/assets/images/8249870/original/380fffc4-e211-44ab-93bb-31d8ce4739ac?1638520438)

株式会社エブリーでは一緒に働く仲間を募集しています
皆さまこんにちは、エブリーの荒井と申します。DELISH KITCHENのサーバサイドを担当していて、主にAPIサーバの開発や検索周りの改善・Alexa対応を行なっています。
簡単に自己紹介しますと、新卒で名刺管理サービスを開発する企業に入社し、toB向けのアプリケーション開発に携わっていました。より人数規模が小さく、伸びているサービス開発で揉まれたい気持ちがあり、3ヶ月程前にエブリーに入社しました。
今回は、先日リリースしたばかりのAlexaスキル開発に関する話をします。スキルを開発したことが無い方が大半だと思いますので、基本的な話から始め、開発をしながら見つけた気づきをご紹介します。音声設計に関する記事はよく見かける印象ですが、使用技術などに関する話はあまり見かけないため、技術の話を中心にしています。
目次
- 前提知識
- スキルが動くまで
- 必要な実装
- 実装における制約
- システム構成と思うところ
- 構成
- 開発言語について
- DBについて
- ログ収集について
- その他
- 音声設計で心がけたこととジレンマ
- 心がけたこと
- Utteranceのバリエーションと誤認識のジレンマ
- おわりに
前提知識
スキルが動くまで
Alexaスキルでは、ユーザの発話を受け付けてから、返答が行われるまで以下のような流れを辿ります。
- ユーザがAlexaに対して発話する
- (事前に受け付けるセンテンスとして登録されていた場合)Alexaが発話を受け付ける
- 発話に紐づけられた関数を実行し、返答に利用するレスポンスを生成する
- Alexaが関数から返却されたレスポンスを利用して、ユーザーに対して応答を返す(テキスト/音声/ビデオ)
Alexaの開発用語に言い換えると、「事前に受け付けるセンテンス」は「Utterance」。「発話に紐づけられた関数」を「Intent」と呼びます。(以降はこれらのワードを使って説明を進めます。)

必要な実装
大きく分けて、以下の2つです。
- Utteranceの設計・定義
- Intentの実装
実装における制約
制約は、request・responseのインターフェースを守ることくらいです。
インターフェースを守れば、基本的にはいかようにも実装できます。言語は何でも良いですし、Lambdaを利用したサーバーレスな構成にしなくても大丈夫です。
システム構成と思うところ
今回は、ディレクター・開発ともに1名ずつで、タイトなスケジュールの中開発を行いました。
スキルでは、レシピ動画の音声を使っており、AudioPlayerインターフェースも利用しています。
構成
構成は以下のようになっています。
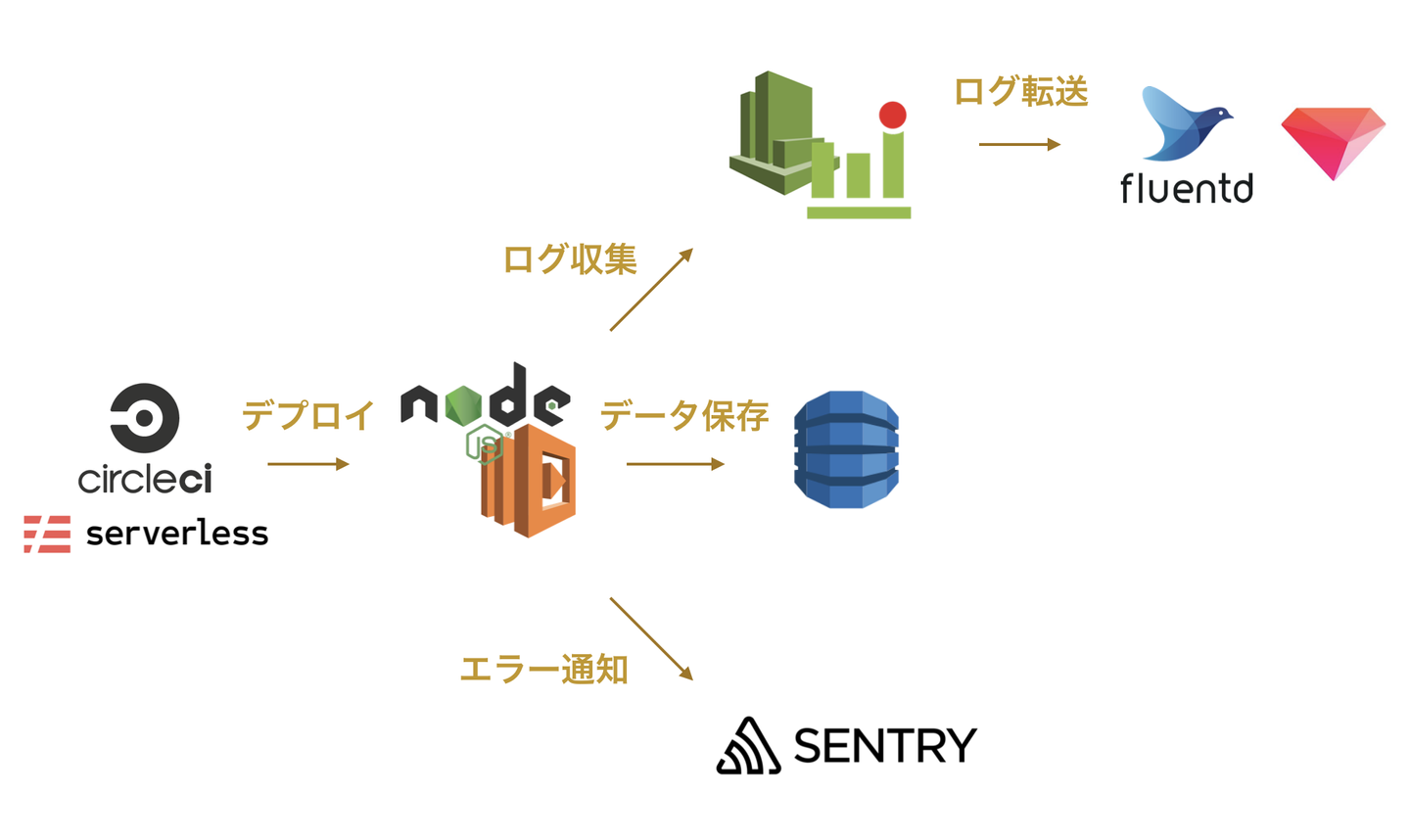
- 開発言語 : Node.js(Lambda)
- DB : DynamoDB
- 監視 : Sentry・CloudWatchAlarm
- ログ収集・分析 : CloudWatch -> fluentd -> TreasureData
- デプロイ : serverless・CircleCI
