こんにちは。今年の9月からWantedly Visitでデータサイエンティストをしている合田です。
私はこの1年ほどデータ分析コンペKaggleに取り組んでいましたが、先日行われたIEEEコンペで金メダルを取り、念願のKaggle Masterになることができました。
キリのいいタイミングなので、今までデータ分析コンペでどういう取り組みをしてきて何を得られたかについて振り返ってみようと思います。
Kaggleとは
Kaggleとは、データ分析コンペのプラットフォームです。主催者となる企業がデータと分析テーマを提供し、参加者は予測モデルの精度を競い合います。コンペの規模としては世界最大であり、2019年10月時点でのトータルの参加者は約12万人にも上ります。
より詳細な話やKaggleに取り組む意義については、以下の記事が参考になります。
Kaggleを知ったきっかけ
2~3年前ぐらいに、前職の同僚からKaggleについて教えてもらったのがきっかけになります。
同僚がTitanicコンペというタイタニック号の乗客の生死予測コンペに参加しており、その話を聞いてデータ分析コンペの存在を知り少し興味が湧きました。
しかし、この時点ではデータ分析コンペってどういう形式であるものか具体的なイメージがついておらず、勉強のためにやってみようかなーと口では言いつつ(ちょっとめんどくさそうで)結局手をつけませんでした。
どんなコンペにチャレンジしてきたか
Google Cloud & NCAA® ML Competition 2018-Women's
コンペのページ:https://www.kaggle.com/c/womens-machine-learning-competition-2018
Titanicコンペの話を聞いてKaggleの存在を知ることができましたが、1人で取り組もうとすると永遠に手をつけないなと強く感じました。そこで同じ時期にKaggleに興味を持った前職の同僚2人に声をかけ、チームでNCAAバスケトーナメントの勝敗予測コンペに出場することにしました。
チーム全員が初めてのKaggle参加ということもあり、業務で行う分析の取り組みをそのままコンペで実施しました。EDA(データ調査・データ集計)を各自で行い、その結果をspreadsheetで共有してデータに関する知見を集めていきました。この時点ではGBDTを使ったことがなくRandom Forest最強だと思い込んでいたので、Random Forestモデルを1個作って提出して終了しました。
結果は505チーム中446位とほぼビリの順位でした。コンペに参加した当初は1~2日ぐらい時間をかければ真ん中ぐらいの順位になるかなと思っていましたが全然そんなことはなく、世界のレベルの高さとコンペにかける時間と熱意が他参加チームと比べてあまりに少ないことに気づきました。
Santander Value Prediction Challenge
コンペのページ:https://www.kaggle.com/c/santander-value-prediction-challenge
自分のコード:https://github.com/hakubishin3/kaggle_santander
Santander銀行が主催となったコンペです。カラム名が匿名化されたテーブルデータを使って指定されたtargetを予測します。
1年前の夏季休暇中に暇を持て余していたため、このコンペに参加しました。カラム名が匿名化されていましたが時系列っぽい雰囲気を醸し出していたので、次元圧縮や基礎統計量などの集約特徴量を採用したりして順位を上げていきました。
バスケコンペの経験から時間を使って真面目に取り組んでいましたが、コンペの途中でLeakageが発覚してから話がガラッと一転しました。その内容は、ルービックキューブみたいにテーブルの行と列を適切にスライドさせていけばモデリングをせずともtargetの値が自動的に分かってしまうというものであり、そこからはspreadsheetを使って手動でパズルを解きつつ効率化のためのアルゴリズムを書いていく毎日でした。
