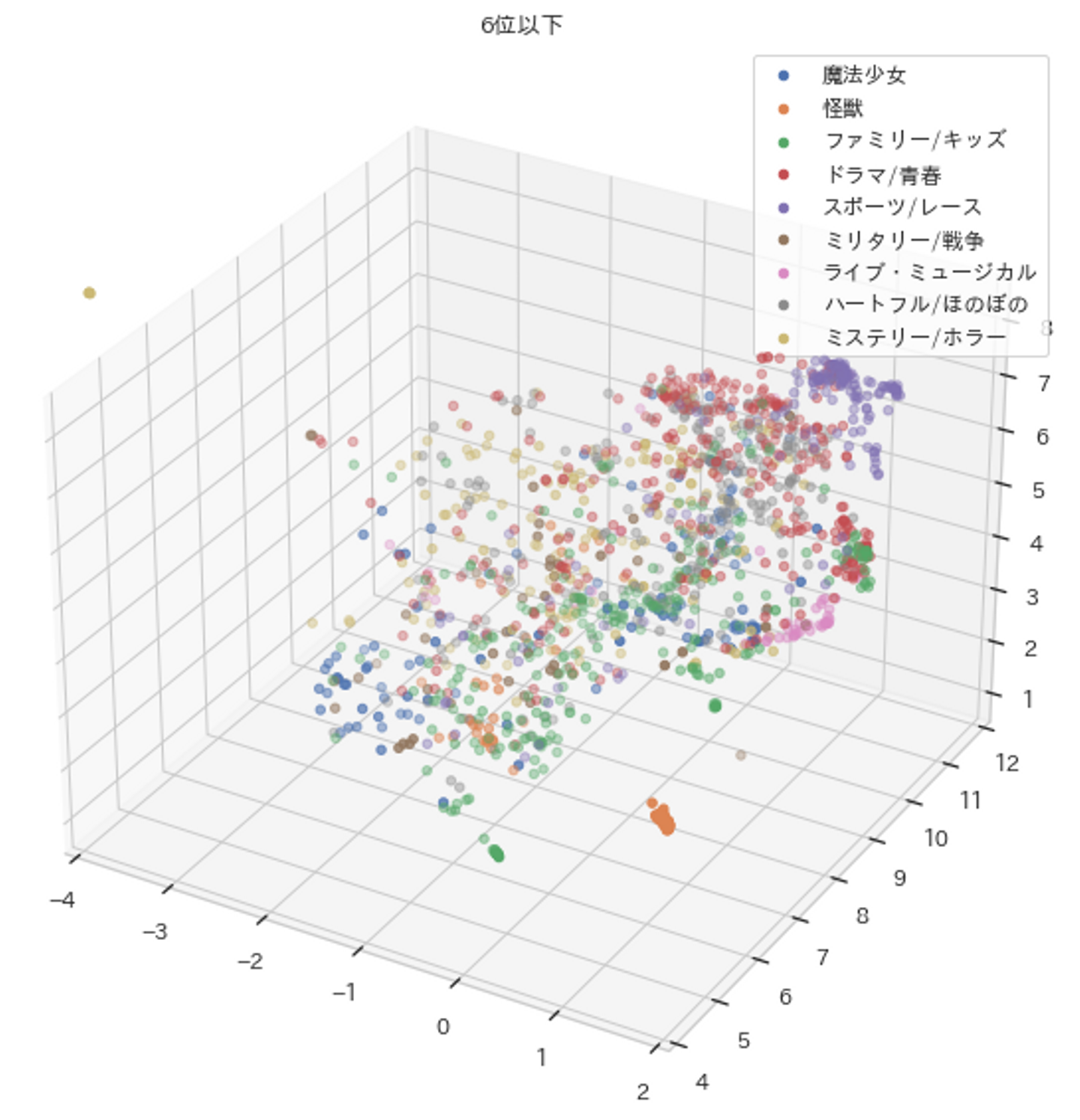
これらの結果から、同一ジャンルの作品の距離は近くなる傾向がある事がわかりました。
検証②の詳細
対照学習を用いたFine-tuningの有効性を確認するため、Fine-tuningしていないBERTのモデルを使用して埋め込み表現を生成し、以下2つの検証を行いました。
①Fine-tuning有無による作品ペアの距離の分布の違い
②Fine-tuning有無による3次元MAPの違い
①Fine-tuning有無による作品ペアの距離の分布の違い
まずFine-tuningなしの場合のジャンルが同じペアとジャンルが異なるペアの距離の分布は下記図のようになります。
