こんにちは、ウォンテッドリーでデータサイエンティストをしている林です。先週、データサイエンティストチームでRecSysにオンラインで聴講参加しました。この記事では参加レポートとして、発表されていた論文を紹介していきます。なお、他のチームメンバーの参加レポートは下のリンクでまとめていますのでよろしければ読んでください。
ここでは私からの参加レポートとして、推薦モデルの「公平性・プライバシー」について取り上げた論文を2本紹介したいと思います。
モデルの 「公平性」と「プライバシー」 は、機械学習が社会に浸透し、多くのユーザーデータが学習に使われるようになるにともない、人々の関心を集めるようになってきた分野です。モデルの学習のために収集されたデータに限らず、世の中のデータには通常バイアスがかかっており、性別や人種と言ったものに代表されるセンシティブ情報によって、職種や年収、趣味といったものの分布に差が生じます。このようなデータを用いて学習された機械学習モデルはバイアスも含めて学習してしまうことが多く、結果としてそのモデルの出力はユーザーにとって不公平なものとなりえます。モデルの学習の際にこのようなことが起きないようにしようというのが公平性に配慮した機械学習の目標の1つとなっています。
また、センシティブ情報というのはユーザーにとっては他の人には知られたくない情報であることが多いです。そのため、モデルの学習に用いることで外部からユーザーのセンシティブ情報を知ることができるようになってしまうという事態は必ず防がなければなりません。いかにしてユーザー情報を秘匿した状態で安全にモデルの学習をするかというのが機械学習におけるプライバシー保護の課題となっています。
