/assets/images/4901651/original/9de972b3-d882-4d9c-b24b-93fff9219963?1586959280)
株式会社AppBrewでは一緒に働く仲間を募集しています
- 広告セールス
- フロントエンドエンジニア
- インフルエンサー
- 他19件の職種
- 開発
- ビジネス
- その他
https://speakerdeck.com/jiko21/array-grouping-will-soon-be-arriving-at-typescript
を掘り下げたものです。
配列やObject内の要素をgroupingするために追加されたmethodです。
2023年にtc39にてstage 4になり、現在最新版のブラウザ等では対応がされています。
MDNにて簡単な例が紹介されています。
以下はMDNの例を参考に機能を網羅するために複雑なcallback関数を用いた例です。
const fieldMembers= [
{id: 1, name: 'user1', position: 'left fielder'},
{id: 2, name: 'user3', position: 'second baseman'},
{id: 3, name: 'user3', position: 'third baseman'},
{id: 4, name: 'user4', position: 'center fielder'},
{id: 5, name: 'user5', position: 'designated hitter'},
{id: 6, name: 'user6', position: 'shortstop'},
{id: 7, name: 'user7', position: 'first baseman'},
{id: 8, name: 'user8', position: 'right fielder'},
{id: 9, name: 'user9', position: 'catcher'},
];
const result = Object.groupBy(fieldMembers, (item) => {
if (item.position.contains('fielder')) {
return 'outfielder';
}
if (item.position === 'catcher' || item.position === 'designated hitter') {
return item.position;
}
return 'infielder'
})
console.log(result)
// {
// "outfielder": [
// {
// "id": 1,
// "name": "user1",
// "position": "left fielder"
// },
// {
// "id": 4,
// "name": "user4",
// "position": "center fielder"
// },
// {
// "id": 8,
// "name": "user8",
// "position": "right fielder"
// }
// ],
// "infielder": [
// {
// "id": 2,
// "name": "user3",
// "position": "second baseman"
// },