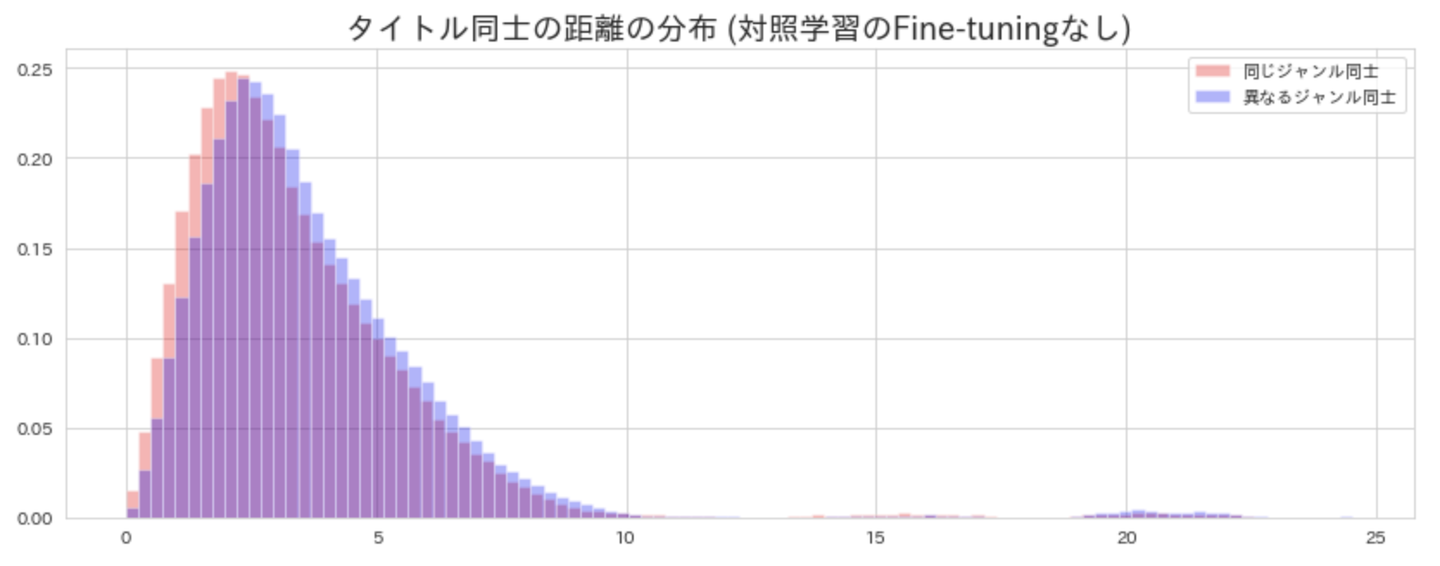
この分布から、同じジャンル同士と異なるジャンル同士の距離の中央値の差が小さい、つまり同じジャンルと異なるジャンルを上手く分離できてない事がわかります。
次にFine-tuningありの場合のジャンルが同じペアとジャンルが異なるペアの距離の分布は下記図のようになります。
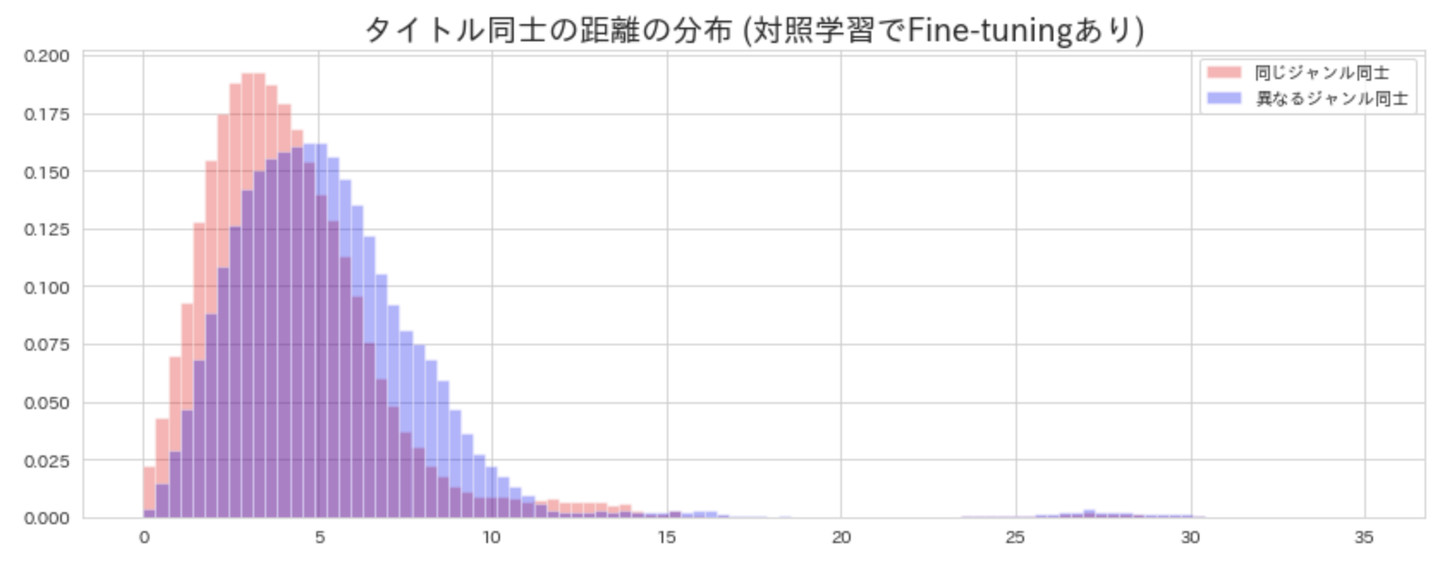
この図から、同じジャンル同士と異なるジャンル同士の距離の中央値の差が大きい、つまり同じジャンルと異なるジャンルを上手く分離できている事がわかります。
②Fine-tuning有無による3次元MAPの違い
