こんにちは!Onplanetzです。今日は、テキストによる指示のみで内容に沿った画像を生成する、「DALL-E」(ダリ)というAIの紹介をしたいと思います。
この記事を読んで分かること
- DALL-Eの概要
- 実用可能性
- 応用先
------------------------------------------------------------------------------------------------------------------------
1. DALL-Eの概要
DALL-EはOpenAIによって開発された、テキスト(またはテキストと画像)による指示に基づき画像を生成するAIです。
例えばインテリアデザイナーが、斬新な食べものをモチーフとした椅子のデザインをすることになったとします。既存の商品が見つからない、でも出発点となるアイディアが欲しいと思った場合、言葉で指示を与えるだけでそれらしい画像を複数生成してくれるのがDALL-Eです。
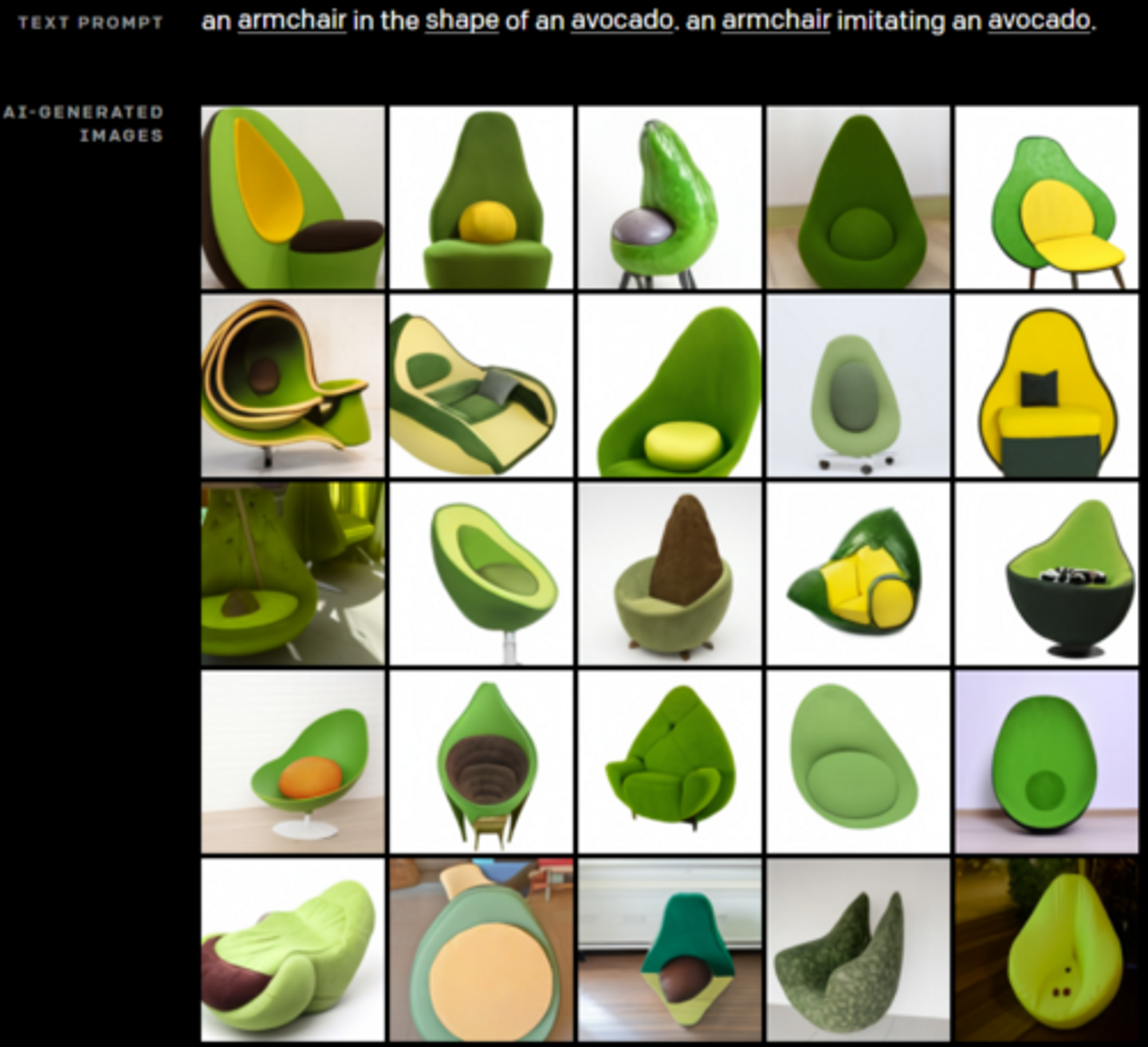
下の画像では、「アボカドの形をした肘掛け椅子」という指示をもとにDALL-Eが画像を描き出しています。
![]()
DALL-Eのすごいところは、これらの画像が全て一から作られたものだということ。そのため今まで一度も人間によって描かれたことのないような突飛な絵の指示も対応してくれます。
例:「ハープでできたカタツムリ」
![]()
また、あらゆる描画スタイルに対応しており、指示に加えるだけでイラスト風、絵画風、風景画、鉛筆デッサン、ロゴなどさまざまなスタイルの画像を作り出すことが可能です。
そんなDALL-Eを支えるアルゴリズムは、同じくOpenAIによって昨年発表された深層学習モデルのGPT-3と類似しており、GPT-3が指示に応じてさまざまなジャンルの文章を生成するのに対し、DALL-Eはそれの画像生成版といえます。GPT-3ほどではなくとも膨大な数である120億のパラメータを有し、細かい指示に合った画像の生成を可能にしています。訓練に使われたデータセットの詳細は明らかになっていませんが、ネットの画像とキャプションのペアリングを分析させ、特定の単語と画像の関係性を学習させたと報告されています。
