/assets/images/4011356/original/888630f0-8d41-4054-8de3-5be6c86f98d7?1566135134)




多要素認証疲労攻撃とは?MFA疲労攻撃とも呼ばれる攻撃手段と対策を解説
多くのWebサービスは、認証方法に「多要素認証」を採用しています。仮にログイン情報が流出しても不正ログインを防げるわけですが、「多要素認証疲労攻撃(MFA疲労攻撃)」は多要素認証を悪用します。多要素認証疲労攻撃の基礎や対策方法、被害事例につ
https://cybersecurity-jp.com/column/72896
こんにちは。
エス・エー・エス株式会社の海田です。
私事ですがつい最近、PS5を購入しました!
FF16をやりたくて本体とセットで発売日当日(6/22)に届くように予約していたのですが、
発売の1週間前に(すでにPS5本体を持っている方向けに)体験版が先行DLできるようになり、
先行して進めた多くのユーザからの大絶賛の嵐・・。
内容を先に知りたくない私は、自主的にプレイ動画を見ないようにしていました(笑)
そしてつい先ほど、無事に届きました。
本体デカいですねー!
最近のゲーム機は、スペックや性能はもちろん、YoutubeやAmazonPrimeなどのオンラインサービスが利用できたりなどできることが増えて本当に進化したなあと思う反面、
ユーザアカウント登録やネットワーク設定が初期設定として必要になってくるので、
肝心のゲーム始めるまでにいろいろな準備が必要で、それはそれで大変だなあ・・と思います。
昔のファミリーコンピューターなんて、線つないで、カセット「フー」して入れて、
電源ポチ!で即座にソフト起動ですからね。。
(この話が懐かしいと思われる方はもう結構いいお年!もちろん私含めて(笑))
さて、今回のTeckBlogはそんなハードウェアの進化の話にしようかなあと思っていたところなのですが、
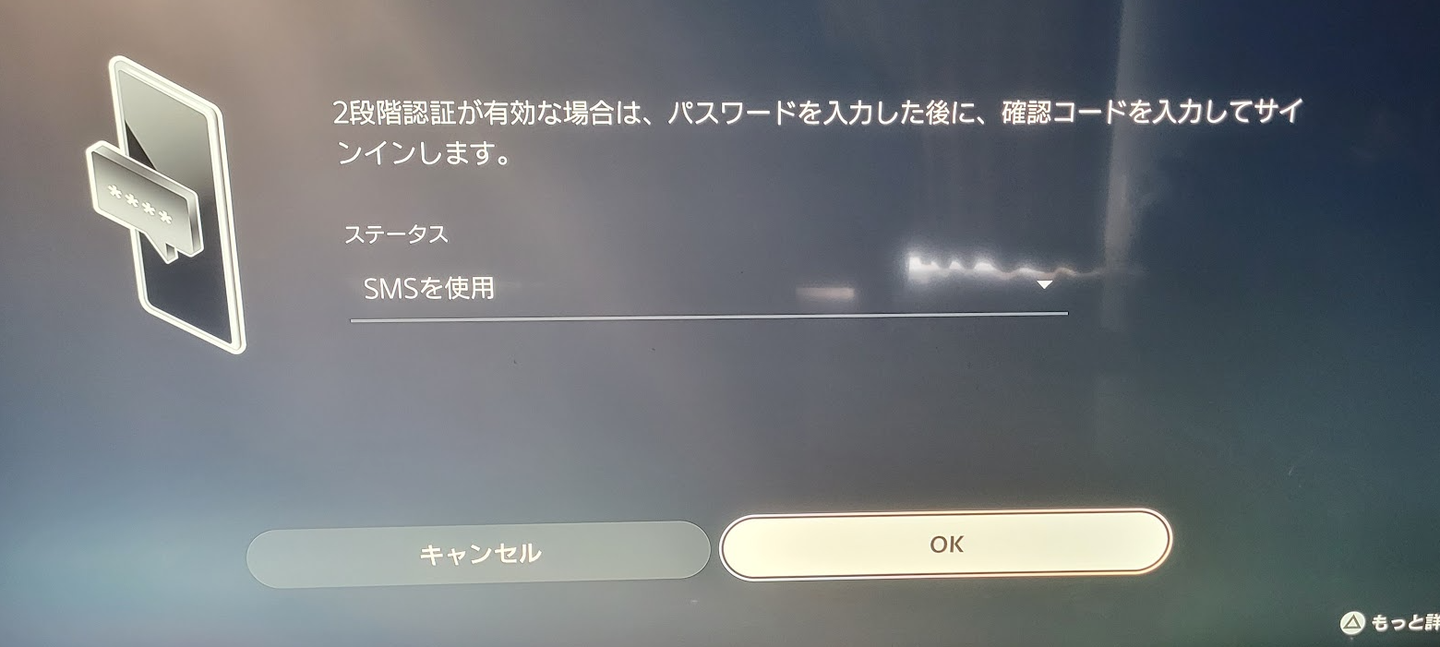
PS5の初期設定をしたとき、「ニ段階認証」のフェーズがありました。PS5にも二段階認証って標準で設定できるんだなあと感激したので、今日はそのお話にしようかと思います。
「2段階認証」という言葉の意味は、
「認証」という行為を1回ではなく、2回に分けて行うんだなあ・・
という予想はなんとなくつくかと思います。そのイメージであっています。
では「認証」とは何でしょうか?「認証する」とはどういう行為なのでしょうか?