開発言語について
今回は、LambaのNode.jsを利用し、公式のSDKも利用しました。
最速でリリースするために、情報が豊富な言語・ライブラリを選択しました。
ちなみに、PythonやJavaのSDKもあります。情報もそれなりに転がっている印象です。
- Java : https://github.com/amzn/alexa-skills-kit-java
- Python : https://github.com/johnwheeler/flask-ask
DBについて
Node.jsのSDKにはDynamoを操作する機能が備わっており、他の選択肢もあるため利用自体は非常に簡単です。
ただ、(AutoScaling機能を利用しない場合ですが)Read/Write Capacityを事前に設定する必要があります。計算が難しく、必要最小限の設定を見つけるのに苦労しました。
CloudWatchに消費Capacityが表示されるため、最初の段階ではメトリクスに示される最大値を参考に設定を行いました。しかし、必要なCapacityより遥かに大きな値を示し、あまり参考になりませんでした。
結局、各テーブルのCapacityを最小にした上で、AWS CLIからテーブルの更新や読み込みを連続で実行し、大体の限界を把握してCapacityを設定しました。
費用を最小限に抑える必要があり、DynamoDBを組織で初めて導入する方などはご注意ください。
ログ収集について
想像以上に面倒なのがログ収集の部分です。DELISH KITCHENでは、TreasureDataにログを集めることが多く(詳しくはこちら)、今回もTDを利用したいと考えています。
CloudWatchにログを吐き出すところまでは自動であり、CloudWatchには、標準でS3にログを出力する機能があります。「S3に出力されたログをTD標準の機能で収集すれば良いはず!」だと思っていたのですが、うまく行きませんでした。Lambdaが勝手に出力するログがあるためです。
例えば以下のようなログです。
REPORT RequestId: xxxxxxxxxxxxxxxxxxxx Duration: 47.00 ms Billed Duration: 100 ms Memory Size: 1024 MB Max Memory Used: 56 MBTDには、JSONやCSVなどの限られたフォーマットに統一してインポートしなければなりません。ですので、転送前にフォーマットが合わないログを除いておく必要があります。
形式が適さないログを除外する設定や、CloudWatchからログを受け付けるプラグインが存在するfluentdを利用し、ログ収集・集計・分析を行おうと考えています。
その他
今回はLambdaを利用したため、AWSのサービスを中心とした構成になっていますが、サーバーを立ててスキルを構築することもできます。
例えば、以下のライブラリは良さそうです。
https://github.com/alexa-js/alexa-app
音声設計で心がけたこととジレンマ
心がけたこと
ユーザーがAlexaと自然に対話できることが大切だと思っています。
例えば、以下のように、何か特定の操作を行う際にユーザのUtterance(発話)を限定してしまうのは不自然です。