想像していた分析コンペと異なる展開になりましたがパズルを解くこと自体は楽しく、最終的には4,477チーム中62位で銀メダルを取得しました。初めて真面目に取り組んだコンペでのprivate leaderboard(最終順位確定用の順位表)の開示はこれが初めてで、64位という順位が見えた瞬間脳汁がドバドバあふれたことを覚えています。この瞬間から完全にKaggleに嵌ってしまいました。
Google Analytics Customer Revenue Prediction
コンペのページ:https://www.kaggle.com/c/ga-customer-revenue-prediction
自分のコード:https://github.com/hakubishin3/kaggle_rstudio
Rstudio社が主催するコンペです。Google analyticsのログデータを使用して、Google Merchandise Storeの顧客あたりの収益を予測します。
Santanderコンペでは特徴量エンジニアリングの力がないことを痛感したため、過去のコンペの解法を読み漁って特徴量の作り方を学んでいきました。またコード管理がいい加減で、作ったモデルがどんな内容か忘れて混乱することがあったので、以下の資料を参考にして実験コードの管理体制を整えていきました。
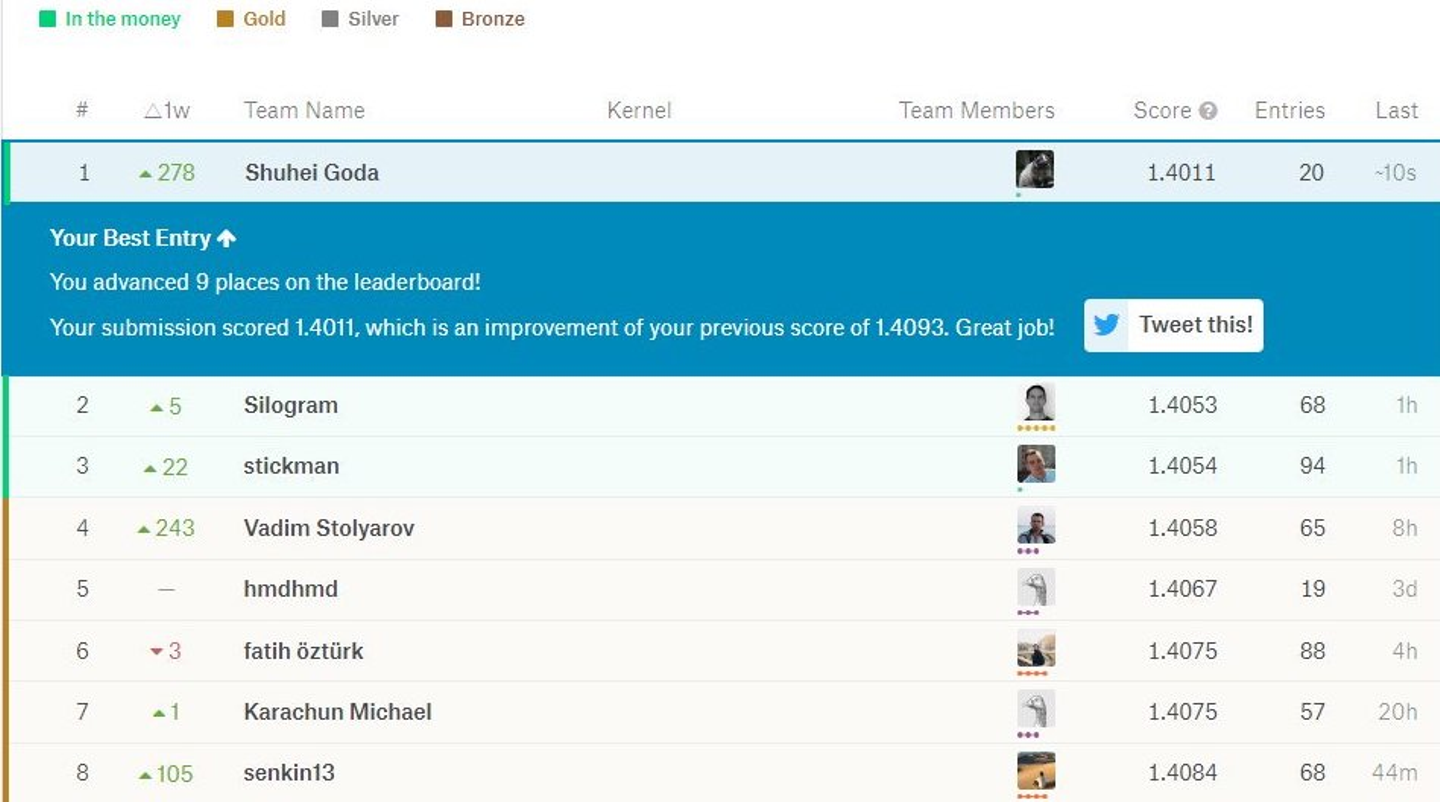
このコンペでは、期間中に1位を取ることができました。あくまでコンペ中の暫定順位であり、最終順位確定用データでの評価ではないのですが、とても嬉しかったのを覚えています。
![]()
しかし幸せな時間もそう続かず、暫定1位になってから数日後、このコンペでもLeakageが発覚してしまいます。Google analyticsのデモアカウントを使ってテストデータのtargetを取得できてしまうというものでした。Santanderコンペとは違い、このコンペはLeakage発覚後中断され、コンペの内容を変えてリスタートされました。あまりにショックな出来事で、このコンペから泣く泣く撤退しました。
このコンペの経緯と取り組みをまとめた資料です。
https://www.slideshare.net/ShuheiGoda/kaggle-tokyo-meetup-01-r-155358051
PLAsTiCC Astronomical Classification
コンペのページ:https://www.kaggle.com/c/PLAsTiCC-2018
自分のコード:https://github.com/hakubishin3/kaggle_plasticc
このコンペは企業主催ではなく、研究機関が主催のコンペです。望遠鏡のモニタリングデータから得られたflux情報を元にその光源の天体の種類を予測します。大学では望遠鏡の観測装置の開発に携わっていて天文観測データは馴染みのあるものであったため、このコンペに参加しました。
このコンペの特徴は何と言ってもデータの重さであり、テストデータが約20GBもありました。簡単な基礎統計量を取るだけでも時間がかかり、複雑な特徴量だと1日から5日ほどかかることもありました。特徴量生成に時間がかかってしまうと実験のサイクルが長くなってしまうので、このコンペからハイスペックなGCPインスタンスを解禁し、常時CPU32コアメモリ100GBのインスタンスを立てて、重い計算をする場合にリソースを更にスケールアップさせていきました。
コンペ終了間際になっても金メダル圏に到達できない私は、2人のkagglerとチームを組みました。2人とも自分と異なるアプローチで作成した精度の高いモデルを有しており、単純なアンサンブルでも劇的にスコアを伸ばすことができました。slackを使って毎日情報共有と議論を行い、出来る範囲でモデルの精度を極限まで高めていきましたが、最終的な順位は1,094チーム中16位で銀メダルでした。金メダル取得チームの下限が12位で順位上はあともう少しだったのですが、実際はもう1アイデアを閃かないと到達できないほどのスコア差がありました。kaggle masterになるのが難しいことを一層実感したコンペでした。