「認証」とは簡単に言うと、
「システム」が「あなた」を「あなたである」と理解することです。
例えば、
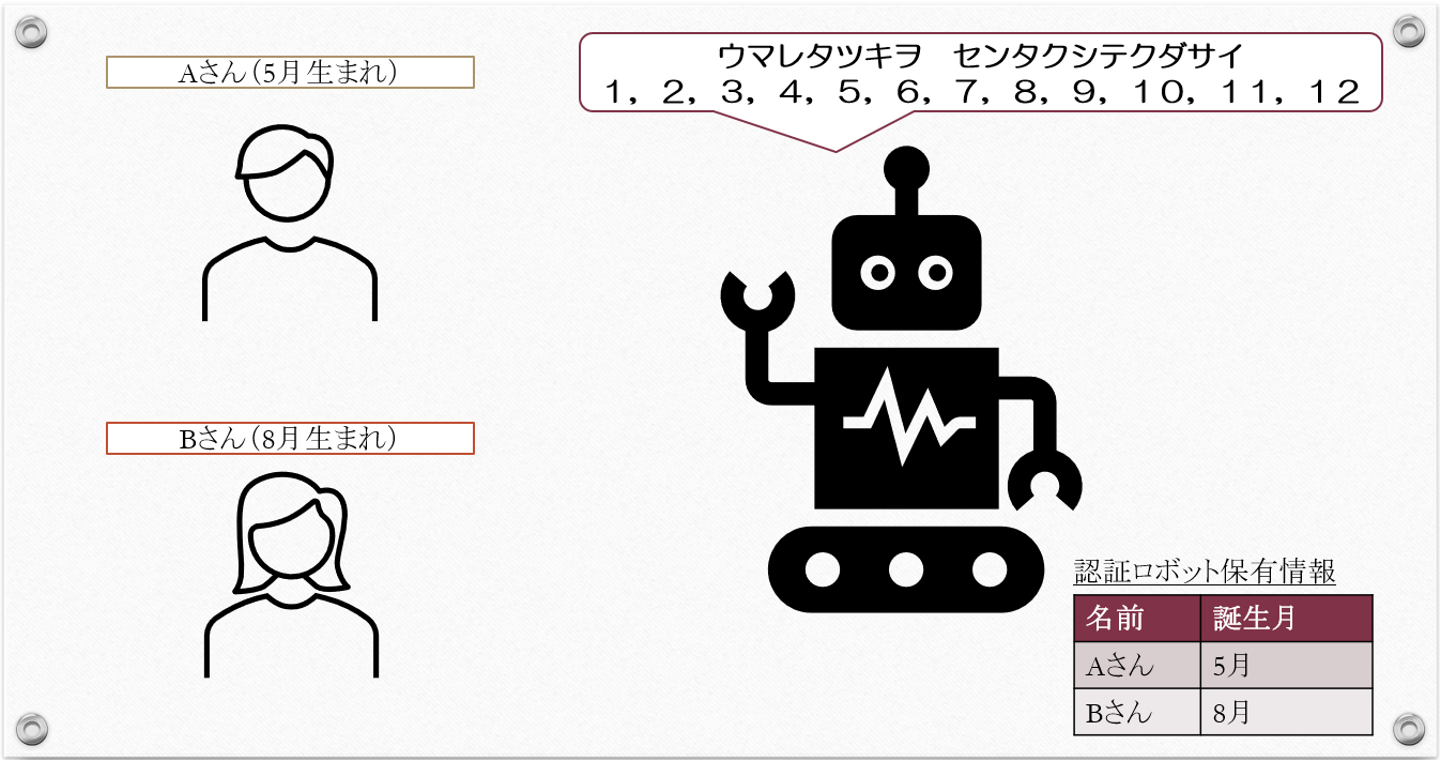
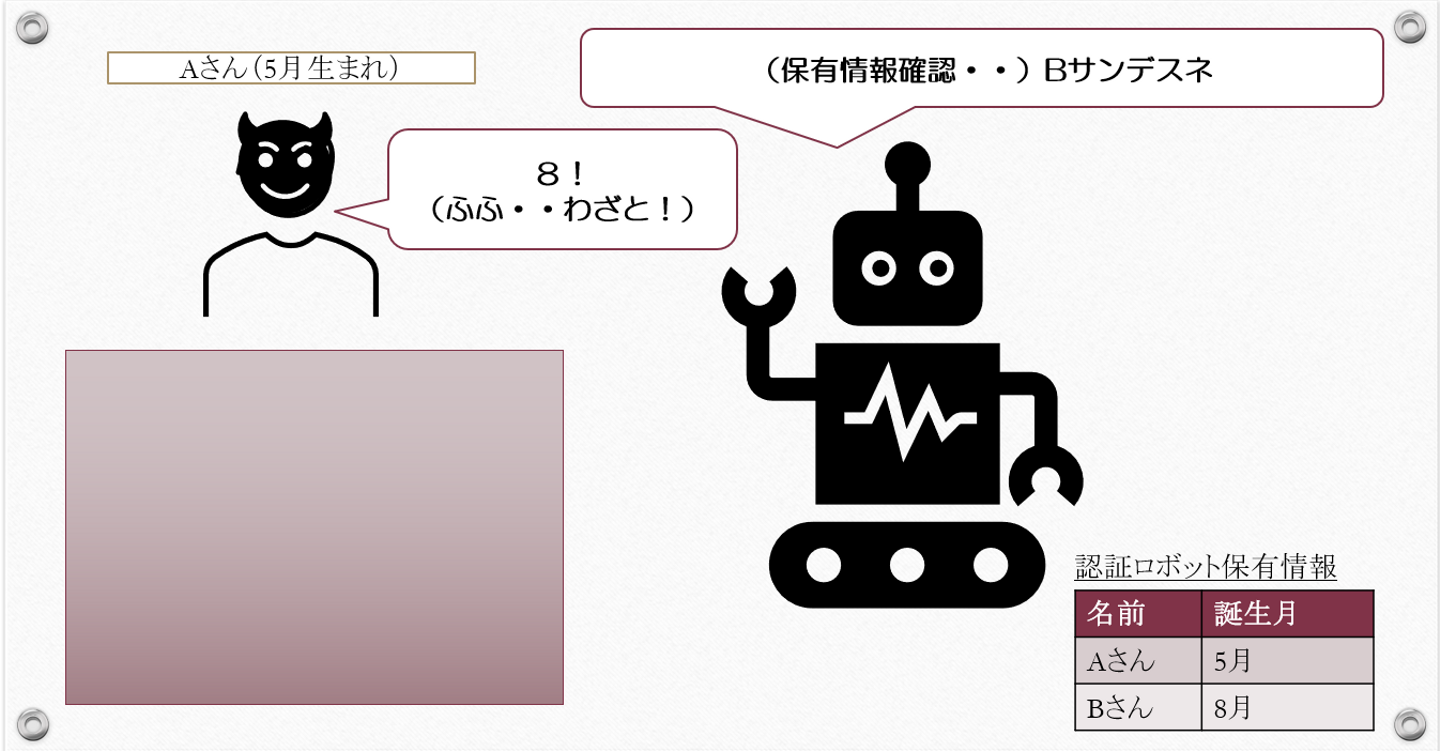
5月生まれの「Aさん」、8月生まれの「Bさん」、そしてとある「認証ロボット」
がいたとします。
認証ロボットは、Aさん、Bさんから以下の情報だけを教えてもらい、事前に持っています。
Aさん:5月生まれ
Bさん:8月生まれ
そして認証ロボットは、ある質問を投げかけます。
「ウマレタツキヲ、センタクシテシテクダサイ」「1,2,3,4・・・・10,11,12」
この質問にAさん、Bさんが答えていく・・という状況をイメージしてください。
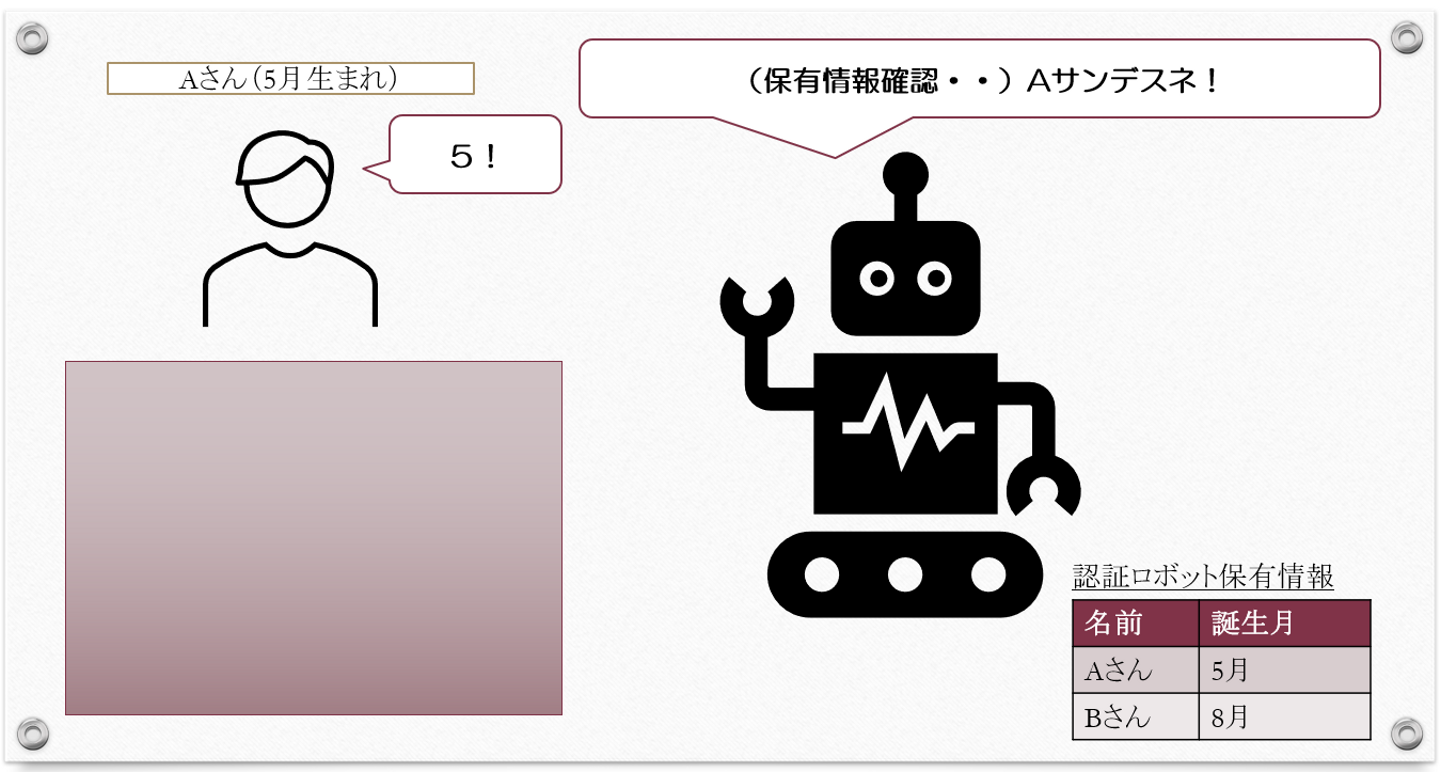
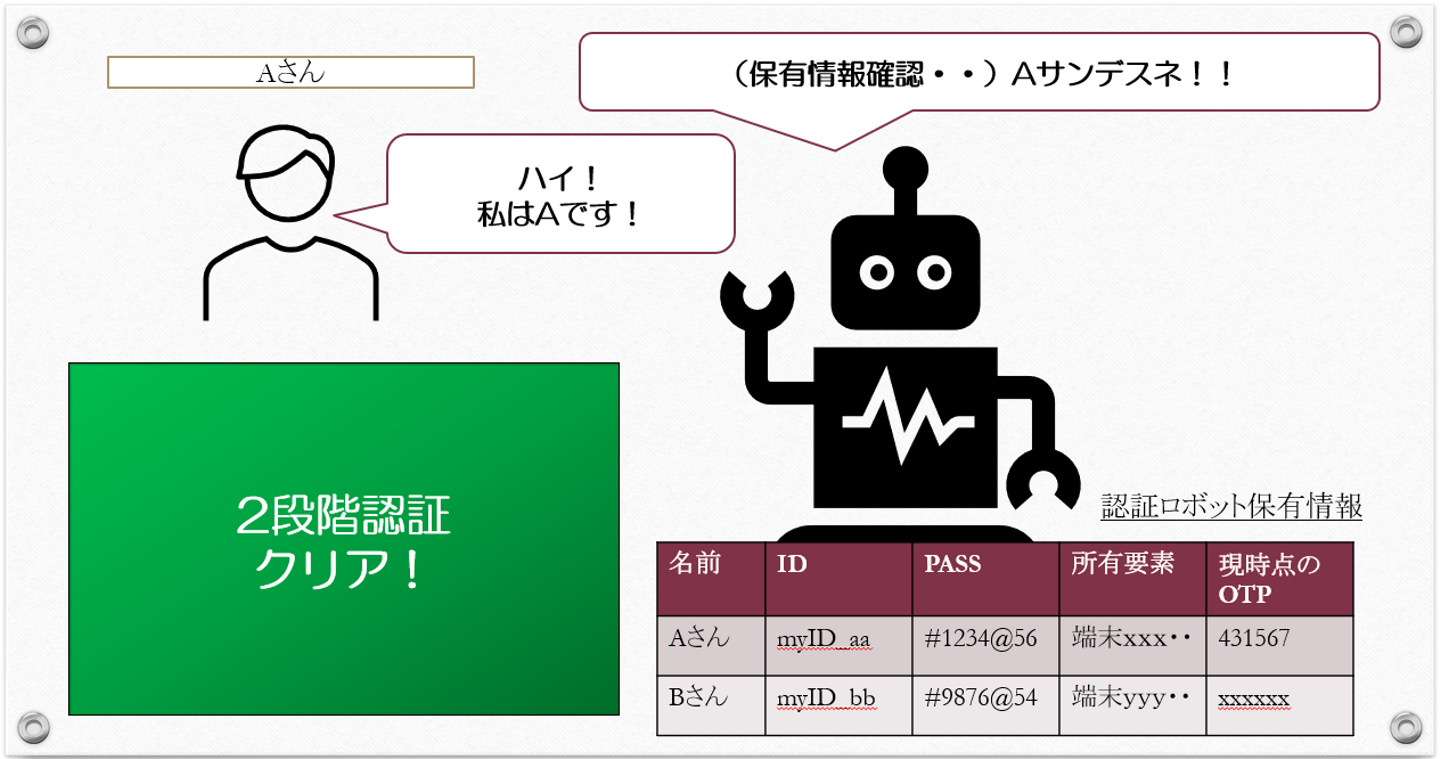
Aさんは(5月生まれなので)ロボットの質問に「5」を選んで答えます。するとロボットは、
今自分の目の前にいる人間は「Aサンデスネ」と理解します。
Bさんはロボットの質問に「8」を選んで答えます。するとロボットは、
