
東京
中途
海外進出している
株式会社アイリッジのメンバー
慶應義塾大学 経済学部 卒業。NTTデータにて、情報システムを利用した新規事業開発、情報システム営業などに従事
ボストン・コンサルティング・グループにて、経営戦略コンサルティング業務に従事 。インターネットサービス、金融、商社等の業界に対する、新規事業戦略、全社戦略、事業戦略、マーケティング戦略、営業力強化戦略、 人材マネジメント戦略などについて、戦略策定支援及びクライアント企業との協業での実行支援などを行う 。グロービスマネジメントスクール講師(現在に至る)
2008年8月、株式会社アイリッジを創業し、代表取締役に就任(現在に至る)
なにをやっているのか
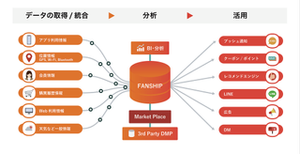
オンラインとオフラインのデータを繋ぎ、顧客一人ひとりを理解した最適なコミュニケーションを実現するサービス。アイリッジのO2Oマーケティング支援は、 自社O2Oソリューション「FANSHIP」や「FANSHIP」を組み込んだアプリを通じて 消費者に情報配信し、実店舗への集客や販売を促進します
【数々の有名企業が導入!O2O/OMOソリューションの国内最大級プラットフォームpopinfo改めFANSHIP】
2020年3月現在、1億9千万ユーザー(※)の方に使っていただいているO2O/OMO支援の代表的ソリューションへと成長したFANSHIP。
(※)FANSHIPの入ったアプリのユーザー数合計値
その割に初めて名前を聞いた、という方も多いかもしれません。それもそのはず、FANSHIPは2019年7月にブランドリニューアルにより生まれたばかりで、その前の10年間はpopinfoという名前で活躍していました。
フィーチャーフォンの待受画面にポップアップで情報配信するサービスとして2009年に生まれ、その後スマートフォンに対応、そして後に特長となるGPS/WiFi/Bluetooth(Beacon)を活用した配信を始めさまざまな機能を拡張し、popinfoは300以上の有名アプリを支えてきました。
そんなpopinfoを、10周年を迎えたタイミングでなぜリニューアルしたのか。
これはシンプルに、サービスの機能拡張に伴って、実際の提供内容とサービス名称から受けるイメージに乖離が出てきたことが最も大きい理由です。
popinfoは今年初めに顧客データ分析プラットフォーム(CDP)機能も追加し、アプリの位置情報を元にした分析だけでなく、
自社のCRMデータ、購買履歴データなど、Webや実店舗を含むあらゆるデータを組み合わせた分析を行えるようになりました。
また、まさにブランドリニューアル当日の7月17日、分析結果からユーザーとアプリ提供企業の結び付きの強さ(ファンレベル)を判断してセグメンテーションする機能が追加されました。
今後はファンレベルに応じて、自社アプリでの施策だけでなく、LINE公式アカウントでのプッシュ通知やOne to Oneトーク等での施策も可能になります。
このように、実態はチャネルを拡張したOne to Oneマーケティングプラットフォームへと進化しているのに対し、
スマホアプリからプッシュ通知を表示(pop)して情報をお知らせ(info)するという、当初の機能をストレートにわかりやすく表現していた名称のままでは、
サービスができることや私たちの想いが正しく伝わらないのではないか、という懸念がリニューアルの発端となりました。
アイリッジがO2Oマーケティングに取り組み始めて10年。
消費行動は進化し、OMOやニューリテールと呼ばれる、チャネルを超えた最適な顧客体験が求められる時代が始まる中で、私たちは2018年より”Tech Tomorrow”という新しいミッションを掲げ、”テクノロジーを活用して、わたしたちがつくった新しいサービスで、昨日よりも便利な生活を創る。”ことを目指しています。
多くの人のスマホの中にいるFANSHIPが、昨日よりも良い顧客体験を提供出来ているか?
導入企業と顧客のフレンドシップ(FANSHIPのSHIP!)に貢献できているか?