オススメのレシピ、あなたが食べたい食材、料理名でレシピを検索できます。何をお調べしますか?オススメのレシピを聞きたい場合は、「オススメのレシピ」。レシピを検索したい場合は、「豚肉のレシピを検索」と言ってください。
また、ここで「豚肉のレシピを探して」など例示したUtterance以外をトリガーにレシピを検索出来ない場合、自然な会話が成り立たず、利用しやすいとは言えません。
そこで、なるだけ発話のバリエーションを受け付けるようにしました。
DELISH KITCHENでは、以下のような対話が成り立つようになっています。
オススメのレシピ、あなたが食べたい食材、料理名でレシピを検索できます。何をお調べしますか?
(ユーザー)
「今日のおすすめ」/「おすすめを教えて」/「おすすめを頼む」/「豚肉の」/「豚肉」/「豚肉のレシピを教えて」/「豚肉のレシピを検索」etc...
バリエーションの確保を行うと膨大な量になると思いますので、ツールがあると便利です。必要最小限の機能を備えたツールがありますので、良ければご利用下さい。
- alexa-utterances: https://github.com/alexa-js/alexa-utterances
Utteranceのバリエーションと誤認識のジレンマ
「発話のバリエーションを豊富にして、自然な対話を成立させるべき」という主張を続けてきましたが、バランスが難しい部分があります。
DELISH KITCHENでは、レシピ名・材料名での検索機能があり、1万件以上の検索ワードに対応しているのですが、バリエーションの豊富さ故に、適当な言葉もレシピ/材料名として認識しようとしたり、意図しない言葉として認識されることがあります。
例えば、「ああ〜」という適当な言葉を認識すると、Alexaがレシピ検索していると判断し、「あおさ」のレシピの検索が行われることがあります。
あえてバリエーションを抑えるべきフローもありました。
例えば、「レシピ検索→(最大3種類の)選択肢の提示→レシピの選択・音声を聴く」フローです。自然な対話を成立させるには、「レシピの選択」部分で、提示した料理/材料名でレシピを選択できると、より自然だと思いますが、あえて対応していません。適当な言葉を受け付けたり、意図しないレシピが選択され、かえってユーザの体験を悪くしてしまう可能性があるためです。
おわりに
今回は、Alexaスキル開発の前提知識からシステム構成、具体的な実装方法までをご紹介しました。
まだまだAlexa関係の情報は少ないので、今回のまとめが皆さんのお役に立てば幸いです。
エブリーは、このようなチャレンジングなプロジェクトを入社後すぐ担当できる楽しい環境です。少しでも「興味がある」/「オフィスに遊びに来たい」/「Alexaについて話したい」...という方は、下記リンクからご連絡下さい。お待ちしております!
DELISH KITCHENでAlexaスキルに対応した話

/assets/images/8249870/original/380fffc4-e211-44ab-93bb-31d8ce4739ac?1638520438)



/assets/images/1894533/original/5951efdc-e0aa-4c60-993d-2e1641fecb39.png?1510565250)