このコンペに関するチームメイトの記事です。
Freesound Audio Tagging 2019
コンペのページ:https://www.kaggle.com/c/freesound-audio-tagging-2019
自分のコード:https://github.com/hakubishin3/kaggle_freesound2019
音声データに対して、80種類のカテゴリのタグ付けを行うマルチラベル分類のタスクです。正しいタグ付けがされたデータ(clean data)に加えて、誤ったラベルが付与された大量の音声データ(noisy data)が配布されており、数は多いがノイズも多いnoisy dataをどう使うかが鍵となるコンペでした。
音声データ分類の主流なやり方はスペクトログラムに変換してから処理することだったので、実質的には画像を扱うコンペでした。このコンペでもkagglerの方々とチームを組み、議論の相手になってもらったり一部のコーディングを担当してもらったりと大変お世話になりました。
このコンペの順位は880チーム中23位で銀メダルでした。この頃、同時期にkaggleを始めた人たちがゾロゾロとkaggle masterに昇格していき、焦りを覚え始めました。
Instant Gratification
コンペのページ:https://www.kaggle.com/c/instant-gratification
自分のコード:https://github.com/hakubishin3/kaggle_Instant_Gratification
謎の二値分類コンペです。カラム名がSantanderコンペのように匿名であり、データの意味が読み取れないコンペでした。
コンペ終了まで残り1週間というタイミングで、知り合いのkaggler2人を誘って参加しました。参加したタイミングでは、既に他のコンペ参加者によってデータ生成用の関数(scikit-learnのmake_classification)はほぼ特定されていて、openなdiscussionの場で共有されていました。最初はその関数の実装を読んでデータ生成過程を把握し、シミュレーション結果と実際のデータの傾向を比較しながら関数のパラメータ値の候補を絞り込んでいきました。大よそのデータの傾向が掴めたら、それをうまく分類できるようなモデル構成を検討していきました。
このコンペはデータの理解が肝だったので、コーディングよりも議論することに力を入れました。slack上でのコメントのやり取りだけでなく、ipadでポンチ絵を書いてそれを共有して議論のタネにするなど、互いのアイデアを十二分に共有して検討し尽くすことができました。
最終順位は1,832チーム中64位で銀メダルでした。暫定順位で70位ぐらいまではほぼ完璧な予測ができていて、主な差異はノイズ成分をうまく予測できているかどうかでした。ただノイズを予測するのは無理なので、上位層はほぼ運ゲーで最終順位が決まっていました。金メダルを取るには運も必要だということを学びました。
atma cup #1
コンペのページ:https://atma.connpass.com/event/138332/
こちらはkaggleのコンペではなく、atma株式会社が主催しているオンサイトコンペです。kaggle masterの方がコンペの問題設計とwebアプリの実装をされており、コンペのクオリティが高いです。
私は第1回のatma cupに参加しました。1日だけのオンサイトコンペだと問題に取り組む時間がかなり短いため、事前にモデルのパイプラインを作ってから挑みました。そのおかげでコンペ当日はデータの理解や前処理に注力することができ、32チーム中2位の成績を取ることができました。第2回のatma cupも参加する予定で、次こそは1位を取れるよう頑張りたいと思っています。
