Fruit classification(10 Class)
10 Class : Apple,Kiwi,Banana,Cherry,Orange,Mango,Avocado,Pinenapple,Strawberries
https://www.kaggle.com/datasets/karimabdulnabi/fruit-classification10-class?resource=download
プログラミング初心者が初めて一人で作ったフルーツ分類AIについて記事を書いていこうと思います。
まず、なぜ初めてのAI開発でフルーツ分類を作ったかと言うと、初めてAIを作るならいきなり難易度の高いものじゃなくて簡単なものから作っていこうと思ったからです。
とはいえ、フルーツ分類も決して簡単ではありませんでした。この記事では自分が苦労したことも書いていこうと思います。
はじめに、以下は画像データに正解となるラベルを紐付けしてtransformsを使って画像データの中心を128×128にクロップ、グレースケールにして、最後にテンソル化しているコードです。ラベルもテンソル化しています。ちなみに学習用画像データは2292枚、テスト用画像データは1020枚用意しました。
画像データはこちらを使用しました。↓
class FruitDataset(Dataset):
def __init__(self, directory, transform):
self.directory = directory
self.image_and_label = self.image()
self.transform = transform
def image(self):
image_and_label = []
for folder in os.listdir(self.directory):
folder_path = os.path.join(self.directory, folder)
if os.path.isdir(folder_path):
for file in os.listdir(folder_path):
file_path = os.path.join(folder_path, file)
if os.path.isfile(file_path) and file.lower().endswith(('.jpg', '.jpeg', '.png', '.bmp', '.tiff')):
image_and_label.append((file_path, folder))
return image_and_label
def __len__(self):
return len(self.image_and_label)
def __getitem__(self, index):
images, labels = self.image_and_label[index]
image = Image.open(images)
dir_names = [d.name for d in os.scandir(self.directory)]
dir_names.sort()
dir_to_index = {dir_name: i for i, dir_name in enumerate(dir_names)}
label = dir_to_index[labels]
label_tensor = torch.tensor(label)
if self.transform:
image = self.transform(image)
return image, label_tensor
transform = transforms.Compose([transforms.CenterCrop(128), transforms.Grayscale(1), transforms.ToTensor()])
train_directory = './drive/MyDrive/DeepLearning/fruit/train'
test_directory = './drive/MyDrive/DeepLearning/fruit/test'
train_dataset = FruitDataset(train_directory, transform)
test_dataset = FruitDataset(test_directory, transform)
print(train_dataset[0])
print(len(train_dataset))
print(test_dataset[0])
print(len(test_dataset))次はネットワークの部分です。今回は畳み込みを使いました。それとReLU関数とバッチノーマライゼーションも使い、最後には全結合を入れています。
バッチサイズ(Batch_Size)
バッチサイズとは複数のデータをランダムに数個選んで一つのまとまりにすることです。例えば1000枚の画像データがあったとします。この1000枚の画像をランダムに100枚選んで一つの袋に入れる、というようなイメージです。この場合だと100枚の画像が入った袋が10個出来ることになります。もし間違えていたらすみません💦
バッチノーマライゼーションは自分でも完璧に理解しているわけではないのでこちら参考になるサイトを載せておきます。↓
#損失関数
criterion = nn.CrossEntropyLoss().to(device)
#データローダー
train_dataloader = DataLoader(train_dataset, batch_size=500, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=100, shuffle=True)
class FruitNet(nn.Module):
def __init__(self):
super(FruitNet, self).__init__()
self.cnn = nn.Sequential(
nn.Conv2d(1, 16, 4, 2, 1),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(16, 32, 4, 2, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 64, 4, 2, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 128, 3, 1, 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.lin = nn.Sequential(
nn.Linear(8*8*256, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.cnn(x)
x = x.view(-1, 8*8*256)
x = self.lin(x)
return x
net = FruitNet().to(device)
print(net)
print(summary(net, (1, 128, 128)))次は学習させるコードです。最適化関数にはAdamを使用しています。学習は30エポック回しました。
エポック(Epoch)
エポックとは ↑ のバッチサイズの説明で出来た10個の袋を一つずつ学習させていくことです。例えば30エポックと指定すると10個ある袋を一から順に学習させていく、これを30回繰り返し行うという感じです。もし間違えていたらすみません💦
loss_list = []
test_loss_list = []
acc_list = []
base_epoch = 0