プライバシー問題を考慮したモデルの学習手法としては近年、 連合学習 (Federated Learing) という手法が注目を集めています。連合学習ではモデルのパラメーターをユーザーのデバイスに送ってデバイス上で学習を行い、パラメーターの更新情報のみを中央のサーバーに送ります。これによりユーザーデータはユーザー自身のデバイスから外には持ち出されることがなく、プライバシーを保護しながらモデル学習ができます。
今回ご紹介する論文は2本とも、連合学習における推薦の公平性に注目した論文になります。
Fairness-aware Federated Matrix Factorization S. Liu, Y. Ge, S. Xu, Y. Zhang and A. Marian. 2022. Fairness-aware Federated Matrix Factorization. In Sixteenth ACM Conference on Recommender Systems (RecSys ‘22), September 18-23, 2022
ユーザーをある指標のもとにいくつかのグループに分けたとき、ユーザーグループ間で受けることができる推薦を公平なものにすることは重要な問題です。しかし、ユーザーの属するグループを決める特徴量というのは、例えば性別のように、ユーザーのプライバシーに関わるものであることが多く注意して扱う必要があります。
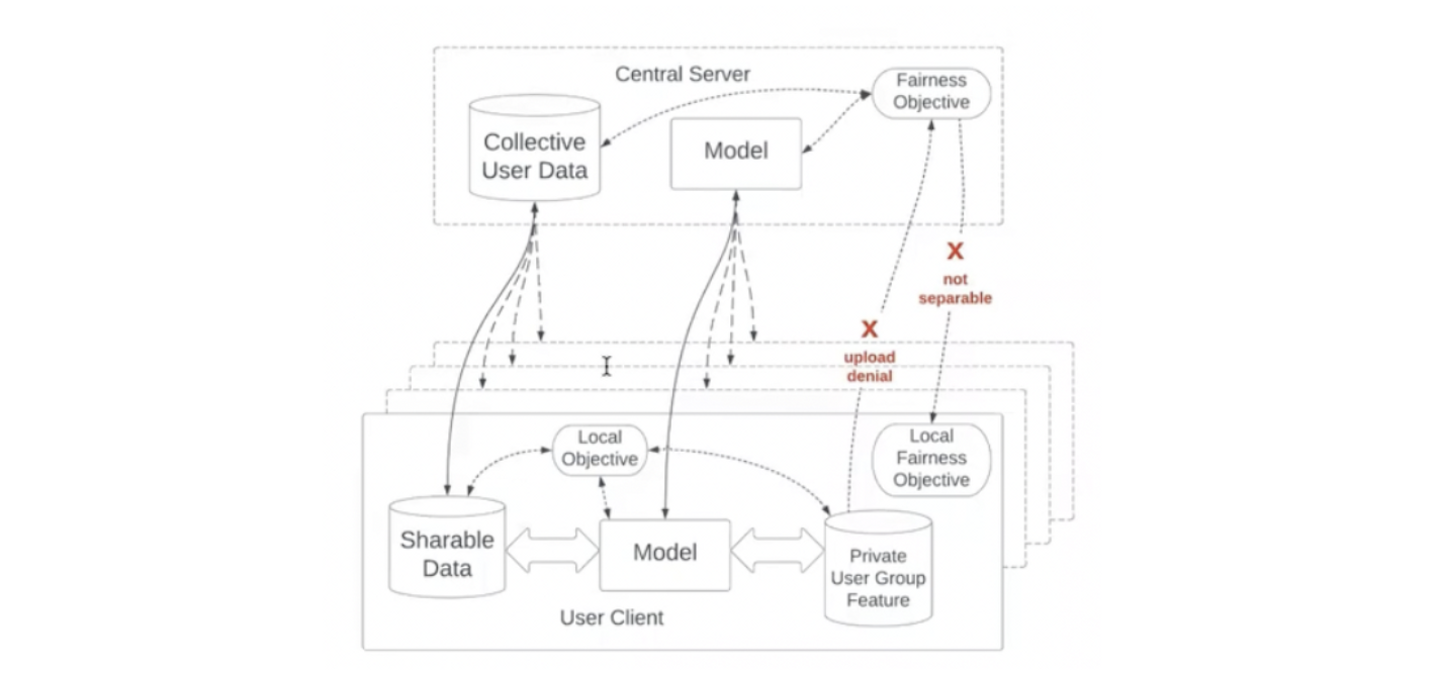