今自分の目の前にいる人間は「Bサンデスネ」と理解します。
このように、質問の答えから質問者が誰なのかをロボットが理解している行為を「認証」と言います。
これが一番簡単な認証の例です。
そのような疑問が湧く方はとても鋭い方です。
そうです!この認証ロボットには大きな欠陥があります。
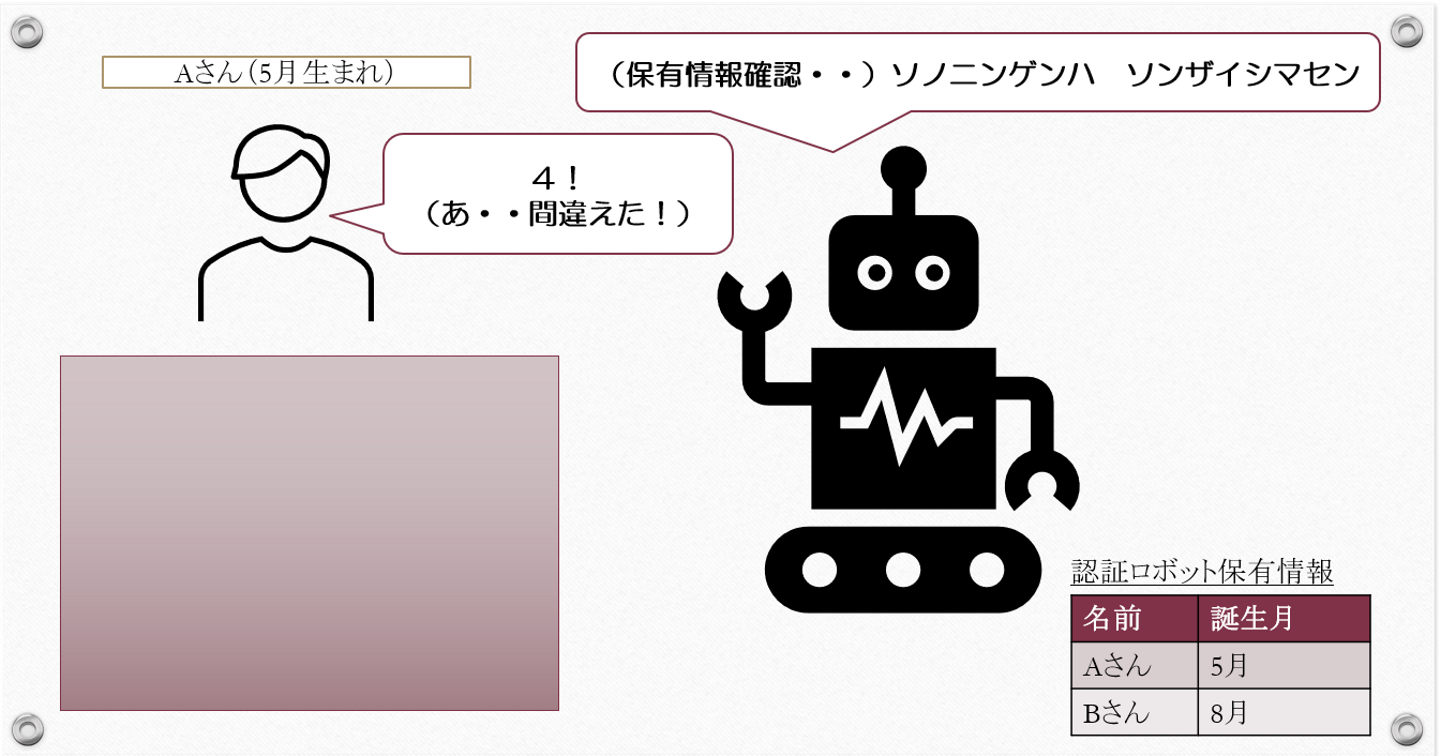
この質問で、Aさんは間違って「4」と答えたとします。すると認証ロボットは、「・・・ソノニンゲンハ ソンザイシマセン」となってしまいます。
つまり、事前に伝えられていない情報を入力された場合、認証ロボットは判別ができません。
目の前の人間が正しい人間(ここではAさん)であっても、認証ロボットはAさんであると理解しません。
「認証失敗」となります。
この質問で、Aさんはわざと「8」と答えたとします。すると認証ロボットは、「Bサンデスネ」と理解します。
事前に伝えられていた情報の中に合致するものがあれば、認証ロボットは疑う余地なくAさんを「Bサン」と理解します。目の前にまごうことなき「Aさん」がいるのに、認証ロボットは「Bさん」と理解します。
「誤認証」となります。
残念ながらこの認証ロボットでは、正しい認証ができないということがわかります。
では、「認証失敗」や「誤認証」が生まれる原因はどこにあるのでしょうか?
まず欠陥その①から考えてみます。
欠陥その①は、Aさんが別に悪いことをしようとしているわけではなくて、
単純に回答を間違えたというケースです。なのでこの原因はAさん側にあります。
対処としては、「質問に対して、正しい情報を回答する」となります。
次に欠陥その②です。
これは、Aさんが自分を偽って「8」と回答しています。そして認証ロボットが保有する事前情報として「8」に相当する人間(Bさん)が存在したので、認証ロボットは「Bサンデスネ」と誤った判断をしてしまいます。悪意という意味ではAさんが確かに悪いですが、この原因はそれを検知できないシステム側にあります。
では、この欠陥②はどうすれば対処できるでしょうか?
たぶん、もうお気づきの方もいらっしゃるかもしれませんが、
この認証ロボットの一番よくない点は、
「認証に用いる判断材料がざっくり過ぎる」ということになります。
部屋にAさん、Bさんしかいないというのであればまだしも、
例えば東京のど真ん中でこの認証システムを作動させたらどうなるでしょう?