// {
// "id": 3,
// "name": "user3",
// "position": "third baseman"
// },
// {
// "id": 6,
// "name": "user6",
// "position": "shortstop"
// },
// {
// "id": 7,
// "name": "user7",
// "position": "first baseman"
// }
// ],
// "designated hitter": [
// {
// "id": 5,
// "name": "user5",
// "position": "designated hitter"
// }
// ],
// "catcher": [
// {
// "id": 9,
// "name": "user9",
// "position": "catcher"
// }
// ]
// }
const fieldMembers= [
{id: 1, name: 'user1', position: 'left fielder'},
{id: 2, name: 'user3', position: 'second baseman'},
{id: 3, name: 'user3', position: 'third baseman'},
{id: 4, name: 'user4', position: 'center fielder'},
{id: 5, name: 'user5', position: 'designated hitter'},
{id: 6, name: 'user6', position: 'shortstop'},
{id: 7, name: 'user7', position: 'first baseman'},
{id: 8, name: 'user8', position: 'right fielder'},
{id: 9, name: 'user9', position: 'catcher'},
];
const result = Object.groupBy(fieldMembers, (item) => {
if (item.position.contains('fielder')) {
return 'outfielder';
}
if (item.position === 'catcher' || item.position === 'designated hitter') {
return item.position;
}
return 'infielder'
})
console.log(result)
// {
// "outfielder": [
// {
// "id": 1,
// "name": "user1",
// "position": "left fielder"
// },
// {
// "id": 4,
// "name": "user4",
// "position": "center fielder"
// },
// {
// "id": 8,
// "name": "user8",
// "position": "right fielder"
// }
// ],
// "infielder": [
// {
// "id": 2,
// "name": "user3",
// "position": "second baseman"