まず作品数の数が多いTop5のジャンル(5位以上)において、Fine-tuning有無の違いを検証しました。
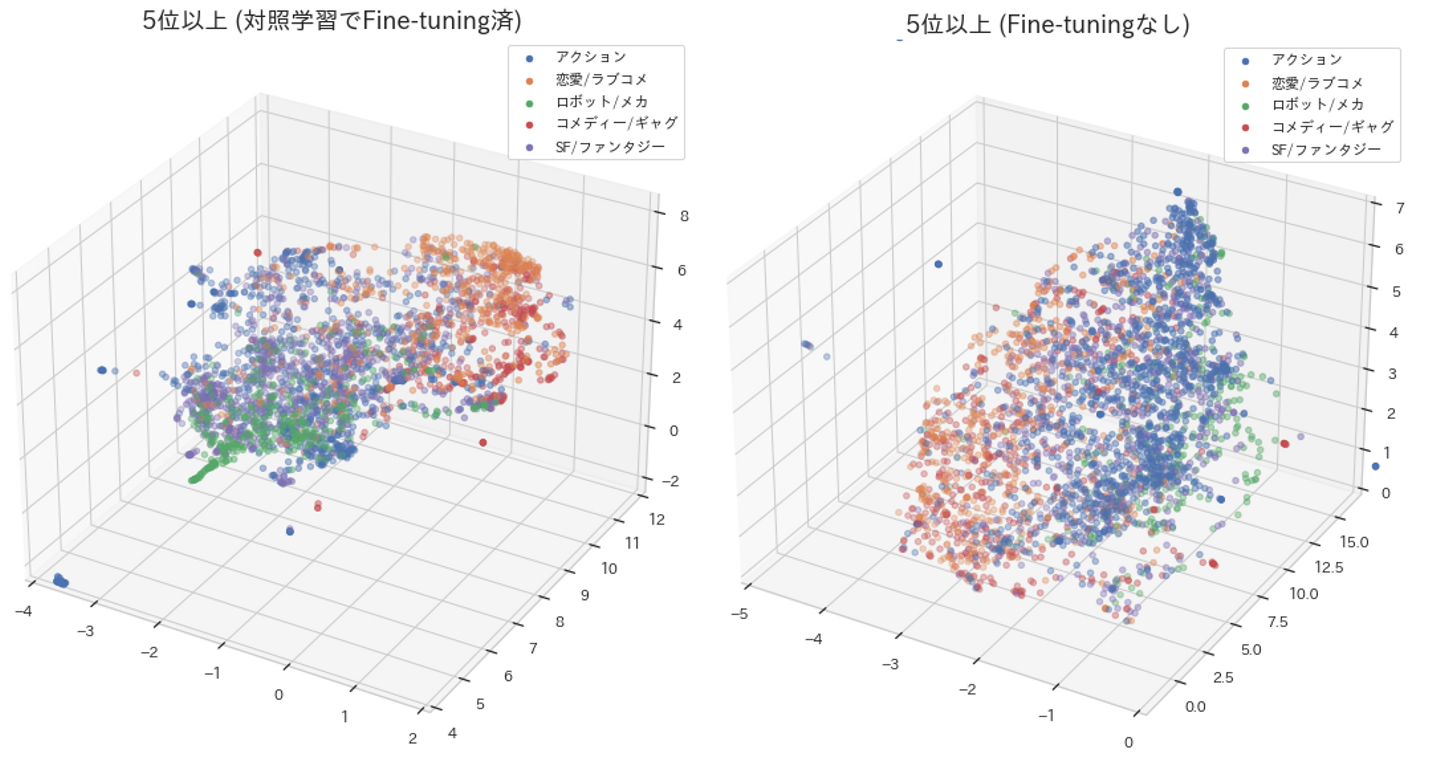
Fine-tuningなしのMapでは、アクション(青色)と恋愛/ラブコメ(オレンジ)のジャンルが混在する範囲が広い事がわかります。
一方Fine-tuning済のMapでは、ロボット/メカ(緑色)がまとまって存在している事がわかります。
次にそれ以外のジャンル(6位以下)において、Fine-Tuning有無の違いを検証しました。
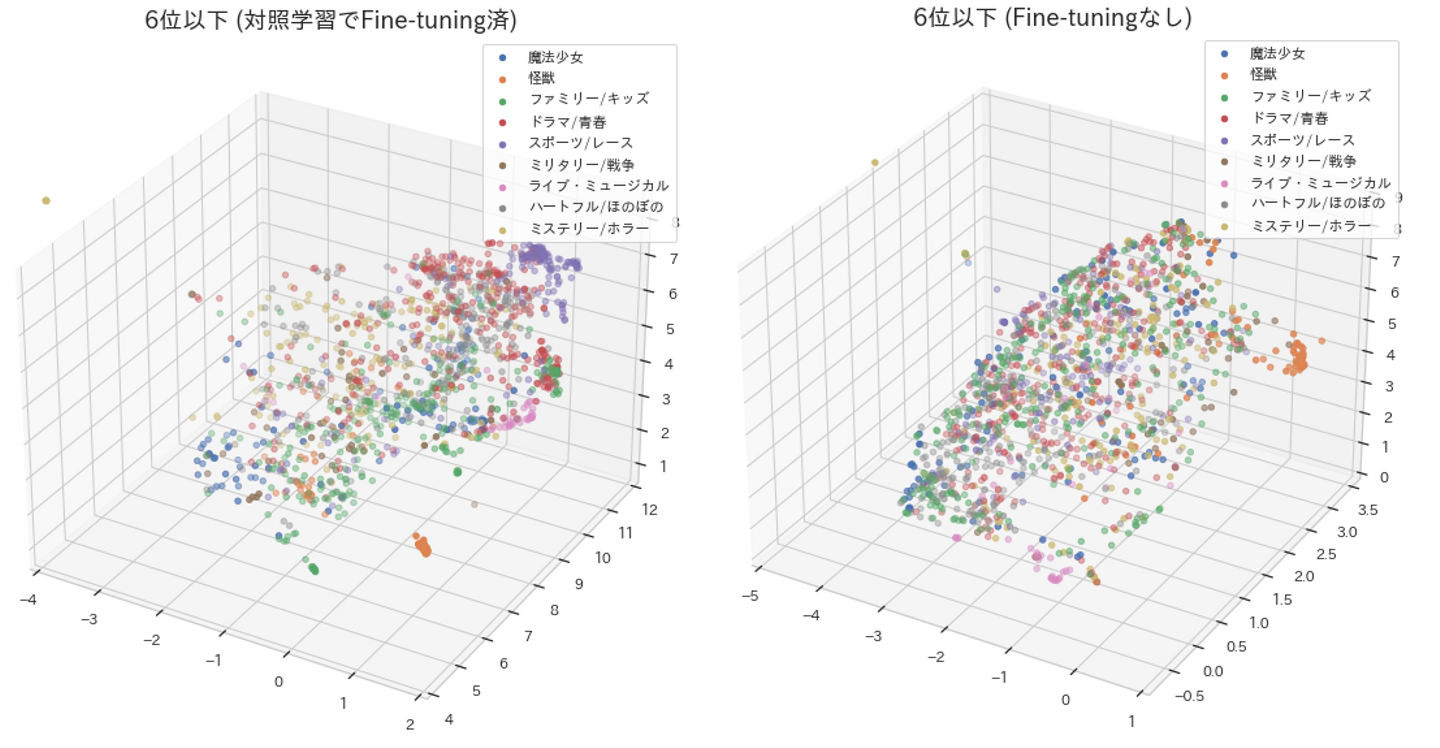
Fine-tuning済のMapでは、スポーツ/レース(紫色)や ドラマ/青春(赤色)の塊が右上に見られます。
