/assets/images/1698386/original/821abe46-7e4c-4e35-bbcc-c4f459678505?1680567510)
LAPRAS株式会社では一緒に働く仲間を募集しています
こんにちは。LAPRAS社のシニアエンジニア、データベーススペシャリストの山田(@denzowill)です。以前書いたこちらの記事は古くなってきた上に、scoutyから社名まで変わってしまったので、最新のLAPRASでの状況を改めてご紹介させていただきます。更新のついでに折角なので数は10->20で2倍にしました。
全体図
まず先に、LAPRAS社のサービスを取り巻く状況がどのようになっているか、全体の構成をお伝えします。
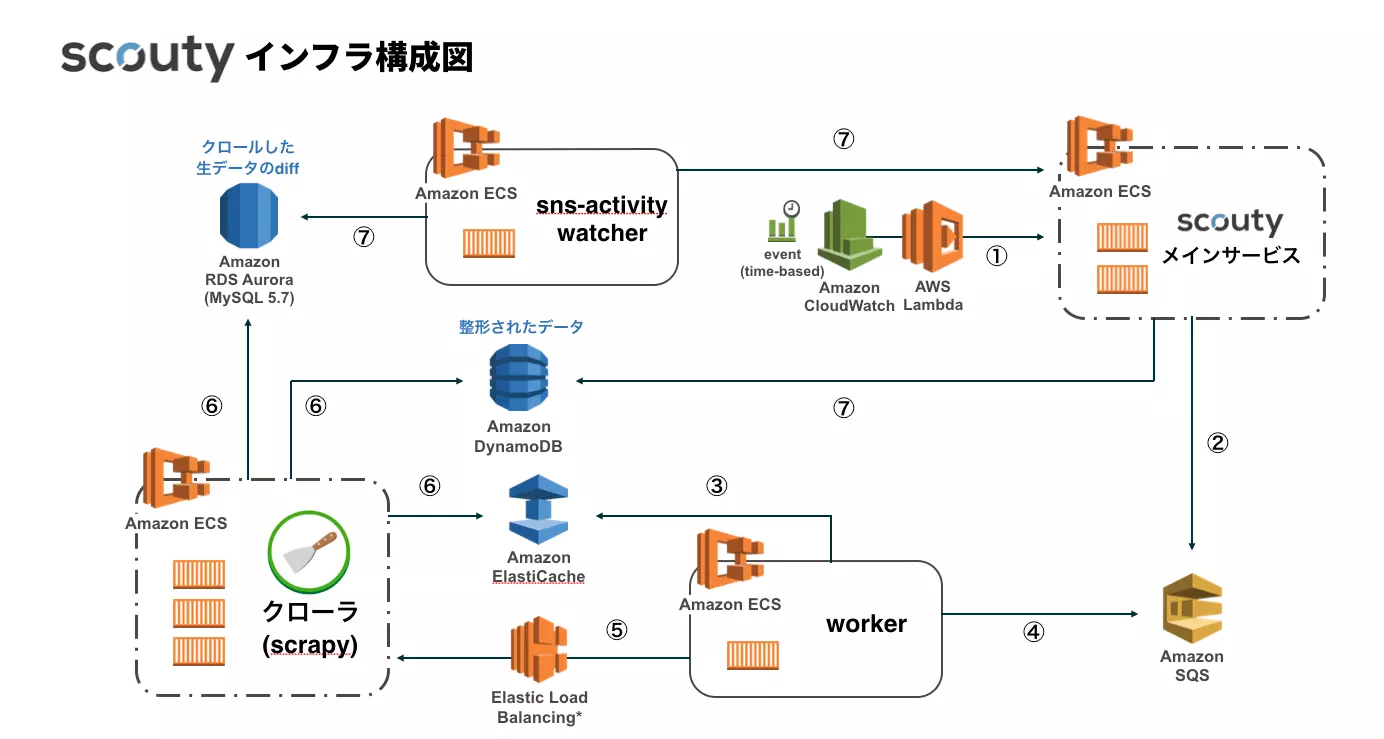
以前の構成はこちらでした。
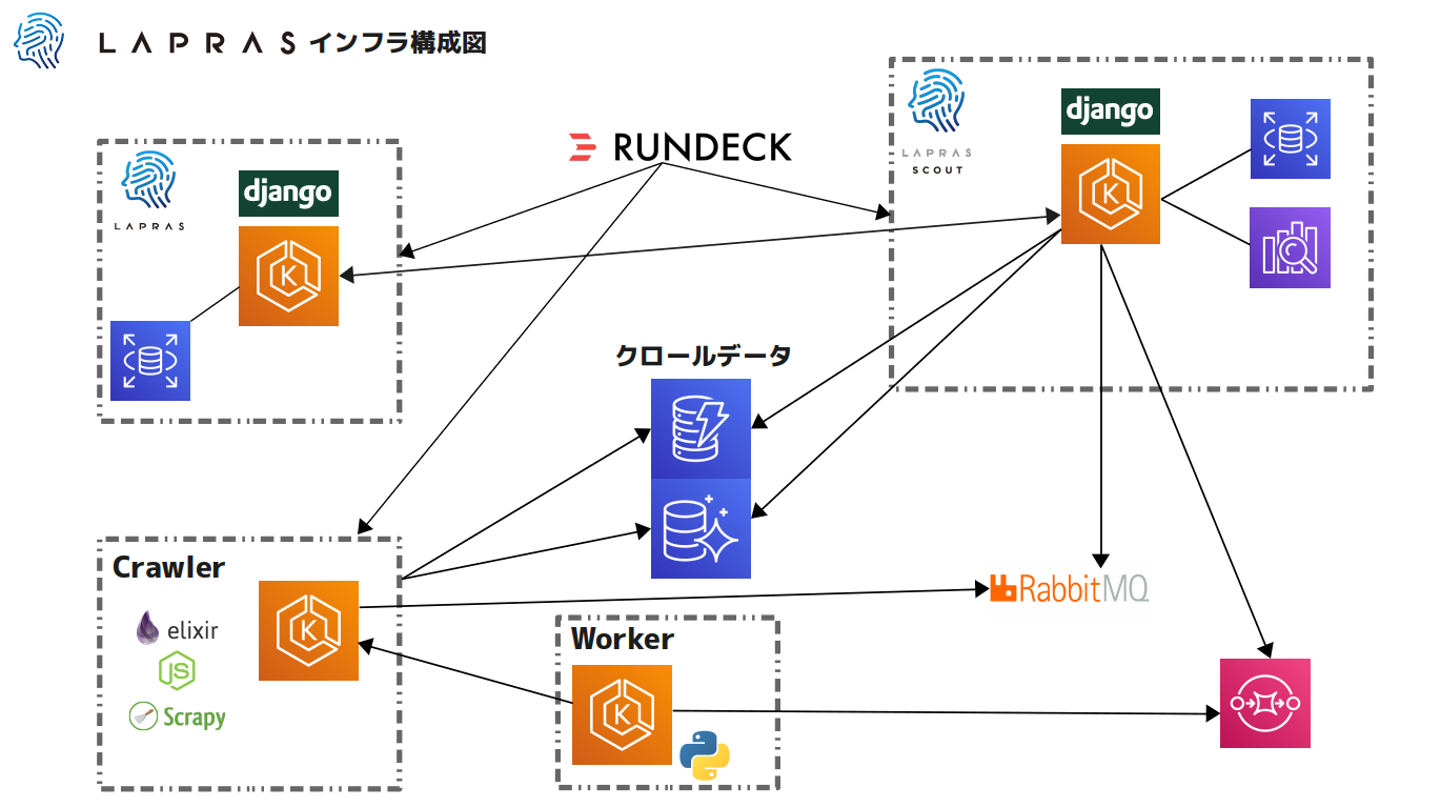
前回記事を書いてから大きく変わったところとしては以下です。
* 従来のscoutyというサービスがLAPRAS SCOUTにリニューアル
* toCのLAPRASというサービスが新規公開
* ECSからk8sへの移行
このあたりに触れながら現在の状況を紹介していきます。
利用言語
LAPRAS社はscouty時代からPython3系をメインで採用しています。Web系は依然としてPython3系をメインで使用していますが、クローラ側はいくつかの技術的課題の解決(や担当エンジニアの嗜好)もあり、一部にNode.jsやElixirも導入されています。
インフラ関連

Amazon EKS / Amazon ECS
以前はAmazon ECS上でサービスを稼働させていましたが、現在はEKSに完全移行し、すべての社内のインフラをkubernetes(以降k8s)で稼働させています。ECS + Fargateも悪くないのですが、LAPRAS社がECSを利用していた当時はサービス毎にALBが1台しか作れない制限があり、そのため複数のサービス間で通信をさせようと思うと、それぞれサービスを建てなければいけないため最終的にk8sへ移行しました。
Amazon SQS / RabbidMQ
メインサービスとクローラ間でのクロールリクエストの連携のため、SQSを以前から利用しています。ただし、SQSでは優先度キューが利用できないなど不満な点もあるため、一部のクローラではRabbidMQを利用しています。RabbidMQはAWSのマネージドサービスがないため、自分たちで構築しています。
Rundeck