提案手法 この論文で筆者らは 連合学習を使うことでプライバシー問題に対処しつつ、推薦の公平性を実現 したという成果について発表しています。この論文の大きな基礎となっているのがFedMFというモデルです。これは連合学習 ( Fed erated Learing) と Matrix Factorization ( MF ) を組み合わせたモデルです。これはプライバシーには配慮したモデルではありますが公平性が考慮されたものではありませんでした。そもそも連合学習においてプライバシーと公平性の両方を担保するのは困難であると考えられていました。モデルが公平性を持つかどうかは異なるユーザーグループに属するユーザーに対するモデルの性能を比較することでわかります。しかし連合学習におけるプライバシーの基礎はユーザー情報を一箇所に集めず、各ユーザーのデバイス上に完結させることにあります。したがって連合学習において公平性とプライバシーは相反するものだと考えられてきました(図は発表スライドから引用)。
この問題に対して筆者らは、工夫を加えてユーザーごとに公平性を考慮して学習をすすめる方法を提案しています(下の画像は発表スライド)。まず、学習時のユーザーグループ間の性能差を、公平性を実現するために損失関数に加えます。そしてユーザーグループごとにハイパーパラメーターとしてDを割り当て、ユーザーグループごとに学習の進行速度を調整します。
このような方法で学習しようとすると上のスライドにA, Bで示されている項が問題になります。これらを計算しようとするとユーザー情報を一箇所に集める必要があるからです。
この問題に対処するために、筆者らはA, Bというユーザーの統計情報を中央のサーバーで持っておき、学習時に各ユーザーデバイスにモデルパラメーターとともに送る方法を提案しています。この方法では学習後に各ユーザーによるA, Bの勾配情報を中央のサーバーに送り返し、サーバーがA, Bの値を更新します。