// },
// {
// "id": 3,
// "name": "user3",
// "position": "third baseman"
// },
// {
// "id": 6,
// "name": "user6",
// "position": "shortstop"
// },
// {
// "id": 7,
// "name": "user7",
// "position": "first baseman"
// }
// ],
// "designated hitter": [
// {
// "id": 5,
// "name": "user5",
// "position": "designated hitter"
// }
// ],
// "catcher": [
// {
// "id": 9,
// "name": "user9",
// "position": "catcher"
// }
// ]
// }
groupByの第一引数にgroupingしたい配列を、第二引数にgroupingするためのkeyを計算するcallback関数をとります。第二引数の関数は各要素に対して呼び出され、第一引数に要素、第二引数にその要素が入っているindexをとります。
Objectと同様にMapにもArray Grouping Methodが生えており、そちらを利用するとMapとしてGroupingされたものが返ってきます。
このようなmethodはinstanceに対して直接呼び出したいと思いますが以下の理由でstatic methodとなっていることがproposalで書かれています。
Array.proptotype.groupByが使われており影響が大きいgroupという名前も検討したが、それもそれであらゆる場所ですでに使われており、バグに気づいて報告するのが難しい実際に新しいmethodが追加されたので従来の自力実装と比較してみます。
groupBy相当の挙動を試すべく、Array.foreachとArray.reduceを使って実装してみました。
const map = {}
inputArray.forEach((item) => {
const key = item % 2 === 0 ? 'even' : 'odd'
if (map.hasOwnProperty(item)) {
// @ts-ignore
map[key].push(item);
} else {
// @ts-ignore
map[key] = [item];
}
});
const map = {}
inputArray.forEach((item) => {
const key = item % 2 === 0 ? 'even' : 'odd'
if (map.hasOwnProperty(item)) {
// @ts-ignore
map[key].push(item);
} else {
// @ts-ignore
map[key] = [item];
}
});
特にひねりはなく、loopを回しつつmapに対して
しているだけです。
inputArray.reduce((prevValue, currentValue) => {
const key = currentValue % 2 === 0 ? 'even' : 'odd'
if (prevValue.hasOwnProperty(key)) {
// @ts-ignore