バッチ処理等、定期実行系のジョブはRundeck経由で実行しています。以前はAmazon CloudWatch + Lambdaで実装していましたが、Rundeckになってからはかなり管理が楽になりました。また、Rundeckは通知系も充実しているため、失敗したジョブをSlackで通知するなども簡単にできるため気に入っています。
余談ですが、Rundeckからはkube-jobというOSS(@h3_poteto作)を利用しEKS上のJobを起動させる構成にしています。k8sのJobだけでもスケジューリングから実行まで可能ですが、上述のようにRundeckではジョブの実行結果の連携等がやりやすいため現在の構成にしています。
Terraform / k8s
引き続きLAPRAS社のAWS上のリソースはTerraformで管理されています。ただし一部のリソース、特にALBについては、k8sのIngress Controllerで構成するほうが何かと便利なためTerraformの管理外としています。EKSの構成等はTerraformで行い、デプロイ周りの設定はk8sで行っています。
いずれにせよ、殆どのインフラ系リソースはコード管理がされています。
サービス関連

LAPRAS社のメインサービスであるLAPRAS SCOUT(企業向けサービス)とLAPRAS(個人向けサービス)の利用技術です。
Django(LAPRAS SCOUT/LAPRAS)
以前はDjango 1.11 LTSを利用していましたが1.11 -> 2.0 -> 2.1とバージョンアップを行いました。Django 2.1も2019年12月でEOLですので、近いうちにDjango 2.2にバージョンアップする予定です。
Django Channels(LAPRAS SCOUT)
DjangoでWebSocketを利用する際のライブラリです。国内事例は少ないですがLAPRAS SCOUTでは2018年8月より本番での利用を続けています。一時期Channelsは開発継続が危ぶまれましたが、現在は開発は問題ないようです。
Vue.js(LAPRAS SCOUT/LAPRAS)
LAPRAS SCOUTのフロントエンドはVue.jsを利用したSPAになっています。Nuxt.jsは使用せず、生のVue.jsのまま使用しています。サーバサイドレンダリングが要件になかったことや、webpack等の設定を自分たちで明示的に行いたかったことが理由です。
TypeScript
LAPRAS SCOUTはVue.js + Javascriptの構成ですが、LAPRAS側ではVue.js + TypeScriptの構成を取っています。TypeScriptのおかげでVuexとAPI周りを堅牢な構成にすることができたため、LAPRAS SCOUT側もTypeScriptの導入を予定しています。
gRPC