5月生まれ、8月生まれなんて、世の中にたくさんいます。
この認証ロボットは、それらを全てひとくくりに「Aサンデスネ」「Bサンデスネ」「ソンザイシマセン」と理解してしまうわけです。
だから欠陥②の対処方法としてふさわしいのは、
「認証に用いる判断材料は固有の情報に変更する」となります。
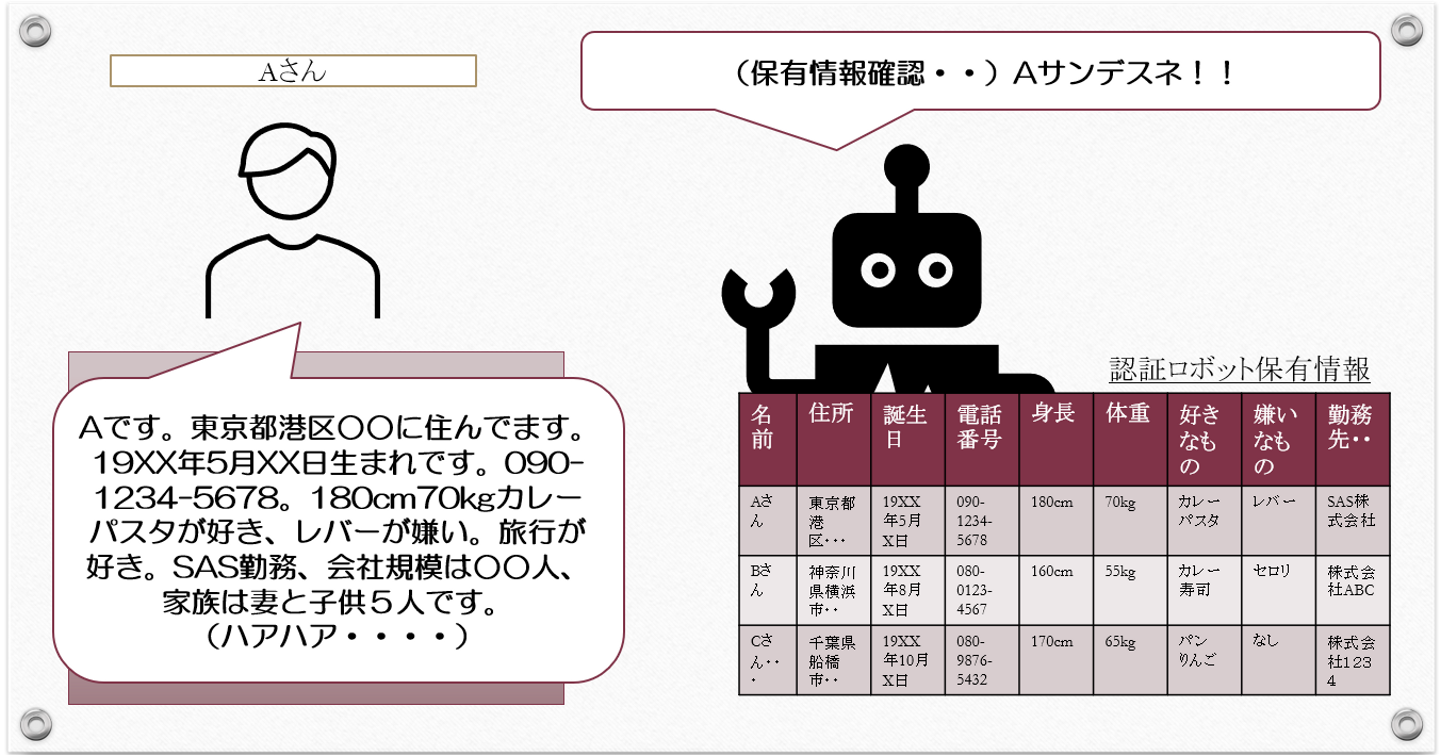
では、Aさん、Bさんを判別するためにもっと細かい固有の情報をたくさんかき集めて、
それを事前情報としてこの認証ロボットに登録させればよいでしょうか?
例えば以下のような情報です。
・氏名
・住所
・生年月日
・電話番号
・身長
・体重
・好きなもの
・嫌いなもの
・趣味
・勤務先会社
・勤務先会社規模
・家族構成
・・・etc
そして、認証ロボットは
「シメイ、ジュウショ、セイネンガッピ、デンワバンゴウ、・・・、キンムサキカイシャ、カゾクコウセイ・・ヲ ニュウリョクシテクダサイ(・・ハァハァ)」
って質問を投げかけて、
Aさんはそれを全部入力していって・・・認証ロボットは答えます。
「・・・ハァハァ。。ニンショウカンリョウシマシタ・・、アナタハズバリ!! Aサンデスネ! Aサンデマチガイナイデスネッ!」
・・・「はい、私はAですけど(ここまでの情報いる?ってか認証完了するのダルすぎ!)」
Aさんは呆れてしまいますね。。
固有の情報というのは、どうやら選ぶ必要がありそうです。
認証に利用する「固有の情報」は、たくさんあればあるほど正確に判別できやすいが、多すぎると疲れてしまうという欠点があります。一般的なITシステムにおいては、そこまでは求められていないことが実体験からもよくわかると思います。
代表的な固有情報は以下2つとなります。
①ユーザID
②パスワード
①については固有のユーザID(sas_kaidaとか、kaida1234とか)を入力するケースもありますが、最近は
メールアドレスをユーザIDとするケースが多いのではないかなと思います。
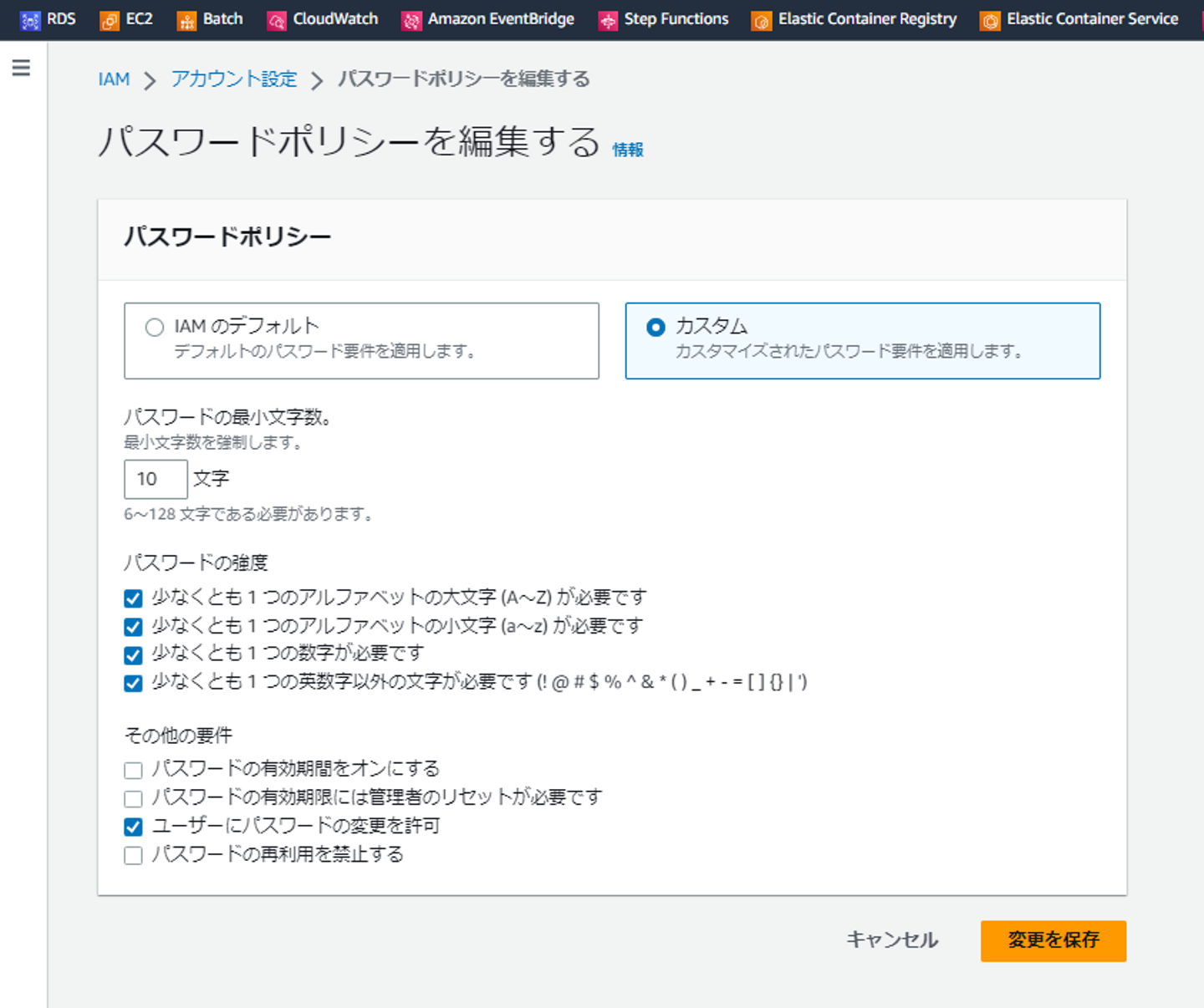
②パスワードについては、利用できる文字種類、桁数などサービスごとに制約が異なります。またサービスによっては、利用者のパスワードの厳格度を定義することもできます。下記はAWSのIAMでのパスワードポリシーの例です。利用するIAMユーザのパスワードとして、文字数や利用できる文字、利用方法などを定義できます。
ユーザID、パスワードだけであれば、覚えておけそうな入力情報なので「認証失敗」のリスクは減ります。また、多くの人が重複しそうな誕生月などと違い、作成したあなた(とシステム)しか知らない唯一の情報となりますので、ロボットが「認証する」という行為においても、「誤認証」は発生しなさそうです。ということで、少なくともユーザIDとパスワードの組み合わせがあれば、認証という点については問題なさそうです。