atma cupの記事です。
IEEE-CIS Fraud Detection
コンペのページ:https://www.kaggle.com/c/ieee-fraud-detection
自分のコード:https://github.com/hakubishin3/kaggle_ieee
クレジットカードのオンライン決済の履歴から、取引が不正か否かを判別するコンペです。
一般的には、クレジットカードの使用がこれまでの使用傾向と異なると不正と疑われやすくなります。なのでユーザー毎の行動をうまくモデル化して不正検出するロジックを構築するべきなのですが、このコンペのデータにはユーザーを特定する情報は一切与えられませんでした。逆にユーザーIDが与えられない状況下で、ユーザーIDを高精度に推定してそれを元に特徴量作れば大きな差異になり得ます。
今回のコンペでは、最初からチームを組んで参加しました。モデルが多様であるほどアンサンブルの効果が大きくなるので、「データに関する情報は必ずシェアするが、特徴量やモデリングに関する情報はシェアしない」というルールをチームで設定しました。ユーザーIDを特定する人、モデリングする人とうまく役割分担でき、かつルールを全員遵守したおかげで各自のモデルの差別化ができ、アンサンブルで大きく順位が伸びました。
チームメイトによるユーザーIDの特定ロジックと各自持ち寄った高精度なモデルのおかげで、最終順位は6,381チーム中5位と金メダルを取得することができました。このコンペでKaggle Masterの昇格条件(金メダル1枚、銀メダル2枚)を達成したため、Kaggle Masterになることができました。
私たちのチームのソリューションです。
Kaggleで何を得られたか
これまでデータ分析コンペをオンラインゲームに参加しているような感覚で取り組んできたのですが、結果的に自分の分析周りのスキルを向上させることができました。純粋に趣味として楽しい上に仕事に役立つのでお得な趣味だなと思っています。以下にKaggleで得られたものを挙げています。
コーディング力
コンペ中はひたすら実験を繰り返して特徴量の探索を行うので、コードを書く機会が増えました。特にpandasを多用するため、python初学者が苦手とするpandas芸にだいぶ慣れてきました。
またコンペを行う毎にコード資源が増えていくため、業務でのモデリングはコピペで済ませることが多くなり、業務の大幅な時間短縮ができています。
分析設計
コンペ毎に多様な評価指標を扱うため、実務で評価指標の設計を行う上で力になっています。
前職でも現職でも、〇〇という問題を解決するためにどのようなデータを用意すれば良いだろうかという業務上の相談をよく受けます。どのようなデータ・特徴が有用か判断する力が付いてきたので、このようなデータ設計に関しても対応できるようになりました。
キャリア(データサイエンティストとしての実績)
会社では、モデリングスキルの高いデータサイエンティストとして、信頼を寄せてもらっています。
転職活動においても、Kaggleでの実績はデータサイエンティストとしての能力をアピールできるものでした。データ分析の仕事ではモデリングはメインの業務という訳ではなく、Kaggleで証明できる能力は実務の一部分に過ぎませんが、それでも転職の時は良く評価してもらえたと思います。
最後に
Kaggleの活動は一区切りつきましたが、次はGrandMasterを目指していきたいと思います。また今まではKaggle優先にしていて参加しなかったSignateなどの分析コンペにもチャレンジしていきたいです。
Wantedlyで働き始めて2ヶ月目になりますが、すっかり環境に慣れました。Kaggleで培ったスキルを活かして仕事のパフォーマンスを最大限発揮できるよう、これからも全力で取り組んでいきます。
Wantedly, Inc.では一緒に働く仲間を募集しています