Hadoopエンジニア
中途
4エントリー
on 2022/03/31
2,237 views
4人がエントリー中
月間数千億アクセスの分散処理基盤を開発するエンジニア-WANTED!

東京
中途
海外進出している
なにをやっているのか
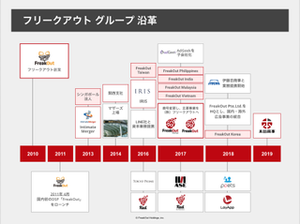
フリークアウトの祖業であるRTBのテクノロジーは、「コンピュータが、人が媒体を見た瞬間を一瞬で評価し、適正価格を算出し、広告枠を買い付ける」ことを可能にしました。それまでの人の手による買い付けでは絶対にできなかったこの手法が可能になったことで、広告業界には、「アドテク(広告テクノロジー)」と言われる新しいマーケットと、多くの職種が誕生しました。
この経験から、当社のミッションは「人に人らしい仕事を」とし、機械が人間の仕事を奪うのでなく、機械によって人間の新しい仕事を作り出すことを可能にするようなビジネスの創生を目標としてきました。
昨今DXというキーワードが流行り言葉になっていますが、このキーワードが意味するところが、「人の仕事を機械に置き換えること」であるとするなら、我々フリークアウトは流行り言葉に惑わされず、引き続き「人間では不可能だったことを機械によって可能とし、それによってこれまでなかった新しい仕事を人に提供する」を目指します。
■「Accept change, transform yourself.」 / (FY24-26 中期経営計画達成に向けたグローバル統一グループスローガン)
グローバルマーケティイングカンパニーとしての更なる進化。世界に通用するモノづくり(ソフトウェア、ハードウェア)企業へ
▼中期経営計画
https://www.fout.co.jp/ir/irnews/202312/
□各フォーカス領域における事業戦略の概要
■プロダクトのグローバル化:日本発のプロダクトを北米経由でグローバルへ展開
■インフルエンサーマーケティング:グループ化したUUUMをコアに事業を展開し、プロダクトの開発とグローバル展開を目指す
■Retail:コンテンツ配信システムのソフトウェアから、サイネージのハードウェアまで、リテールメディアのインフラを一気通貫に提供、グローバルスタンダードを目指す
■動画広告プロダクト:タクシーサイネージ、Scarlet(メディア向け広告収益最大化プロダクト)等、既に事業の柱となっている事業の更なる拡大、GPの日本での拡販及びグローバル展開
□グループマネジメント(グループ力の強化)
■グループとしての全体最適をより意識した経営により、グループ全体の価値向上を目指す。成長領域への投資余力を高めるため、よりキャッシュフローを重視し、改善・安定化に努めます
■最新topic
▼フリークアウト・ホールディングス
フリークアウト・ホールディングス、リテールメディア特化型サイネージハードウェアの提供を開始 〜ソフトウェアからハードウェアまで、リテールメディアのインフラを一気通貫して提供可能に〜
https://www.fout.co.jp/news/pressrelease/pr20231020/
創業10周年記念 特設サイト公開のお知らせ
https://www.fout.co.jp/news/information/info20201001/
▼フリークアウト
フリークアウト、小売事業者様向けに収益最大化プラットフォーム「FreakOut Retail Media Platform」の提供を開始。提供先第一弾はコープデリ生活協同組合連合会。
https://www.fout.co.jp/freakout/news/pr20230914/
フリークアウトのマーケティングプラットフォーム「Red」、世界最大級のスポーツストリーミングサービス「DAZN」への広告配信を開始 〜プレミアムな動画広告在庫を拡大〜
https://www.fout.co.jp/freakout/news/pr20220823/
▼IRIS
急成長中のゴルフカートサイネージメディア「Golfcart Vision®︎」、約40ゴルフ場・約2,500台へと大きく増台
https://www.tokyo-prime.jp/news/20231115gcvbaitaisiryou20241-3/
「Tokyo Prime」全国展開に向け全国30都道府県へエリア拡大し、搭載数66,000台を突破
https://www.tokyo-prime.jp/news/20230104-baitaisiryou/
なぜやるのか