prevValue[key].push(currentValue);
} else {
// @ts-ignore
prevValue[key] = [currentValue];
}
return prevValue;
}, {}
);
inputArray.reduce((prevValue, currentValue) => {
const key = currentValue % 2 === 0 ? 'even' : 'odd'
if (prevValue.hasOwnProperty(key)) {
// @ts-ignore
prevValue[key].push(currentValue);
} else {
// @ts-ignore
prevValue[key] = [currentValue];
}
return prevValue;
}, {}
);
先程の実装とやっている中身は同じですが、reduceでコンパクトに纏めたものです。
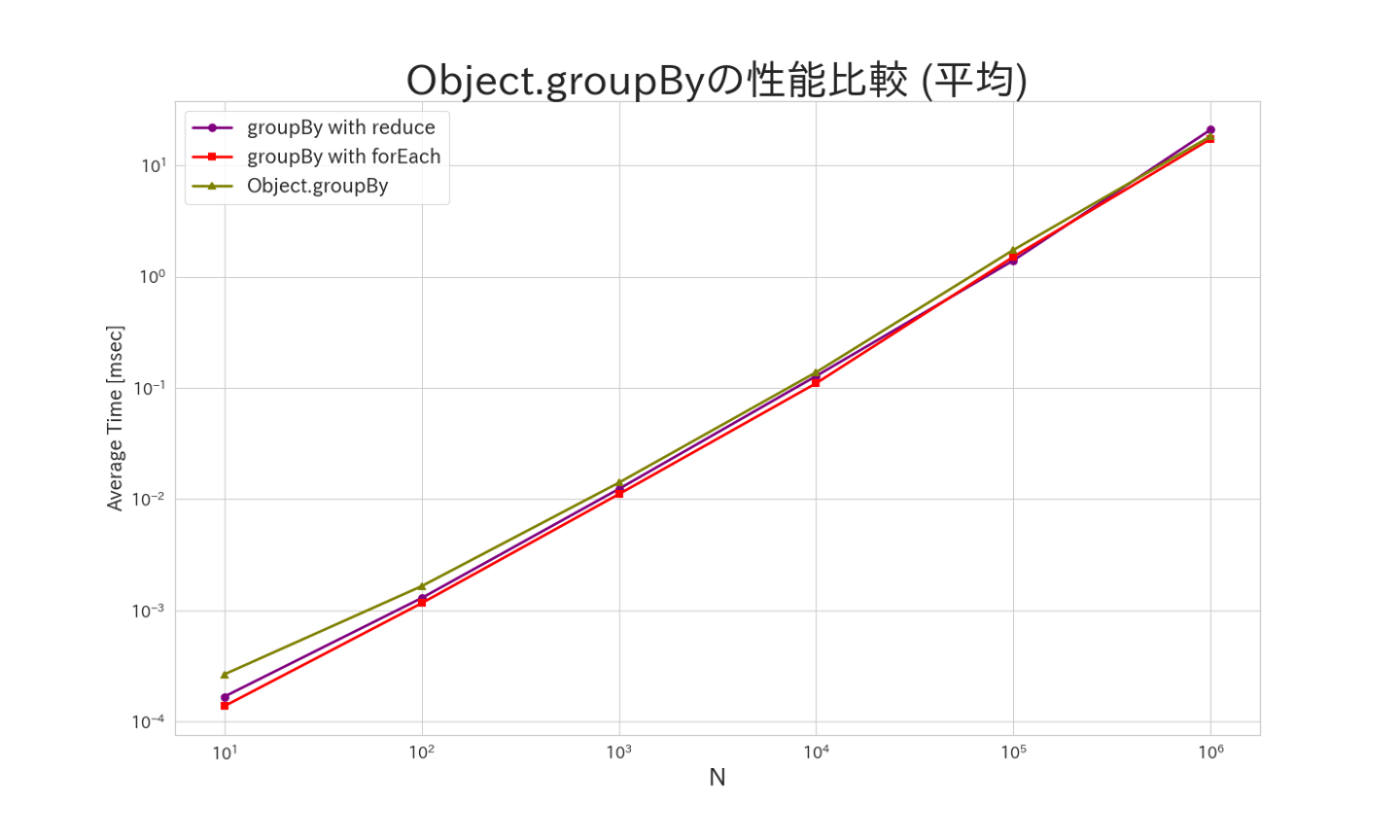
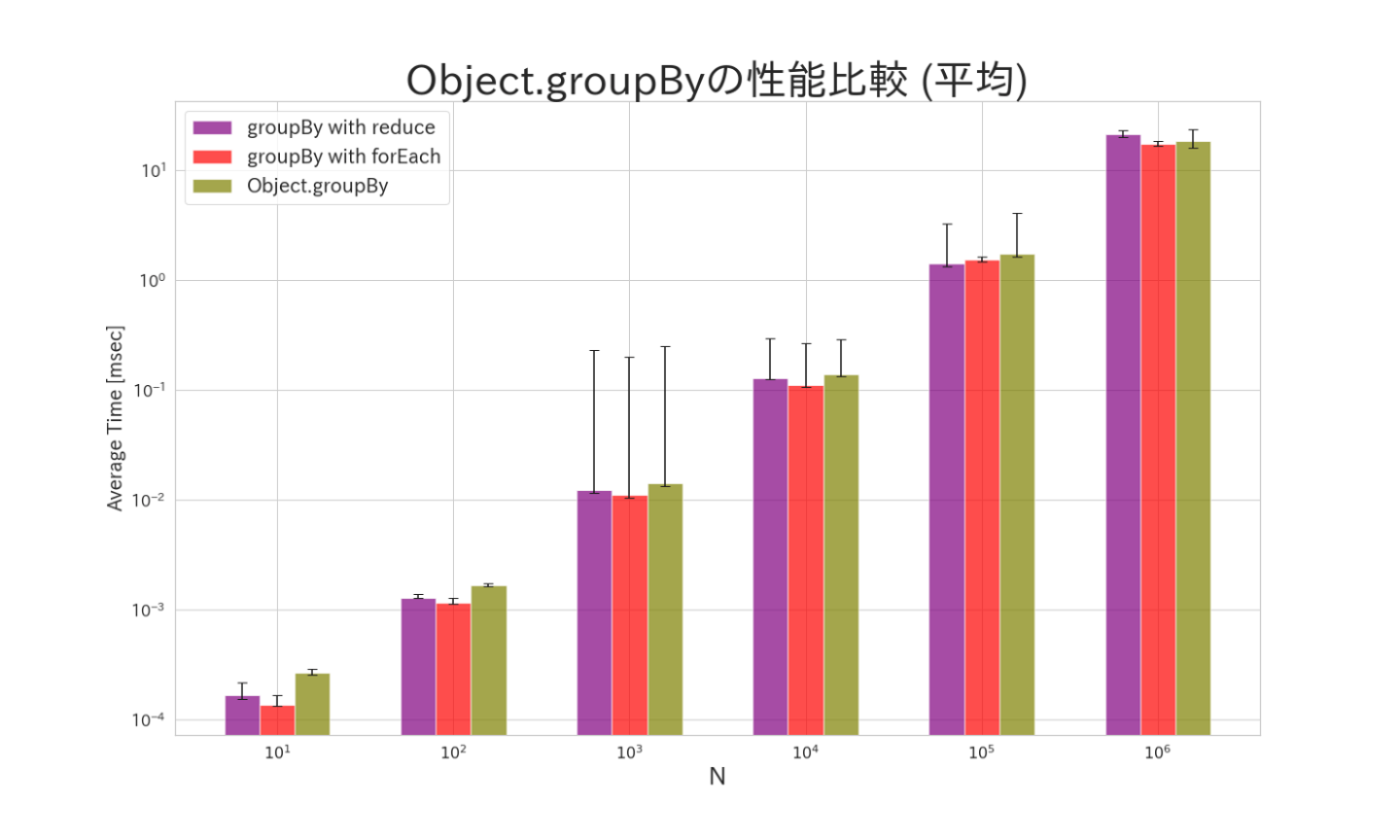
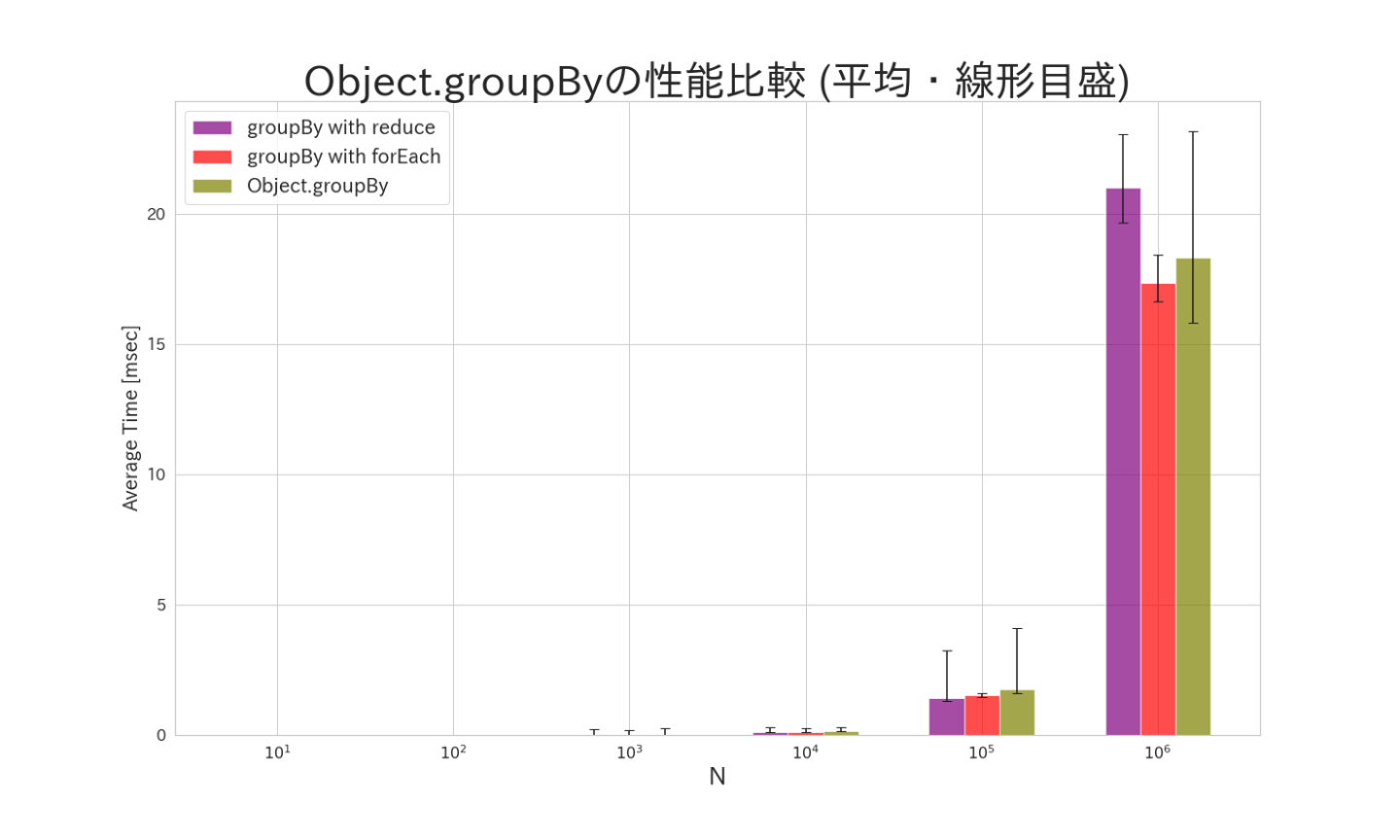
今回はシンプルに、配列内の要素を奇数、偶数に分けるようなコードを実行した場合の速度を比較します。
また、配列の要素数に関しては、10、100、1000、10000、100000、1000000と変更して、要素数に対する変化も検証します。
検証環境は以下です。
deno 1.42.1 (release, aarch64-apple-darwin)
v8 12.3.219.9
typescript 5.4.3
OS: MacBook Pro 14 inch
CPU: M1 Pro
RAM: 32 GB
deno 1.42.1 (release, aarch64-apple-darwin)
v8 12.3.219.9
typescript 5.4.3
OS: MacBook Pro 14 inch
CPU: M1 Pro
RAM: 32 GB
なお、検証に利用したコードは以下のようなものです。
/**
* 以下のようなarrayをgenする
* {
* even: [...]
* odd: [...]
* }
*/
[10, 100, 1000, 10000, 100000, 1000000].forEach((n) => {
const inputArray = [...Array(n).keys()];
Deno.bench(`groupBy with reduce (N=${n})`, () => {
inputArray.reduce((prevValue, currentValue) => {
const key = currentValue % 2 === 0 ? 'even' : 'odd'
if (prevValue.hasOwnProperty(key)) {
prevValue[key].push(currentValue);
} else {
prevValue[key] = [currentValue];
}
return prevValue;
}, {
});
});
Deno.bench(`groupBy with forEach (N=${n})`, () => {
const map = {}
inputArray.forEach((item) => {