LAPRAS SCOUTとLAPRASでは一部でデータを連携する必要がありgRPCを採用しています。LAPRAS SCOUT側のDjangoをそのままgRPCに対応させ、gRPCサーバとして運用しています。このあたりはあまり事例がないので、どこかでLAPRAS社での取り組みを公開できればいいなと思っています。
クローラ関連

LAPRAS SCOUT / LAPRASは、複数のSNSから情報を収集するためのクローラが動いています。基本的にシステム間連携が必要になるため、クローラ + クローラを内包するAPIサーバの構成になっています。もともとのクローラに加えていくつか実験的な部分があるため、複数のアーキテクチャが存在しています。
Scrapy / Scrapyd
クローラは以前からメインにScrapyを採用しています。ScrapyはTwisted(イベント駆動型のネットワークプログラミングフレームワーク)をベースにしているため癖はありますが、SPAのサイトがクロール先でなければScrapyは必要十分な機能を提供しています。Scrapy自体はCLIとしてクローラを呼び出す作りであるため、ScrapyにWebAPIを加えるScrapydをあわせて利用しています。
puppeteer / Express
ScrapyはSPAのサイトをクロールするには不向きです。そこで、Chromeのヘッドレスブラウザを扱うNode.jsのライブラリであるpuppeteerを、一部のクロールに採用しています。また、WebAPI提供のためNode.jsではメジャーであるExpressを組み合わせています。
Elixir / trot
一部のSPA対象ではないクローラでは実験的にElixirでフルスクラッチしています。スクラッチしたクローラに対するWebAPIを提供するためtrotを採用しています。今後のクローラ開発がElixirメインに変わっていくかは未定ですが、Webサービス側とクローラが粗結合であるからこそいろいろな試みが出来ています。
まとめ
1年ぶりにLAPRAS社での技術スタックを紹介させていただきました。Python / Djangoという主たるところは変わっていません。それでもElixirやNode.jsの採用、あるいは創業以来採用してきたECSからk8sへの移行等、大きな変化もありました。
もし来年またこの記事を書くとすれば、更に色々変わっていると思います。LAPRAS社では、次の1年の変化をより良いものにしていけるエンジニアを絶賛募集中です。もし興味ありましたら是非一度オフィスに遊びにきてください。もっと詳しい技術スタックのお話や組織のお話ができると思います。
エンジニアの採用要件はこちらです!: Webエンジニア - 2019秋
LAPRASを支える約20個の技術


