こんにちは、scoutyのシニアエンジニア(DBスペシャリスト)の山田(@denzowill)です。私は昨年の夏頃にscoutyのサービスを通じてscoutyに転職しています。さて、エンジニアが転職する時に気にするポイントの一つに、その企業が「どのような技術を使っているのか」という点があると思います。
現在は私も他のエンジニアの方とカジュアル面談をすることが増えていますが、「使用言語は?」、「インフラ周りはどうしているのか」、「フレームワークは何を採用しているのか」といった質問をいただくことも多いです。
そこで今回はscoutyを支える約10個の技術と題しましてどのような技術スタックをscoutyが採用しているかをご紹介します。
全体図
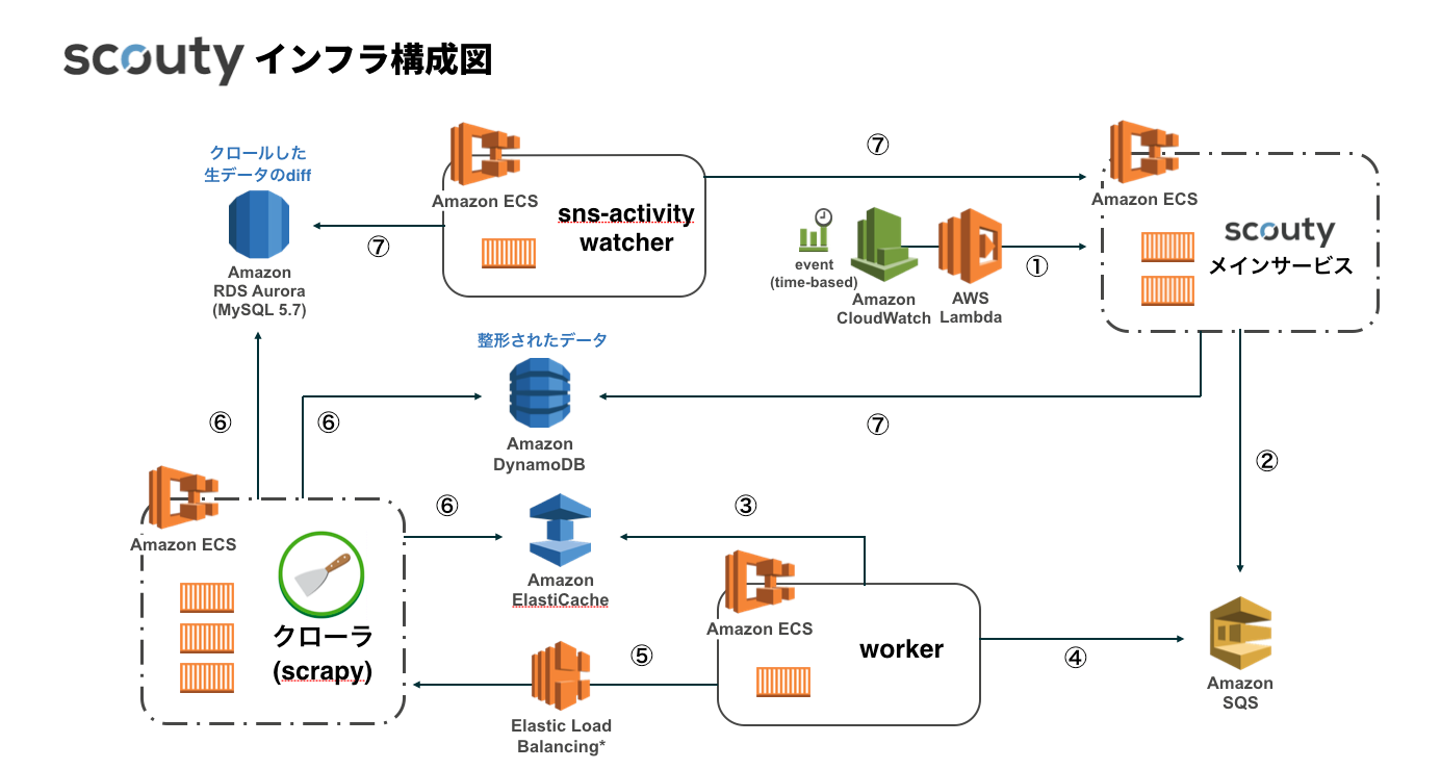
まず先にscoutyというサービスがどのような構成になっているかをご紹介しておきます。
![]()
ユーザ側にWEB上でのサービスを提供するメインサービスと、各SNSをクロールしてデータを収集するクローラが主要なコンポーネントです。これを中心に詳細を見ていきます。
利用言語
scoutyではほとんどの部分(フロントエンド以外のほぼ全て)でPython 3.6を採用しています。もともとのプロトタイピングをPythonで行ったという経緯もありますが、機械学習部分の組み込みが容易になる点や、開発メンバーがいずれのコンポーネントであっても容易に移動できる点からPythonで統一しています。
インフラ関連
先程の構成図からもわかりますが、scoutyはAWS上でサービスを構成しています。
Amazon ECS
scoutyでは、本番のサービス(メインサービス、 クローラ)はもちろんローカルの開発環境も含めてすべてDockernizeされています。ECSを利用することで、ローカルと本番環境をほぼ同じ形で運用できるようにしています。
Amazon SQS
メインサービスとクローラ間ではクロール対象の情報をキューを使ってやり取りしています。この部分にSQSを採用しています。Apache ActiveMQの利用も検討しましたが、扱いやすさや送信メッセージのサイズがそれほど大きくない事を踏まえSQSを採用しています。
Amazon CloudWatch / Lambda
データの更新処理等、一部処理は定期的なジョブとして実行する必要があります。その際のジョブスケジューラとして、CloudWatchのSchedule EventとLambdaを組み合わせて利用しています。
Terraform
もともとは手作業、あるいはお手製のBoto3スクリプトで管理していました。しかし、先日SREがジョインしてくれたおかげで大半がTerraformで作成されるようになり、テスト環境等も容易に構成できるようになりました。
メインサービス(サーバサイド)
WEBアプリケーション部分はDjangoのLTS版を採用しています。ORMも組み込みのものを使用しています。
scoutyでは50以上のAppがINSTALLED_APPSに登録されています。単一サービスとしてはかなり多いのではないでしょうか。これは、実際に50種類のサービスを提供しているのではなく、マッチング処理やメール送受信、候補者管理といったドメイン単位でAppを作成しているためです。このように細かくAppを切ることでDjango上でDDDライクな開発を行っています。
Django自体はかなり著名なフレームワークで利用者も多いですが、Channelsは少し珍しいかもしれません。ChannelsはDjangoでHTTP以外(WebsocketやMQTT)のプロトコルを利用可能にするライブラリです。scoutyでは現在最新の2.1系を採用しています。候補者管理の部分を複数の担当者間でコラボレーションできるようにWebsocketが必要になり、この春より採用しました。