このとき、各ユーザーが生じさせるA, Bの勾配からユーザー情報がもれないように、ユーザーごと・エポックごとに変わる乱数をノイズとして加えます。ここで、加わるノイズは平均がゼロで、分散が共通の正規分布から生成されているので、中央のサーバーでA, Bの値を更新するときにはユーザー数が多ければ誤差が少なくなることがポイントとなっています。
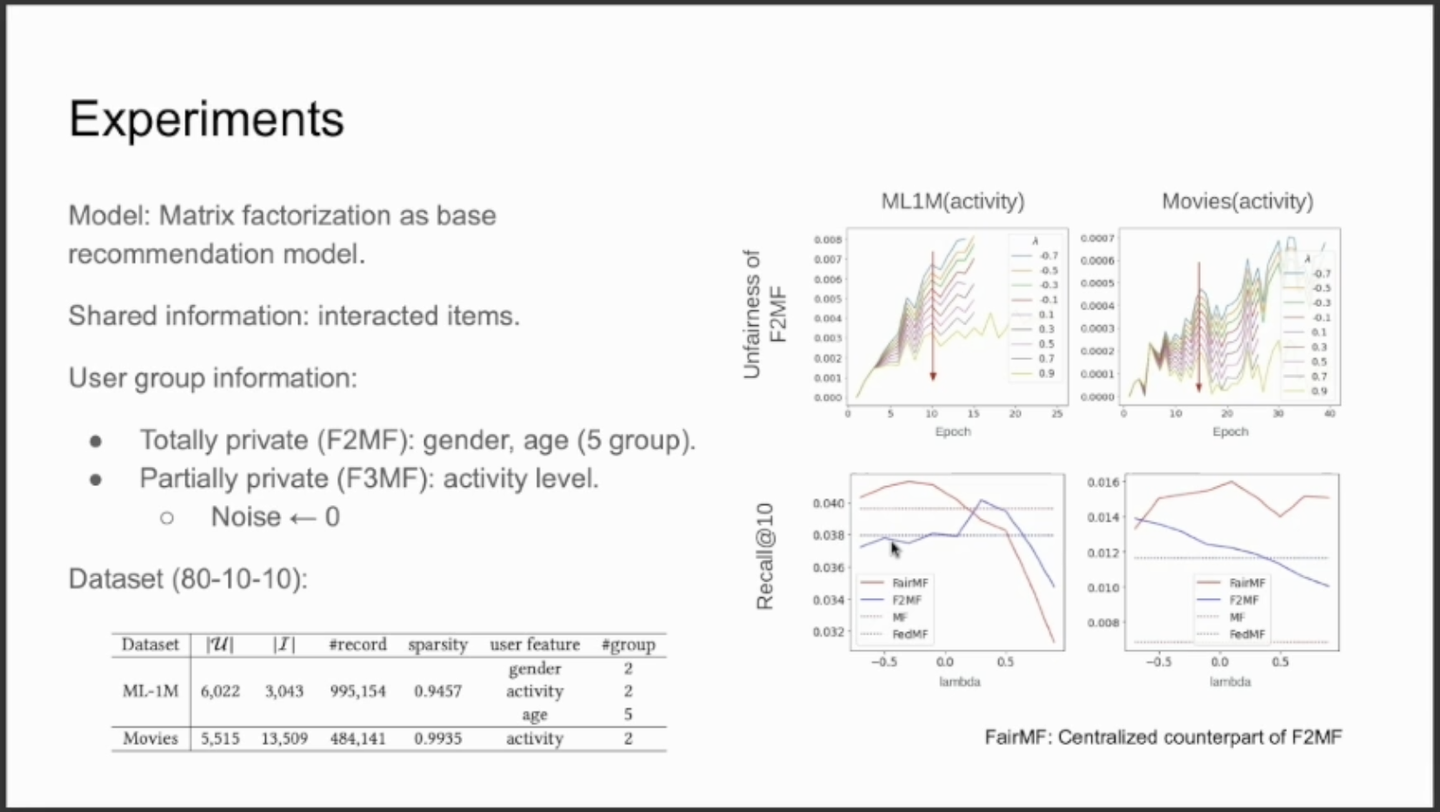
結果 公平性についての損失関数のウェイトλの大きさを変えたときのモデルの性能変化をプロットしたのが以下のスライドの右下2つのグラフです。青の実線がこの論文のモデルになります。λ = 0.3付近で最も性能がよく、一般のMF(赤の点線)と比べても同程度の性能が出ています。
また、スライドの上2つはλの値を大きくしていったときに不公平さを表す指標がエポックごとにどう変化するかを表しています。λを大きくしていくことで不公平性の大きさが抑えられている様子がよくわかります。
Towards Fair Federated Recommendation Learning: Characterizing the Inter-Dependence of System and Data Heterogeneity K. Maeng, H. Lu, L. Melis, J. Nguyen, M. Rabbat and C.-J. Wu. 2022. Towards Fair Federated Recommendation Learning: Characterizing the Inter-Dependence of System and Data Heterogeneity. In Sixteenth ACM Conference on Recommender Systems (RecSys ‘22), September 18-23, 2022