私たち自身が導入企業の一員となって伴走し、メンバーシップ/パートナーシップを発揮できているか?
そんな視点を忘れずに、また次の10年、アイリッジのフラッグシップサービスであるFANSHIPを育てていけるのが、デジタル・フィジカルマーケティング領域の醍醐味です。
なぜやるのか

「インターネットを通じて、世の中に新しい価値を創り続けていく」アイリッジのミッションです。
【「Tech Tomorrow」を実現するために ~代表取締役社長・小田 健太郎からのメッセージ~】
これまでご紹介してきたような取り組みを通じ、新しいサービスや事業の機会創出は確実に増えていきますが、「それを支えるのは人材の力だ」と代表の小田は言います。
「我々は広い視点で言うとインターネットビジネス、いわゆるソフトウェアビジネスですから、人のアイデアとメンバーが創り出すプロダクトこそがビジネスの柱となります。ですから、新しい世界を一緒に作っていける仲間が、もっともっと必要です。マザーズに上場したといっても、まだまだベンチャーでありスタートアップ。組織も成長過程です。そんな中で急成長するビジネスを手掛けられるわけですから、一緒にビジネスを伸ばしながら、社員一人ひとりも、ともに成長していける環境をつくっていければうれしいですね」(小田)
2020年4月末現在、アイリッジには112名(単体。連結は169名)の社員が在籍。
一人ひとりの発言力が大きく、やりたいと手を挙げれば実現できる社風があることに加え、働く社員をサポートする制度にも力を入れています。
例えば、プロジェクトの勉強会にはじまり、技術やコアスキルを学べる勉強会などもいろいろな切り口で定期的に実施していたり、小田が経営の考え方やスタンスを伝える『小田塾』という勉強会もあります。社外の勉強会への参加や社外の方向けの勉強会開催を通じて、経験を広めたり、登壇して話す経験も積んでもらえたら、というスタンスで、今後も、学びたい意欲のある人をサポートできる環境を整えていきたいと思っています。
「これからも新しい世界・新しい体験を作っていける会社でありたいと思っています。
我々では『Tech Tomorrow』と言っているのですが、テクノロジーを活用して、昨日よりも便利な明日を作っていきたいと考えています。
新しい価値観や楽しみを提供していけたら、うれしいですね。
O2Oやフィンテック事業はもちろん、そこだけに固執するわけではなく、違った取り組みにも、積極的にチャレンジしていきたいですね」(小田)
どうやっているのか

職務、業界共に⾮常に幅広くスピーディに色々なことにチャレンジできます!

女性も多数活躍中です!
2015年7月にグロースに上場、この5年でメンバーが32名から110名以上と急拡大中の組織です。
まだまだ事業も組織も未整備な点も多く、今まで培ってきたスキルやノウハウを活かし成長できる伸びしろが大きく広がっています。
【デジタル・フィジカルマーケティング、フィンテック、ライフデザイン、3つの領域で第2創業期を迎えたアイリッジ】
「インターネットビジネスで新しい価値・体験を作っていきたい」と2008年に創業した株式会社アイリッジ。
いち早くOnline to Offline (O2O/OMO)ビジネスに着目し、小売流通・鉄道・金融など各業界のトップ企業に向けたO2O/OMOソリューション提供やO2O/OMOアプリ開発、O2O/OMOマーケティング支援で成長を続け、2015年には東証グロース上場も果たしました。
2018年8月には、社内ベンチャーとして始まったフィンテック事業を分社化したフィノバレーと、資本業務提携先であるデジタルガレージより新設分割されたDGマーケティングデザインを子会社に迎え、3社連結体制へと移行。
事業の幅を広げ、第2創業期を迎えています。
分社化したフィンテック事業はスピード感を加速し、O2O事業は店舗における販促やプロモーションに強みを持つDGマーケティングデザインと連携することで、
店舗へ送客するデジタル領域に加えフィジカル領域(店舗)でのマーケティングも支援するデジタル・フィジカルマーケティング事業へと拡張。
また、新規事業である音声アシスタント対応アプリの制作ツールや住生活向けソリューションなどを通じて、住まいや街づくりといった軸でも生活者とのタッチポイントを増やし始めています。
2019年10月からは、上場前からの開発パートナー企業であるキースミスワールドのメンバーを吸収合併により迎え、開発体制もさらに強化予定。
