/assets/images/4781318/original/17d59443-2f48-4535-afdf-75bd8f7b54f4?1584514667)

LeapMind株式会社では一緒に働く仲間を募集しています
みなさんこんにちは!サマーインターンとして2ヶ月間課題に取り組んだ、脇坂と申します。
今回のインターンでは Blueoil Division と呼ばれる部署に所属し、メンターの飯塚さん、Wasinさん、僕と同じくインターン生の春日さんとともに課題に取り組みました。
以降では、僕達が取り組んだプロジェクトについて説明させていただきます。
プロジェクト概要: Blueoil を用いた顔表情識別プロジェクト
僕達の目標は、OSS である Blueoil を用いて、人物の含まれる画像から顔領域を抜き出し、その顔の表情を識別するデモを作成することでした。これまで Blueoil を用いて表情識別する試みは行われていなかったようで、本プロジェクトの成果によりバイナリ量子化NNでの表情識別の精度及び推論実行性能が評価できるようになります。また、デモは DE10-Nano FPGA ボード上でリアルタイムで行うため、それなりの性能を求められます。具体的には、
- - 10 FPS 以上
- - 推論精度50%以上
を要求され、特に前者のリアルタイム性を達成するのが難しいポイントです。
今回は春日さんと2人での取り組みであったため、僕は主に顔表情識別の部分を担当し、春日さんにデモの高速化をお願いしました。
まず最初に、FER2013 データセットを用いて学習ができるようにデータセットローダーを実装しました。FER2013 では、48x48 のグレースケールの顔画像を Angry, Happy, Fear などの7つの表情クラスに識別するタスクになります。
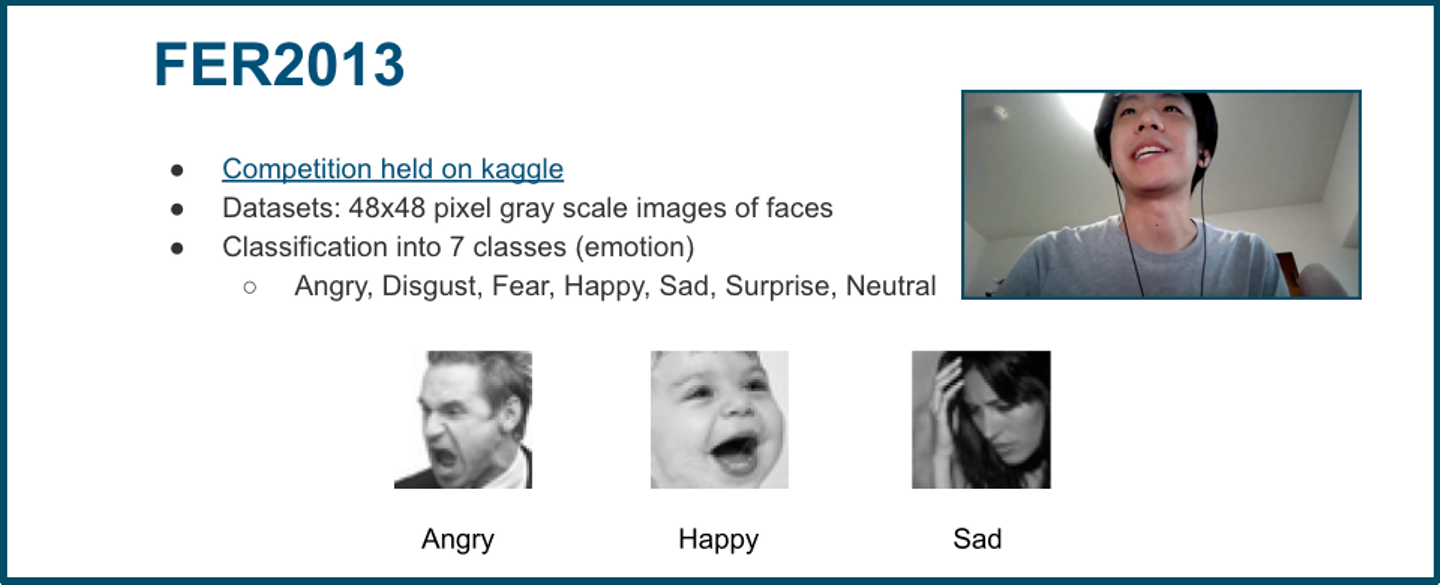
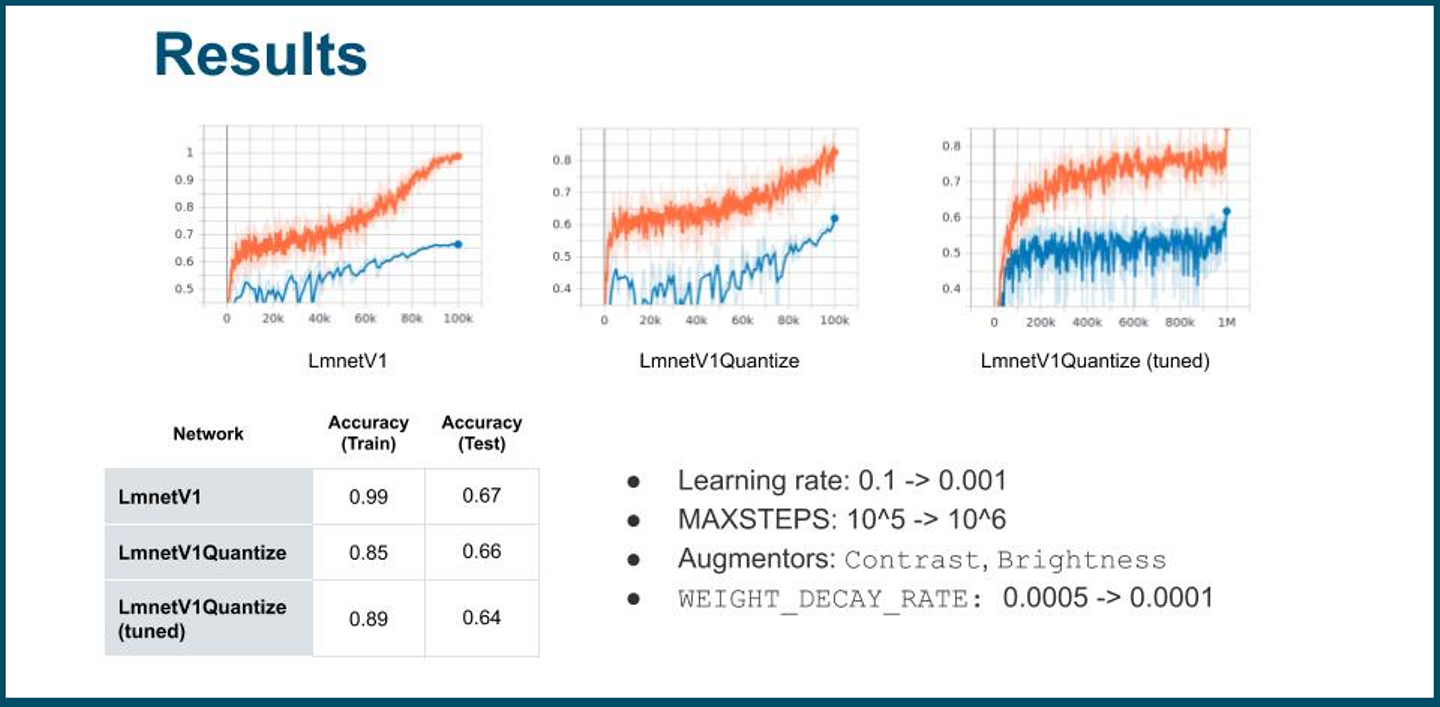
Blueoil に参考になる実装もありましたので、データセットローダーの実装はあまり難しくありません。また、学習に使うネットワークは Blueoil に実装されている既存の LmnetV1(Quantize) を用いました。学習のパラメータを調整したり、augmentor を利用して過学習を避けるようにし、学習したモデルについての評価・議論を社内ブログ記事としてまとめたりしました。
また、インターンの後半では、プロジェクトで予定していたタスクを超えて、複数の推論モデルを実行するための環境について議論をすすめました。最終的には、社内ではまだ誰も試みていなかった複数モデルの実行を実現しました。さらに、実行の手順などのドキュメントを社内ブログにまとめ、引き継ぎがスムーズに行えるようにしました。