また、GPT-3と同じく深層学習の新たなアプローチであるTransformerが使用されており、画像やテキストはアルゴリズム内で機械により理解しやすい形(トークン)に変換されます。そのためモデルの訓練時間を大幅に削減することが出来たほか、テキストによるシンプルな指示から複雑なアウトプットである画像を一から生成することが可能になっています。一度の指示で512枚の画像が生成され、CLIPと呼ばれる画像分類AIによる評価の高い32枚がユーザーに表示されます。
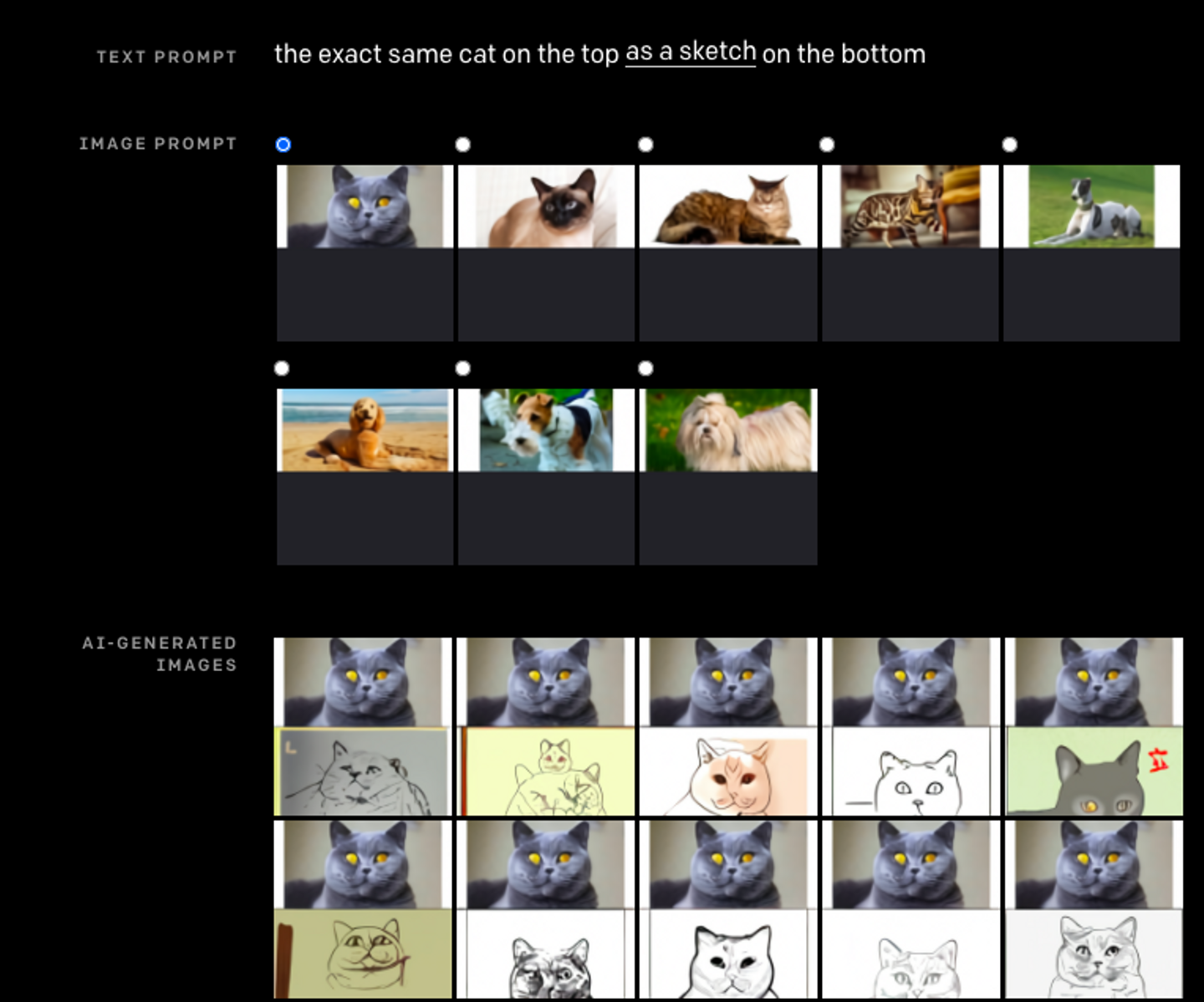
もう一点DALL-Eの特徴として挙げられるのが、Zero-Shot Visual Reasoningという手法です。従来の機械学習のモデルでは、特定のタスクを想定してパターンを認識させるため訓練を行うのが一般的ですが、DALL-Eではあらかじめ想定されたタスク(テキストの指示から画像を生成すること)だけでなく、指示内の情報を汲み取って様々なタスクに対応できるようになっています。例えば以下の図では、猫の画像と「その下に(猫の画像の)スケッチ」の指示を与えるだけで、上部に元画像、下部にそのスケッチというアウトプットを出すことができています。人間にとってこの場合にして欲しいことは明らかですが、AIにとっては必ずしも訓練されたタスクではなく、DALL-Eが難なく行えるのは画期的といえます。
![]()
2. DALL-Eの実用可能性
言葉による指示で思い通りの画像が手に入るDALL-Eは、実用可能性の非常に高いツールといえます。冒頭で述べたインテリアデザイナーの例のように、ファッションデザインや装飾のアイデアが欲しい場合にDALL-Eは非常に役に立つでしょう。現時点ではあくまで出発点となるアイデアを供給する役割に限られていますが、将来的により洗練された、そのまま商品化できるような画像が生み出せるようになると期待されています。
またプレゼン資料や発行物に用いるデザイン素材への実用化も考えられ、現にPowerPointを開発したMicrosoftは、OpenAIに10億ドルの資金援助を行ったほか、GPT-3を独占ライセンスする契約も結んでいることが伝えられています。
3. DALL-Eの応用
GPT-3を基盤とするDALL-Eのテクノロジーは、他のメディアへの応用も期待されています。中でも音声による指示をもとにそれらしい映像を作り出し、映画の製作段階や撮影中のアイデア交換に役立てたり、またはアニメ製作の効率を大幅に上げることができるのではと予測されています。