Give People Work
That Requires A Person.
〜人に人らしい仕事を。〜
AIによって、人の仕事が奪われることはない。
我々フリークアウトの祖業である「人が媒体を見た瞬間に広告枠を買い付ける」ことを可能にした RTB は、それまでの人の手による買い付けでは絶対にできない手法でした。これが可能になった途端、広告業界に起きたこと、それは新しいマーケットの始まりでした。
そのマーケットを支える事業社群の成す業界構造は、のちにカオスマップと呼ばれるくらい複雑なものとなり、最近では MBA の教科書にも出てくるようになったそうです。結果として、日本では RTB 誕生から数年で、当社をはじめ、いくつものアドテク銘柄と言われるような上場企業が誕生しました。
この経験からフリークアウトでは、昨今言われている「AI が人の仕事を奪う」ような考えに対して、それは「人が機械に何をやらせるか次第」と考えるに至り、それに基づいて、我々の成すべき事業を定めています。
つまり、元々人間でも出来たことを、人の代わりに機械にやらせる程度の事業を作るから、「機械に仕事を奪われる」と言われてしまうのであって、そもそも人間が出来るわけがないレベルの仕事を機械に託すほどの事業を作り出せれば、それは新たな産業を生み出し、そこにおいて、人は人らしい新たな仕事を見つけ出すであろうことから、雇用創出は可能ではないでしょうか。
さらに我々は、これをグローバルで実現していくため、急速な海外展開と、世界でも勝てる技術水準の向上を同時に進めています。広告取引を機械の手に置き換え、タクシー車内では紙チラシ時代にはあり得なかった一流ブランドの広告が流れるようにした我々ですが、まだまだ道半ば。もっともっと圧倒的な技術力と、世界に手を広げたビジネス基盤をベースに、人が思いもしなかった、freak out (度肝を抜かす)レベルのことをコンピュータに任せることで、新たな産業を創出していくことが我々フリークアウトの使命です。
「AI によって、人の仕事が奪われることはない。」
“賛成する人がほとんどいない大切な真実”であると信じて、人とコンピュータと、その間にある仕事のあり方そのものに一石を投じるようなプロダクトを作り続ける企業グループでありたいと願っています。
弊社コーポレートサイト TopMessageより
株式会社フリークアウト・ホールディングス 代表取締役 本田 謙
どうやっているのか


FreakOut ブランドに込めた想い
”freak out”という英単語は、「ひどくびっくりさせる」という意味を持ちますが、
社名の「FreakOut」は、我々が世間の”度肝を抜く”水準の製品を作り、世に送り出す集団であることを示します。
ありきたりに満足せず、世の中に強いインパクトを与えるべく挑戦を続ける姿勢・意思を
集約した社名が「FreakOut」なのです。
「FreakOut」のブランドには、その名の通り
1・挑戦を続ける(=いつまでもベンチャーであり続ける)
2・他者に強烈なインパクトを与える(=染まらず、自らが染めていく)
という意味が込められ、強烈な印象を持つ「赤」の中でも
「ディープレッド(重厚な赤)」をブランドカラーにしています。
我々FreakOutはプロダクトベンターとして、ありきたりの製品レベルに満足することなく、世に出した製品は常に世間の「度肝を抜く」水準であることを目指していきます。
それが世間的・業界的に受け入れがたいモノであったとしても、「横並びで、無難な落ち着きどころを良しとせず、一石すら投じることの出来ないモノを世に送り出すことに何の意味があろうか」と、高度なテクノロジーの中にもどこかロックな反骨精神が見え隠れする我々でありたく願っております。
今後も今までと変わらず、FreakOutらしい稀有なチャレンジで業界に向き合い続けます。
<FreakOutの挑戦はコチラ↓>
フリークアウトグループにいる、「すごい仕事をやっているすごい人」を伝えるメディア
https://make-some-noise.fout.co.jp/
こんなことやります
DSP/DMP で生み出される大規模なデータを分析するための基盤作り、そして分析から結果をプロダクトに反映し、さらなるパフォーマンスを発揮させるためのプロダクト開発を担っていただきます。
■具体的には…
・大規模データ分析を効率的に行うための基盤やツール群の整備・開発
・Apache Hadoop やその他オープンソースソフトウェアの調査・活用・運用
・データ分析自体を行い、プロダクトとしてのアウトプット
■データ規模
・3000億req / 月 20億ユニークブラウザデータ
■開発環境
Linux (CentOS), MySQL, TokyoCabinet, Memcached Perl, Java, Scala, C/C++
Python, Go, Hadoop, Hive, Spark, HBase, Presto, Kafka, re:dash
AWS (EC2, S3, VPC, Route 53), Puppet, Fluentd, Elasticsearch, Kibana, Norikra
Vagrant, KVM, Slack, GitHub, CircleCI, Mackerel, Jenkins, Ukigumo
厳しい制約条件の下でテクノロジーの力を最大限まで引き出すことに興味をお持ちの方、お気軽に「話を聞きに行きたい」ボタンを押してください!
ご応募、お待ちしています!!厳しい制約条件の下でテクノロジーの力を最大限まで引き出すことに興味をお持ちの方、お気軽に「話を聞きに行きたい」ボタンを押してください!
ご応募、お待ちしています!!
13人がこの募集を応援しています
会社の注目のストーリー
株式会社フリークアウト・ホールディングスの他の募集
- アカウントエグゼクティブ
アカウントエグゼクティブ募集@大阪/国内アドテクのリーディングカンパニー
話を聞きに行くステップ
- 応募する「話を聞きに行きたい」から応募
- 会社からの返信を待つ
- 話す日程を決める
- 話を聞きに行く
募集の特徴
オンライン面談OK
会社情報
2010/10に設立
570人のメンバー
- 海外進出している/
- 社長がプログラミングできる/
- 1億円以上の資金を調達済み/
東京都港区六本木6-3-1 六本木ヒルズクロスポイント5F(総合受付)