結果
ここでは、学習したFER2013のモデルの推論精度および推論速度について、量子化あり・なしでの変化を比較します。まず最初に、推論精度について比較します。今回のモデルは FER2013 の Train データを用いて学習し、PublicTest データを評価用のデータとして用いました。また今回は分類タスクですので、指標には Top1 Accuracy(最も重みが高い値が正解と一致するか)を用いて評価を行います。
推論精度 [%]量子化なし量子化ありTop1 Accuracy66.466.2
Figure 1. 推論精度の比較 / Top1 accuracyを指標とする
この結果から、意外にも量子化を行ったとしても精度がほとんど変わらないという結果になりました。個別のデータを見てみると、Angry, Happy, Surprise といった表情筋を大きく動かす表情の精度は比較的高く、Disgust, Fear といった繊細(あるいは曖昧)な表情の精度は低いという結果になりました。
次に、推論速度を比較します。推論速度の計測は DE10-Nano FPGA Board 上で行い、10回分の実行時間を平均化した値で比較します。
推論速度 [ms]量子化なし量子化ありx86_64 (AVX)11.7713.987FPGA, ARM325.37914.029
Figure 2. 推論速度の比較
表にあるとおり、推論速度については FPGA 上では約23倍もの高速化が見込めました。精度結果と合わせると、推論精度をほとんど落とすことなく高速化できていることになります。
まとめと将来の課題
春日さんの成果もあわせると、最終的に以下の当初の目標を達成することができました。
- - Blueoil を用いた顔表情識別
- - FPGA 上でのリアルタイムかつ高精度な顔検出・識別タスク
またこれらの課題を解決するに過程の副産物として、既存のソースコードに含まれるバグやドキュメントの修正、新しいタスクのためのドキュメント整備を行いました。
今後の課題としては、例えば以下のようなものが挙げられます。
- - 表情識別モデルの改善
- - 複数モデルを動作させる際のユーザビリティの向上
- - 複数モデルの実行
1つ目の表情識別モデルの改善についてですが、今回は既存のネットワークの構造自体には深入りせず、パラメータの調整だけを行っていました。2020年現在、SOTA (追加データなし)は 72.7%ですので、改善の余地があると考えます。パラメータの調整だけでは限界が見られるので、より精度の高いモデルを得るためにはネットワーク構成から見直したほうが良さそうです。