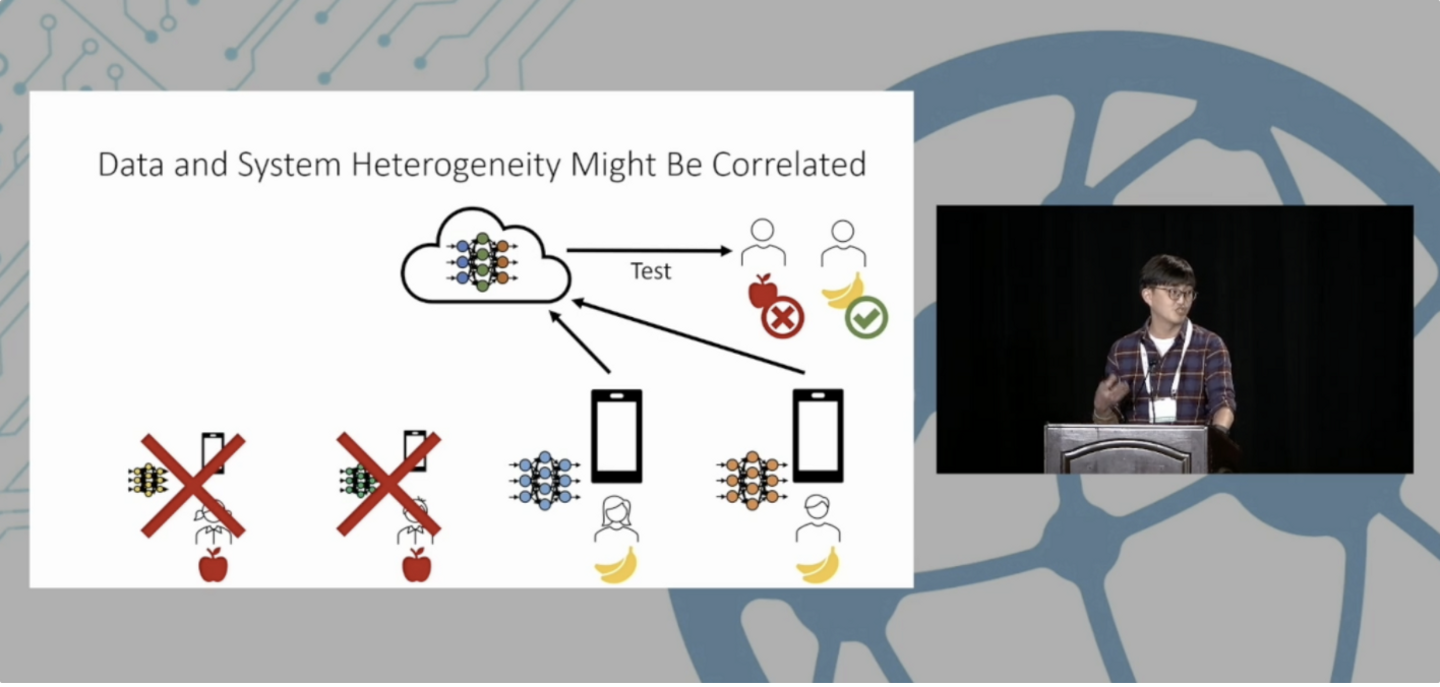
次に紹介するのは、 連合学習におけるデータの不均一性が推薦の公平性に与える影響 について調べた発表です。ここではデータの不均一性を生み出す原因として、ユーザーの持つデバイスの性能差に着目しています。ユーザーの持つデバイスの性能は様々であり、性能の高いデバイスでの学習は早く終わりますが性能の低いデバイスでの学習には時間がかかります。そのため学習が性能の低いデバイスで律速されないように、学習を行うときには様々な工夫がなされます。例えばGoogleでは性能が一定以下のデバイスは連合学習の対象外とするような運用がなされているということが発表では触れられていました。
しかし、このような手段が公平性を損なわないためには、例えばデバイスの性能によってユーザーの嗜好分布が変化しないという仮定があります。下のスライドに示されているように、性能の高いデバイスを持っているユーザーはバナナを好む傾向が強く、性能の低いデバイスを持っているユーザーはリンゴを好む傾向が強いとき、性能の高いデバイスのみで学習を行うことで性能が低いデバイスを持つユーザーにとっては不公平な推薦モデルとなってしまいます。
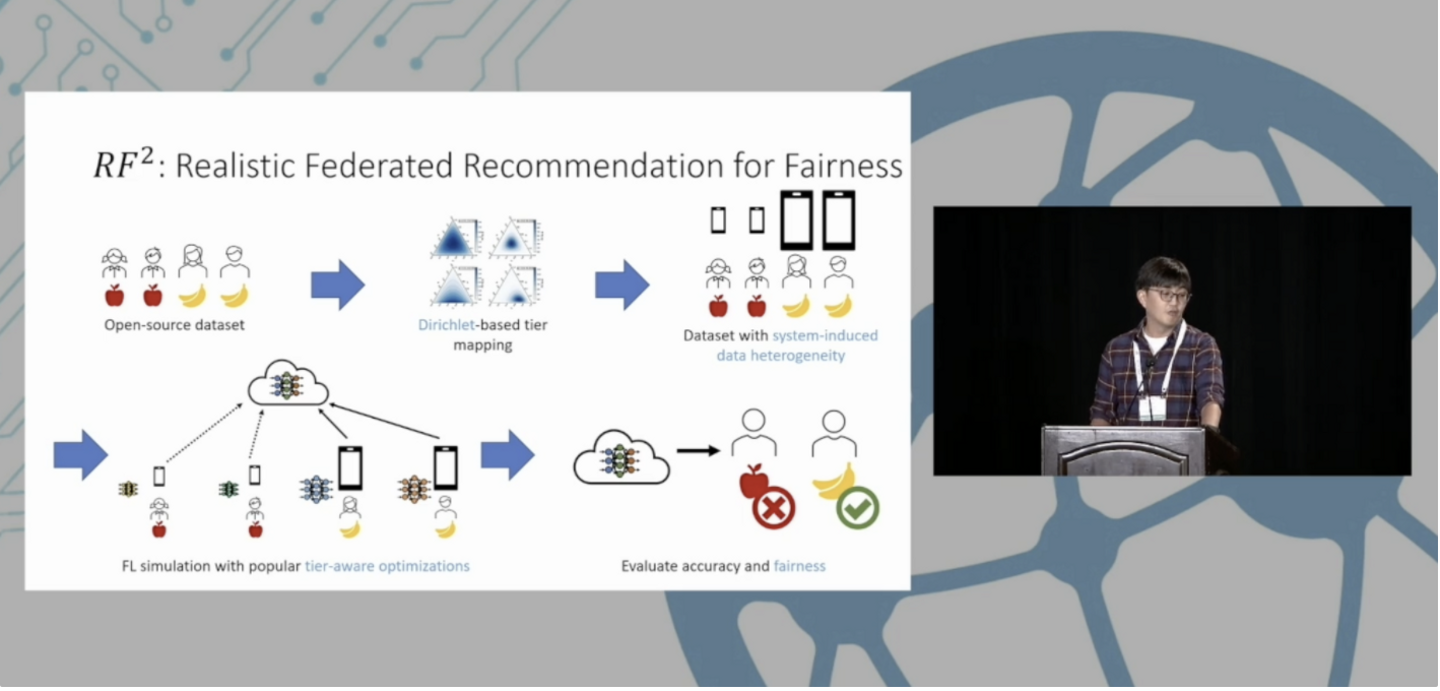
提案手法 この論文では、こうした連合学習の方法によって生じる不公平性を評価するためのフレームワークを提案しています。