では、これで安全なのでしょうか?
誤解を恐れずに私的な意見でいえば、まあぶっちゃけ「大半は大丈夫」です。(※)
だからこそ皆さん多くの場面で、「ログインID+パスワード」で自身の関係するサービスにアクセスしていると思います。では大半は大丈夫であるにもかかわらず、二段階認証という言葉が当たり前のように広まったのはなぜでしょうか。
(※)大半は大丈夫と言いましたが、不特定多数に公開しない、公開されるような環境を持たない、安易に推測されやすいパスワードにしない、定期的に変更する・・など、適切な運用をしていることが大前提です。またシステム的にもパスワードを一定回数間違えたら自動ロックがかかるなどの対策が取られていることも大切です。
私が記憶に残っている中で「二段階認証」という言葉が世間一般に広まったのは、某コンビニの決済サービスにおける不正利用問題の時だったかなと思います。
当時社長の方が記者からの「対策として二段階認証は導入されていなかったのか?」の質問に対し
「二段階認証?なんですかそれ?」と回答したことで、マスコミがとりあげ一気に広まった感がします。
決済サービスを提供する会社の代表が、二段階認証を知らなかったということで随分と話題になりました。
先ほど「ログインID+パスワード」で大半は大丈夫!と言ったばかりですが・・そうではない例がここにあります。不正利用されるということは、その情報を悪意を持った誰かが知り、利用しているということです。
ということは、万が一「ログインID+パスワード」を知られてしまった後でも、あなたでなければ認証されないという別の仕組みが必要となります。とはいえ、先ほどのように住所氏名、勤務先・・などなどたくさんの情報を一気に入れるのは疲れてしまいます。もう少し楽に、そしてもう少し別の観点でその仕組みを導入することができないか・・ということをたくさんの人たちが考えました。(たぶん・・)
ところで、認証には「要素」という考え方があります。
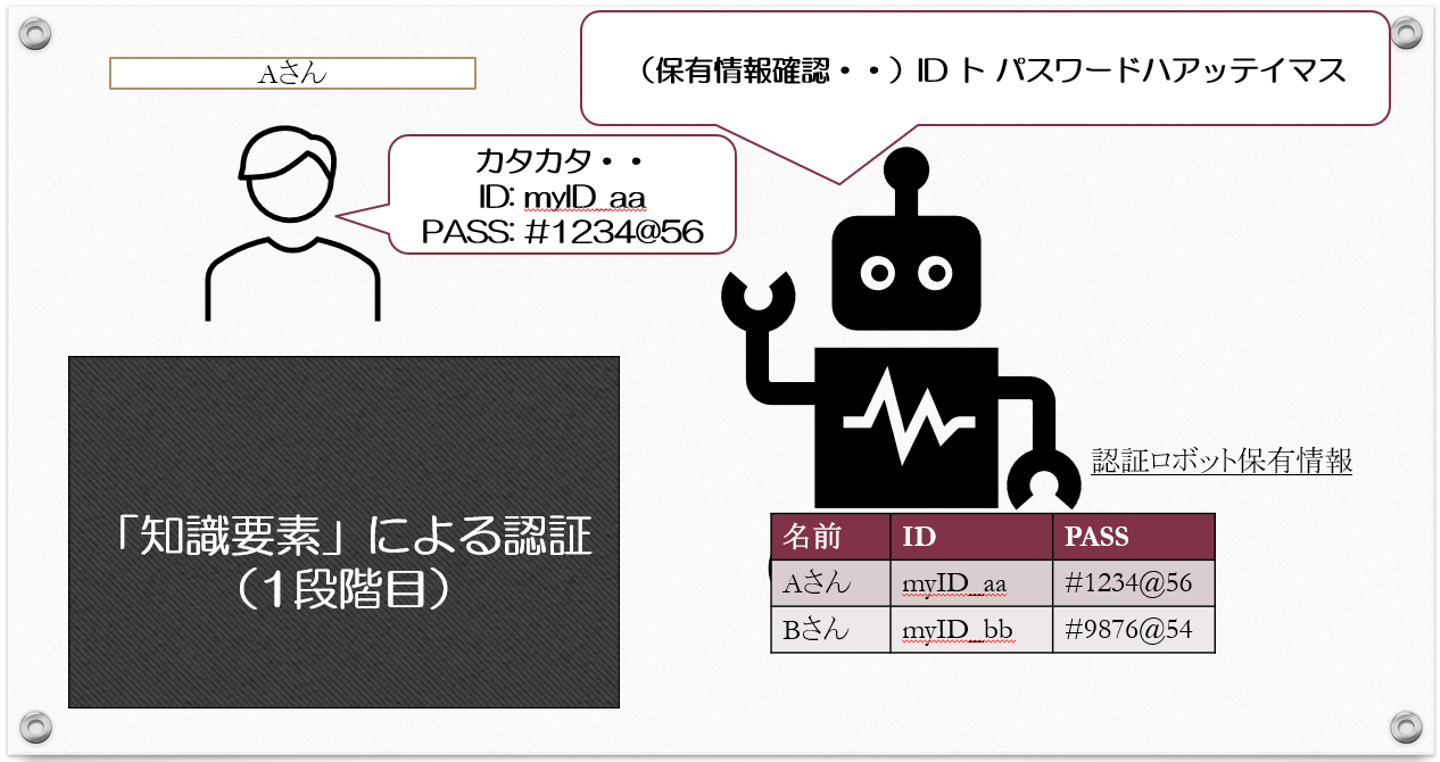
・知識要素(ID,パスワードなど)
・所有要素(スマホ、PCなど)
・生体要素(指紋、虹彩、声、静脈など)
これまでは主に「知識要素」について説明してきました。そして認証ロボットも「知識要素」によって「認証する」という行為をしていたことがわかります。
「知識要素」というのは「頭で覚えられる情報」なので、別にあなたでなくてもわかろうと思えばわかってしまうのです。(めちゃくちゃ暗記が強い人とかいますよね)