2つ目の課題は、今回のように複数モデルを動作させるようなタスクにおいて、よりユーザビリティを高めるようなツールを提供することです。現状は変換で生成される設定ファイルやソースコードを人間が手動で書き換える必要があるのですが、少しややこしい手順になるので機械的に行うのが理想です。本プロジェクトの後半では、僕は主にこのタスクについて取り組んでいましたが、時間やタスクの規模の関係で完遂することはなりませんでした。資料などは残してあるため、次の作業に役立てていただければと思っています。
最後の課題としては、複数の推論モデルを並列実行できるようにすることが挙げられます。ただし、この問題を解決するには、並列実行できるようにするためのコストとのトレードオフがあること、そもそもの IP の設計の見直しなど非常に大きなプロジェクトになると考えられます。
インターンを振り返って
実は僕は機械学習に全く取り組んだことがない人間でしたので、今回このようなタスクに取り組むにあたって少し不安を抱えていました。しかしながら、メンターの飯塚さんや Wasin さん、その他フルタイムメンバーの皆様が僕の質問に真摯に対応してくださり、なんとか目標を達成することができました。2ヶ月間、普段取り組まない新しいことに挑戦でき、刺激的な毎日で楽しかったです。この場を借りて、皆様に感謝申し上げます。
今回のインターンで学んだことは、チームメンバーと協力して作業に取り組むことと、能動的に課題を見つけようとすることの大切さです。実際、インターン中はミーティングなどを通してメンバーが取り組んでいる問題を共有し、次に取り組むべき課題を見つけることが多かったです。また自らで課題を見つけてそれをチームで共有する中で新たな試みが生まれ、当初の目的以上の成果を上げることもできました。こうした経験は長期のチーム開発でなければ得ることが難しい貴重なものだと思います。
最後に
本インターンは、今後より需要が高まっていくとされるエッジコンピューティングの分野に深く触れる機会になると思います。またインターン生であっても、能動的に新しい課題を見つけて取り組むことのできる環境です。深層学習や、それを実デバイスで動かすことに興味のある皆様は、ぜひインターンにご応募ください!
共同研究を行った春日さんのブログはこちらからぜひご覧ください!
References
https://github.com/blue-oil/blueoil/pull/1172
https://github.com/blue-oil/blueoil/pull/1177
https://github.com/blue-oil/blueoil/pull/1185
Facial Expression Recognition with Blueoil
/assets/images/4781318/original/17d59443-2f48-4535-afdf-75bd8f7b54f4?1584514667)