筆者らが提案したフレームワークRF2では、パラメーターによってユーザーグループ間の分布の違いを調整します。そして分けたグループを使って学習を行い、不公平性をMDAC
によって評価します。βはモデルのaccuracyを表し、上付き添字はユーザーのグループ、下付き添字は最適化状態(0は最適化していない状態)を示しています。
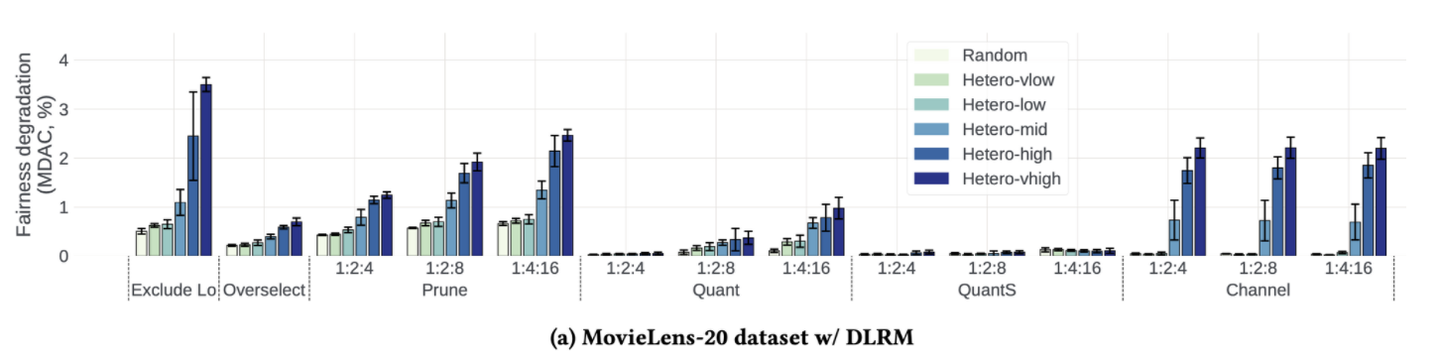
結果 各グループに分けたユーザーに対してどのような学習を行うかを変えたときのMDACの大きさは、データの不均一性を大きくしていくとそれに伴って同様に大きくなっていく振る舞いが観測されています(下図は論文から引用)。
“Exclude Lo” はlowグループ(性能の低いデバイスを持つユーザーのグループ)に属するユーザーを一切学習に使わなかった場合です。グループ間の分布の差が大きいときにはモデルの不公平性が非常に大きくなっています。一方で “QuantS” ではグループ間の分布の差が大きくなってもモデルの不公平性が小さいままであることがわかります。QuantSはモデルの勾配を符号も含めて量子化する方法で、 1:2:4の場合には Low: Mid: High = 8 bit: 16 bit: 32 bitで量子化することを示しています。
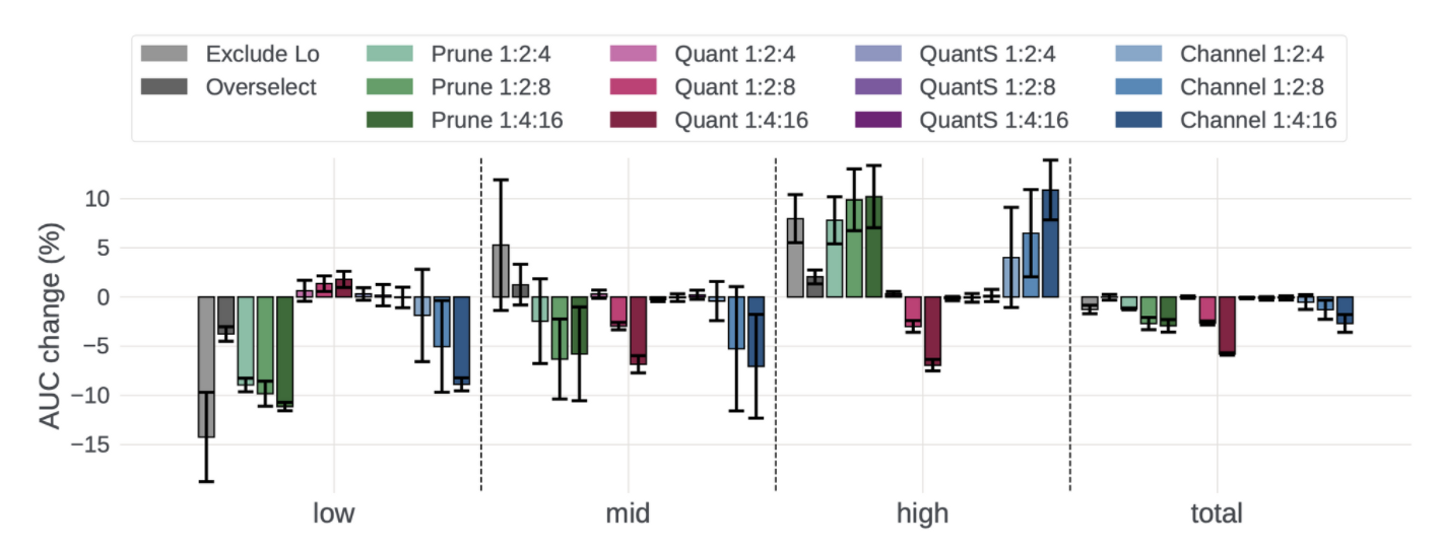
下は各手法でモデルの性能がどう変化するかを示したものです。
量子化する手法ではlowグループの性能劣化がかなり抑えられている一方で、ユーザー全体で見ると性能劣化が大きいことがわかります。一方で “Exclude Lo”では Lowグループでの性能劣化が激しい一方で全体で見たときの性能劣化はかなり抑えられています。このように公平性とモデルの性能はトレードオフの関係にあり、RF2フレームワークを使うことによってこれらを調べることができます。