const key = item % 2 === 0 ? 'even' : 'odd'
if (map.hasOwnProperty(item)) {
map[key].push(item);
} else {
map[key] = [item];
}
})
});
Deno.bench(`Object.groupBy (N=${n})`, () => {
Object.groupBy(inputArray, (num) => {
return num % 2 === 0 ? "even": "odd";
})
});
});
/**
* 以下のようなarrayをgenする
* {
* even: [...]
* odd: [...]
* }
*/
[10, 100, 1000, 10000, 100000, 1000000].forEach((n) => {
const inputArray = [...Array(n).keys()];
Deno.bench(`groupBy with reduce (N=${n})`, () => {
inputArray.reduce((prevValue, currentValue) => {
const key = currentValue % 2 === 0 ? 'even' : 'odd'
if (prevValue.hasOwnProperty(key)) {
prevValue[key].push(currentValue);
} else {
prevValue[key] = [currentValue];
}
return prevValue;
}, {
});
});
Deno.bench(`groupBy with forEach (N=${n})`, () => {
const map = {}
inputArray.forEach((item) => {
const key = item % 2 === 0 ? 'even' : 'odd'
if (map.hasOwnProperty(item)) {
map[key].push(item);
} else {
map[key] = [item];
}
})
});
Deno.bench(`Object.groupBy (N=${n})`, () => {
Object.groupBy(inputArray, (num) => {
return num % 2 === 0 ? "even": "odd";
})
});
});
Object.groupByが遅いものの、要素数が多くなるほどその差が縮んでます。forEachで実装したもののパフォーマンスが非常に良く、最小、最大の振れ幅も小さくなってます。このことから、forEach>reduce>Object.groupByの順でパフォーマンスが良い事がわかります。
要素数が非常に小さい場合はナノ秒ほどしかかからないのであまり気にする必要なく使っても良さそうでですが、要素数が多くなる場合(特にサーバー側などで大量のデータを扱う場合)などはforEachを使って愚直に実行したほうがいいかもしれません。(最も、今回はシンプルなケースなので、もっと複雑な場合はまた事情が変わってくるかもしれないです。)
/assets/images/4901651/original/9de972b3-d882-4d9c-b24b-93fff9219963?1586959280)


![]()