optimizer = optim.Adam(params=net.parameters(), lr=0.001)
for epoch in range(30):
net.train()
total_loss = 0
for data in train_dataloader:
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs.to(device))
loss = criterion(outputs, labels.to(device))
loss.backward()
optimizer.step()
total_loss += loss.item()
loss_list.append(total_loss/len(train_dataset))
correct = 0
total = 0
total_test_loss = 0
net.eval()
for data in test_dataloader:
inputs, labels = data
outputs = net(inputs.to(device))
test_loss = criterion(outputs, labels.to(device))
total_test_loss += test_loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels.to(device)).sum()
test_loss_list.append(total_test_loss/total)
acc_list.append(float(correct)/total)
print('{}epoch : train_loss:{}, test_loss:{}, test_acc:{}'.format(
base_epoch + epoch + 1,
total_loss/len(train_dataset),
total_test_loss/len(test_dataset),
float(correct)/total
))
base_epoch += epoch + 130エポックの学習が終了したときはこんな感じです。
30epoch : train_loss:0.0018801787982181627, test_loss:0.006622125153188352, test_acc:0.3990740740740741精度は大体39%くらいですね、精度が悪すぎてビックリしましたww
学習状況をグラフで可視化してみました。↓
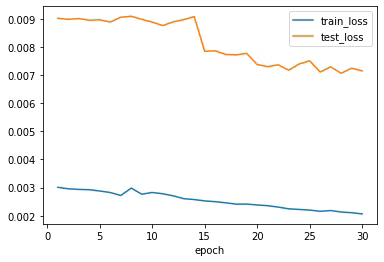
以下はグラフで可視化させるコードです。
plt.figure()
plt.plot(range(1, len(loss_list)+1), loss_list, label='train_loss')
plt.plot(range(1, len(test_loss_list)+1), test_loss_list, label='test_loss')
plt.xlabel('epoch')
plt.legend()
plt.show()試しにAIが出した答えの正解データと不正解データを見てみました。

以下は画像とAIが出した答えを表示させるコードです。
test_iter = iter(test_dataloader)
true_list = []
false_list = []
inputs, labels = next(test_iter)
outputs = net(Variable(inputs.cuda()))
_, predicted = torch.max(outputs.data, 1)
for idx in range(len(labels)):
list = [inputs[idx], labels[idx], predicted[idx]]
if int(labels[idx]) == int(predicted[idx]):
true_list.append(list)
else:
false_list.append(list)
print('正解データ')
for idx, tlst in enumerate(true_list[:5]):
plt.figure(idx+1)
plt.imshow(tlst[0].numpy().reshape(128, 128))
plt.title('correct: {}, predict: {}'.format(tlst[1], tlst[2]))
print('不正解データ')
for idx, flst in enumerate(false_list[:5]):
plt.figure(idx+1)
plt.imshow(flst[0].numpy().reshape(128, 128))
plt.title('correct: {}, predict: {}'.format(flst[1], flst[2]))本来、この画像の正解は「りんご」なのですがAIが出した答えは「さくらんぼ」となっていますね。これは不正解データとして表示されました。そして正解データは無かったので表示されませんでした。
30エポックが少なすぎたのか、それとも画像データが少なすぎたのか分かりませんが、とりあえず学習用画像データとテスト用画像データ、それぞれ100枚ずつ増やし、エポックも35にして再度学習させてみました。ついでに全結合層を一つ増やしてみました。(画像データ2292枚→2392枚、テストデータ1020枚→1120枚)
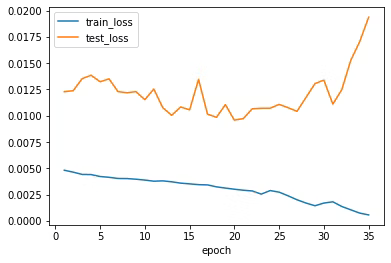
再度学習させたらこんな感じになりました。
35epoch : train_loss:0.0005585353285771947, test_loss:0.019372557742255075, test_acc:0.41160714285714284精度は大体41%くらいになりました。さっきよりほんの少しだけ良くなりましたが全然まだまだですね。
学習状況をグラフで可視化してみました。↓
AIが出した答えの正解データと不正解データを見てみるとこんな感じになりました。

この画像の正解は「オレンジ」なのですがAIが出した答えは「マンゴー」となっていますね。これも不正解データとして表示されて正解データはありませんでした。全然駄目ですねww まだまだ改良の余地がありそうです。
フルーツ分類AIを作るには約二週間くらいかかりました。そのなかで苦労したことは以下の二つです。
普通は画像データの名前とラベルが対になったCSVファイルを作成して読み込むということをするらしいのですが、めんどくさかったのでcsvファイルは作成せず、直接画像データにラベルを紐付けました。しかし紐付けたラベルは数字ではなく、フルーツの名前だったのでこれを数字にするのにかなり苦戦しました。これを辞書型を使って画像データとラベルを紐付けることが出来ました。({ A : B } ← 辞書型とはこれのことです。)
ラベルはどうやらテンソル化にしないといけないらしいです。これを「torch.tensor(label)」と書くことでラベルをテンソル化することが出来ました。
参考にさせていただいたサイトはこちらになります。↓
今回、初めてAIを作ってみましたが、ほとんどエラー修正で時間を取られました。AIだけでなくアプリやシステムを作るときもエラーはつきものなんだなと改めて実感しました。今後は作ったAIの精度向上を目指したり、フルーツ分類AIでは使いませんでしたが事前学習モデルを使って新しいAIを作ってみようと思います。
余談なんですがエラー修正の時にChatGPTを使ってみたんですが「このコードが間違っていて、コードをこういう風にしたら直りますよ」みたいな感じで教えてくれてめちゃくちゃ便利でした。
![]()