一方Fine-tuningなしのMapでは、ジャンルごとの塊はほぼ見られない形になっています。
検証の結論
以上の内容を踏まえると、検証①と②の結論は以下になります。

今後の展望
最後に対照学習を用いたコンテンツベースレコメンドを今後どのように展開していくかを紹介します。
今後の展開としては、グループ内の下記サービスへのレコメンド機能提供時に、今回検証したレコメンド手法を適用していく想定です。
・ニュースアプリ(あるIPに関するニュースを提供するアプリ)
・ECサイト
・動画プラットフォーム
またさらに先の展望としては、教師有り学習の一般的手法と今回検証した手法を組み合わせたモデル開発に挑戦しつつ、ML Opsエンジニアと協業し、複合させたモデルを取り扱うためのML基盤の進化にも着手していきます。
さいごに
レコメンド技術検証の紹介は以上になります。
今回紹介したレコメンド技術検証以外にも様々な機械学習モデル開発を実施していますので、少しでも興味を持って頂けたら気軽に話を聞きに来て下さい!
バンダイナムコグループで対照学習による埋め込み表現を用いてレコメンド技術検証をした話

/assets/images/9254871/original/24e67d7f-0723-4fa9-bd00-255b86ba036e?1649813849)




/assets/images/13122158/original/24e67d7f-0723-4fa9-bd00-255b86ba036e?1682487997)