------------------------------------------------------------------------------------------------------------------------
いかがでしたでしょうか。現段階でDALL-Eの詳しい構造やデータを見ることはできませんが、DALL-Eを紹介しているOpenAIのブログで指示を色々変えて画像を生成することができるので、是非試してみてくださいね。
openai.com
参考文献
- https://openai.com/blog/dall-e/
- https://onezero.medium.com/take-a-look-at-how-far-image-generation-a-i-has-come-in-just-5-years-236511618ca
- https://towardsdatascience.com/dall-e-explained-in-under-5-minutes-327aea4813dd
- https://medium.com/towards-artificial-intelligence/dall-e-generate-images-from-text-captions-inspired-by-gpt-3-and-image-gpt-from-openai-aacd7cd46e03
- https://cloud.watch.impress.co.jp/docs/column/infostand/1300673.html
- https://venturebeat.com/2021/01/16/openais-text-to-image-engine-dall-e-is-a-powerful-visual-idea-generator/
Onplanetz株式会社では一緒に働く仲間を募集しています
/assets/images/3146513/original/a34f682c-45c9-4656-92d4-cd5fe6832c71?1539169241)


/assets/images/3146513/original/a34f682c-45c9-4656-92d4-cd5fe6832c71?1539169241)


/assets/images/3146513/original/a34f682c-45c9-4656-92d4-cd5fe6832c71?1539169241)