あらゆるシーンで企業と生活者とのエンゲージメントを高めていく「トータルエンゲージメントソリューション」を提供していくため、引き続き仲間を募集しています。
こんなことやります
サービスの運用改善に必要な業務をSRE(Site Reliability Engineering)担当として、サービスの信頼性向上のために広く携わって頂きます。
弊社では、ID数7000万を超えたpopinfoを初め様々なサービスを提供していますが、ユーザーの増加に伴ってより信頼性の高いサービス水準が求められています。これまではプロジェクトごとに解決していましたが、横断的に改善をしていく必要があると判断してチームを発足しました。
サーバ・ネットワークの構築・運用、システムの自動化や障害対応などインフラ的な業務に加えて、システムのパフォーマンスや信頼性、スケーラビリティを向上させるため開発・運用なども携わっていただきます。すでに商用環境でDockerを運用しているなど、新技術への導入にも積極的で、速度と品質のバランスが取ることができれば、積極的に挑戦できる環境です。
【具体的な業務内容】
・デプロイの効率化 (Green/Blueデプロイ等 より安全で高速なデプロイの導入)
・リソースモニタリングの高度化 (現在muninを利用していますが限界を感じています)
・アプリケーションログモニタリングの高度化 (エラーログ、操作ログなどの定量的な分析など)
・インフラの高密度化 (Docker等を活用し、インフラリソースの効率的な利用を主導する)
【開発環境】
・開発言語:Python2,3(Django) , Go
・OS:Linux
・DB:MySQL , Amazon DynamoDB
・ツール:Docker , Ansible , Datadog , Elasticsearch, fluentd, nginx
・ソースコード管理:Git , GitLab
・コミュニケーション:Slack
・インフラ:AWS(EC2,RDS,S3,API Gateway,Lambda)
・支給マシン:予算の範囲で好きなものをご用意いたします。
【開発手法/開発物】
・Git と GitLab (GitHubクローン) によるPullRequestベースの開発手法を取っています。
・開発速度と品質のバランスが取ることができれば、新しい技術にも挑戦できる風土があります。
【エンジニアチームの雰囲気】
・ワークライフバランスが取れているメンバーが多い環境です。
20名規模の組織ですが女性エンジニアが2名所属、既婚者も約10名います。
・issueを残す文化が有り、言った言わないのトラブルが無いような仕事の進め方をしています。
・適切な技術をスピード感を持って採用できる風土があります。
すでに、GoやDockerなども既に商用環境で稼働しています。
・スキルアップ支援していて、支障がなければ日中の勉強会への参加を認めています。
・社内LT会を不定期で開催したり、Kubernetes社外向け勉強会をしているメンバーなどもいます。
【必須要件】
・Webアプリケーションの開発・運用経験
・コードによるインフラ構成管理経験(例: Ansible, Chef, Docker)
・クラウドインフラを利用したインフラ構築経験(例: AWS,GCP,Azure)
【歓迎要件】
・Python、Goに対する強い興味、理解または業務のご経験
・Linuxへの深い知識
・Datadog / Sensu / NewRelic などのモニタリングプラットフォームに関する理解
・Elasticsearch / Fluentd / Kibana 等 ログの集約・視覚化基盤への理解
・MySQL / Memcached / Redis / RabbitMQ などのミドルウェアを用いた開発および運用経験
11人がこの募集を応援しています
会社の注目のストーリー
話を聞きに行くステップ
- 応募する「話を聞きに行きたい」から応募
- 会社からの返信を待つ
- 話す日程を決める
- 話を聞きに行く
募集の特徴
オンライン面談OK
会社情報
2008/08に設立
174人のメンバー
- 海外進出している/
- 3000万円以上の資金を調達済み/
- 1億円以上の資金を調達済み/
東京都港区麻布台1-11-9 BPRプレイス神谷町10階