先ほど出てきた「あなたでなければ認証されないという別の仕組み」を実現するためには、この知識要素だけでは不十分なことがわかります。
そこで重要になってくるのが、「所有要素」や「生体要素」です。
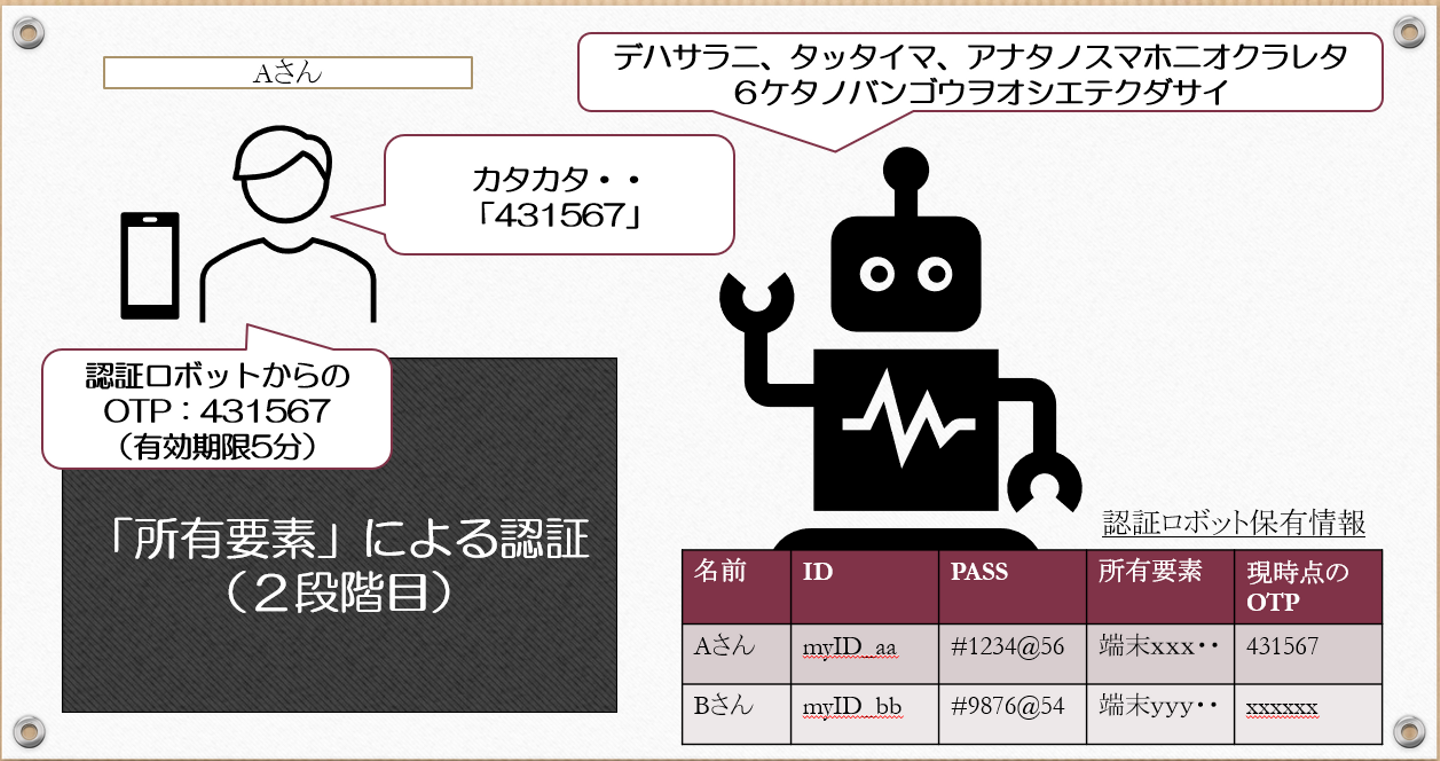
悪い人が、あなたの「IDとパスワード」をもって認証ロボットに挑んだとしても、
認証ロボットが
「ID ト パスワードハアッテイマス」「 デハサラニ、タッタイマ、アナタノスマホニオクラレタ、6ケタノバンゴウヲオシエテクダサイ」
なんていうことを重ねて質問(所有要素)したり、
認証ロボットが
「ID ト パスワードハアッテイマス」「 デハサラニ、アナタノミギテノオヤユビヲ、ココニオイテクダサイ」
なんていうことを重ねて質問(生体要素)したりできたら、悪い人はあなたであると誤認証されることはありませんね。
悪い人はあなたのスマホを持ってはいませんし、あなたの右手の親指を持っているわけでもないです。
そしてまさにこの「重ねて質問する」というのが「二段階認証」です。
さて一般的には「二段階認証」という言葉が広まっている感じがしますが、本来は
「二段階認証」ではなく、「二要素認証」もしくは「多要素認証」という言葉がベストです。
(まあ別に二要素、多要素の意味で二段階認証と言うのであれば別にいいかなと思いますが・・)
二段階認証は認証を二段階で行うという意味です。
なので極論を言ってしまうと、例えば認証ロボットが
「IDヲ ニュウリョクシテクダサイ」(1段階目)
「IDハ アッテイマス、ツヅイテ、パスワードヲ ニュウリョクシテクダサイ」(2段階目)
というように、IDの質問に重ねてパスワードを質問してきても二段階認証となります。
でも、これは意味がないことがすぐにわかりますね。
知識要素だけで2段階しても、あまり意味がないですね。そこで、知識要素、所有要素、生体要素のうち2つ以上組み合わせて、認証するという仕組みを「多要素認証(MFA)」と言います。
(特に2要素の場合は「二要素認証」と言いますが、あまり一般的に使われている気がしません。)
この要素を組み合わせて使う仕組みが「確かにあなたである」という信頼度をより高めることにつながります。あなた自身も「今アクセスしようとしているのは確かに自分自身だ!なぜならIDとパスとこの右手があるから!」という「自分であることの証明」をより強く感じることができます。
PS5でもここは「2段階認証」というタイトルになっていますが、正確には「多要素認証」ですね。
PS5の場合は、認証アプリ、またはSMSメッセージを選べます。
ちなみにこれは「知識」、「所有」、「生体」のうち何の要素でしょうか?