まとめ ここまで、連合学習における推薦モデルの公平性とプライバシーについての発表について紹介してきました。私はこれまで機械学習の論文を探すときに提案されたモデルの「性能」に注目することが多く、公平性などの議論はEU圏内で議論や法整備が進んでるなくらいの認識しか持っていませんでした。しかし今回RecSysで発表を聞いたことでこの分野の世界的な注目が高くなっていることを肌で感じることができました。さらに、この分野が今後、様々なプロダクトにとってユーザーの体験を向上させるために必要なことなのだということも実感することができました。
この記事に興味を持っていただけたら是非「話を聞きに行きたい」ボタンを押してお話できたら嬉しいです。最後まで読んでいただきありがとうございました。
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)



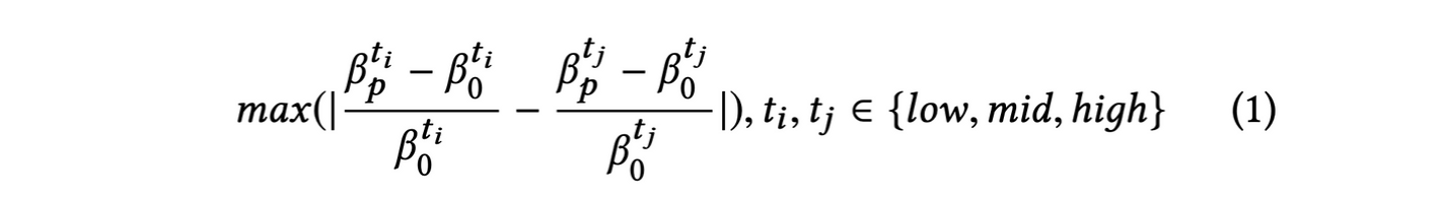
/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)


/assets/images/7052304/original/49100b17-5866-4cec-b50b-a37ea73565e9?1638782149)
/assets/images/7053725/original/28d1b135-13b4-4f46-895f-d5f5fb5ae243?1624246858)