まだまだ国内では採用事例が少ないですが(特に2系は)、癖が少なく使いやすいライブラリですので、Django上でWebsocketを使用する必要がある場合はChannelsを使っておけば問題はないと思います。
もちろん前段にはリバースプロキシとしてNginxを立てていますが、WSGIのアプリケーションサーバとしては長らくuWSGIを採用していました。
しかし、Channelsを利用するためにはWSGIプロトコルを拡張したasgiプロトコルに対応したアプリケーションサーバが必要でした。そのため、Channelsの採用とあわせてASGIに対応したdaphneでアプリケーションサーバをリプレースしています。daphneもuWSGIに比べると実績が少ないプロダクトですが、scoutyで運用して出た問題点等をコントリビュートできればと考えています。
メインサービス(フロントエンド)
昨年から提供していたベータ版の開発時は専任のフロントエンドエンジニアがいなかった関係もありjQueryを中心としていました。しかし、年始よりフロントエンドエンジニアがJOINし、全面的にVue.jsを使用したSPAへ移行しています。
クローラ
scoutyの肝であるクローラについては、クローラ界のDjangoことScrapyを採用しています。Scrapyは実行間隔やキャッシュの利用方法等様々なカスタマイズができるクローラ用のフレームワークです。
Twistedというイベント駆動型のネットワークプログラミングフレームワークをベースにしており、WEBサイトからのデータ取得やクローリング等が非同期で行われます。それ故に、クロール処理(ScrapyではSpiderと呼ばれる)のコーディングは少し独特です。慣れるまでは少し戸惑いますが、処理間の各タイミングに対してDjangoのように独自のミドルウェアの処理を挟む事ができるなどかなりの拡張性がありとても強力です。
scoutyでは、独自のミドルウェアでOAuthが必要なAPIへのアクセスの実現や、取得した生データをログとして透過的にRDBに格納する処理等を追加しています。
また、scoutyでは各種SNS、各種APIに対応するため約20種類のSpiderを実装しています。また今後のサービス拡張にあわせて増強していく予定です。
Scrapy自体はコマンドラインからscrapyコマンドを通して実行します。そのため、そのままではマイクロサービス化して他のサービスと連携しづらい形になっています。連携を考えると、HTTPでのエンドポイントが欲しくなります。Scrapydは、Scrapyで作成したクローラに対してWEBベースの管理画面やエンドポイントを提供してくれるライブラリです。管理画面こそ、切なくなるほど質素なデザインですが、ジョブのキャンセルや現在の同時実行数等、十分なAPIが提供されています。
scoutyではScrapy + Scrapydを構成したDockerコンテナをECS上で起動して運用しています。
まとめ
いかがでしたでしょうか。scoutyはB2Bのサービスを提供している関係もあって、比較的実績を重視した技術スタックになっていますが、その中でもChannelsやScrapy等のチャレンジングな技術も採用しています。
またサービスとは直接は関係しないものの、開発の運用周り等ではメンバーが独自に作成したツール等も利用しており、いろいろ技術的に楽しめる風土があります。現在エンジニアチームは7名ですが、2019年春までには合計12名(2チーム)の開発組織を目指しておりまだまだ採用活動中です。
Pythonを中心に置いてはいますが、メンバーの多くが他の言語からのコンバートをしていますのでPythonが書けなくても、楽しく技術をやりたいエンジニアの方であれば是非一度オフィスに遊びにきてください。もっと詳しい技術スタックのお話ができると思います。
LAPRAS株式会社では一緒に働く仲間を募集しています