認証アプリもSMSもあなたが持つデバイスに届けられるので、答えは「所有要素」ですね。
PSNのIDのような「知識要素」+SMSメッセージが届くスマホという「所有要素」という複数の要素で「確かにあなたである」と認証しているわけです。
PS5の多要素認証もそうですが、一般的に最もよく利用される要素の組み合わせは、「知識」+「所有」です。具体的には、「IDパスワード」+「モバイルデバイス端末に送られるOTP(ワンタイムパスワード)」です。
OTPの受信方式として、スマホの電話番号を利用したSMSに直接送付する方式や、
Googleやiphoneなどで利用できる仮想認証アプリを用いた方式があります。
どちらも初期設定が必要ですがSMS認証のほうがやや楽かもしれません。
ワンタイムと言われるくらいなので、その場限りの時限内有効なコードとなります。
いずれにせよこのような仕組みを実現することで、システムは確かにあなたであることを正しく理解します。すなわち正しい認証が行えます。ところが・・・
いえ、残念ながらそういうわけではなさそうです。つい最近なかなかショッキングなニュースがありました。
MFAのシステムが悪いわけではなく、MFAを利用している人間が、しつこく届く身に覚えのないOTP入力要請に対し「疲れてしまって」ついつい承認を押す(押してしまうような誘導を促す)ことで認証が突破されてしまう事例です。MicroSoft365やUberなどで事例があるそうです。
指紋認証や顔認証など、生体要素で構成される認証システムを解除する手法を見つけたというニュースです。大量のサンプルを短時間に高速で試行することで力業で突破するようです。ログインIDやパスワードのような知識要素ではなく、生体要素が突破されているところが大きなポイントです。
なかなか重いニュースですね・・。しかしセキュリティというのはいたちごっこであり、そのおかげで改善されていくという文化というか風潮もありますので、このようなニュースは一概に悪いとはいえません。またシステムがいくら完璧でも利用する人間の精神状況によって、誤認証が行われてしまうというのも難しい問題です。所有や生体情報も突破されてしまうという状態で「自分であること」はどのように証明したらよいのでしょうか?
システムは、アナログな人間の情報を全てデジタル化して保存しようとします。保存された膨大なパラメータが入力された情報と一致した時、システムはあなたをあなたであると認識します。あなたが正しく情報を入力し、システムがそれを正しく認証できればよいのですが、残念なことに、どこのだれかもわからない人間が勝手にあなたのデジタルパラメータを入手し、システムが誤認証する事例がたくさんあります。一昔前は、それは知識要素(ユーザIDやパスワード)に限られていました。しかし昨今はそれが指紋や所有デバイスなど、本来その人しか持っていないはずの要素ですら利用して誤認証を誘発するところまで来ています。当然システム側もその上を行く対策を練っていくでしょう。このいたちごっこはずっと続くとは思いますが、根本的にこの認証システムが完璧になるのかというと、私自身はちょっと無理なんじゃないかなと考えています。
というのも、「自分であること」というのはアナログな情報であるからです。システムはあなたというアナログな存在をできるだけ詳細にサンプリングし、デジタルな情報に置き換えます。少し言葉が悪いかもしれませんが、システムはあなたを「こういう人である」と型にはめます。もちろんこの型はとても細かい分類であり、システム分類的には唯一無二なのですが。
しかし、例えばリアルの私とリアルなあなたが目の前にいて向かい合っていたら、きっとお互いがお互いを本物であると(疑う余地なく)認識すると思います。これはお互いがアナログな存在を目の前にしているからこそ感じるものだと思います。目の前で一緒に食事している友人、恋人、家族、社員、がその人ではない可能性なんて考えもしないでしょう。
システムを介すと誤認証の恐れはあるが、リアルな人間を目の前にした場合は誤認証しない。両者の違いはなんなんだろう・・と考えると、やっぱり人間はアナログなものだということです。アナログな存在である人間が、利便性・効率性を期待してシステムを利用することは大いに結構だけれども、システムでアナログな人間を完璧に認証するということは難しい。それは事前に提供したいかなる要素も、結局はデジタルな情報として変換されて保存されるからだと思います。例えば生体要素として指紋をシステムに提供しても、システムはその情報を細かく分析し、デジタルパラメータとして保存したわけであって、指紋そのものを保存したわけではありません。あなたの指紋や声や顔はあなた自身しか持ってはいません。本当の意味で唯一無二なんだと思います。だからこそめちゃくちゃ価値がある。
ということは「究極の認証方法」って何だろうって考えると、やはりアナログはアナログなままで、アナログ同士で認証するのが一番いいのかな?って思ったりしました。
複雑なシステムに情報を入力して無機質にあなたであると認証されるより、近所のおばさんに「あらおはよう○○ちゃん!いい天気ねー!」と声を掛けられる方がよほど確実な認証であり、確かに自分自身であることを証明しているような気がします。最近そういうの、減りましたね。
皆様は「究極の認証」についてどうお考えでしょうか?いろんなご意見お待ちしております!
さて、FF16をやりますか。FF的に言うと究極の認証って「アルティメットオーセンティケーション?」おお、ちょっとかっこいいフレーズ。
読んで下さってありがとうございました!
参考記事・文献(たくさんの記事を参考にさせていただきました。この場をお借りして感謝御礼申し上げます。)
/assets/images/4011356/original/888630f0-8d41-4054-8de3-5be6c86f98d7?1566135134)


/assets/images/4011356/original/888630f0-8d41-4054-8de3-5be6c86f98d7?1566135134)

![]()



/assets/images/11403610/original/888630f0-8d41-4054-8de3-5be6c86f98d7?1670285641)